1_Elasticsearch 分布式搜索
Elasticsearch介绍_全文检索索引
Elasticsearch介绍_倒排索引
Elasticsearch介绍_Elasticsearch的出现
Elasticsearch介绍_Elasticsearch应用场景
Elasticsearch介绍_Elasticsearch对比Solr
Elasticsearch介绍_Elasticsearch数据结构
Elasticsearch安装_安装ES服务
Elasticsearch安装_安装kibana
Elasticsearch常用操作_索引操作(1)
Elasticsearch常用操作_索引操作(2)
Elasticsearch常用操作_文档操作(1)
Elasticsearch常用操作_文档操作(2)
Elasticsearch常用操作_域的属性_index
Elasticsearch常用操作_域的属性_type
Elasticsearch常用操作_域的属性_store
分词器_默认分词器
分词器_IK分词器安装
分词器_IK分词器词典
分词器_拼音分词器
分词器_自定义分词器
Elasticsearch搜索文档_准备工作
Elasticsearch搜索文档_搜索方式(1)
Elasticsearch搜索文档_搜索方式(2)
Elasticsearch搜索文档_复合搜索
Elasticsearch搜索文档_结果排序
Elasticsearch搜索文档_分页查询
Elasticsearch搜索文档_高亮查询
Elasticsearch搜索文档_SQL查询
原生JAVA操作ES_搭建项目
原生JAVA操作ES_索引操作(1)
原生JAVA操作ES_索引操作(2)
原生JAVA操作ES_文档操作(1)
原生JAVA操作ES_文档操作(2)
原生JAVA操作ES_搜索操作
Elasticsearch集群_概念
Elasticsearch集群_安装节点一
Elasticsearch集群_安装剩余节点
Elasticsearch集群_配置kibana
Elasticsearch集群_测试集群状态
Elasticsearch集群_故障应对、水平扩容
Elasticsearch优化_内存设置
Elasticsearch优化_磁盘选择
Elasticsearch优化_分片策略
2_Redis从入门到实战
Redis概述_为什么要使用NoSQL
Redis概述_什么是NoSQL
Redis概述_当下NoSQL经典应用
Redis概述_什么是Redis
Redis安装_Linux下安装Redis
Redis安装_基础知识
Redis数据类型_key键
Redis数据类型_String
Redis数据类型_List
Redis数据类型_Set
Redis数据类型_Hash
Redis数据类型_Zset
Redis数据类型_Bitmaps
Redis数据类型_Geospatia
Redis数据类型_HyperLogLog
Redis可视化工具_Redis_Destktop_Manager
Java整合Redis_Jedis操作(上)
Java整合Redis_Jedis操作(下)
Redis配置文件
Redis其他功能_发布订阅
Redis其他功能_慢查询
Redis其他功能_流水线pipeline
Redis数据安全_持久化机制概述
Redis数据安全_RDB持久化机制
Redis数据安全_AOF持久化机制
Redis数据安全_企业中改如何选择持久化机制
Redis集群_主从复制概念
Redis集群_主从复制搭建
Redis集群_主从复制原理刨析
Redis集群_哨兵监控概述
Redis集群_配置哨兵监控
Redis集群_哨兵监控原理刨析
Redis集群_哨兵监控故障转移监控
Redis集群_Cluster模式概述
Redis集群_Cluster模式搭建
Redis集群_Cluser模式原理
Redis企业级解决方案_Redis脑裂
Redis企业级解决方案_缓存预热
Redis企业级解决方案_缓存穿透
Redis企业解决方案_缓存击穿
Redis企业解决方案_缓存雪崩
Redis企业级解决方案_Redis开发规范
3_电商大数据
建表一
建表二
导入数据到表中
查询用户的总个数
查询购物记录的总条数
查询卖家的总数量
查询热卖商品前10名
查询热卖品牌前10名
查询购买商品数量最多的前50名用户
分析不同时间消费的趋势
查询回购率排名前10的品牌
分析网购行为与性别关系
分析网购行为与年龄关系
分析每个品牌的销量前3名的商品
4_概述
概述_什么是Spark?
概述_Spark主要功能
概述_Spark与Hadoop
概述_Spark技术栈
概述_PySpark Vs Spark
5_运行模式
运行模式_概述
运行模式_WordCount一
运行模式_WordCount二
运行模式_Local模式安装
运行模式_Local模式WebUI
运行模式_Spark目录介绍
运行模式_SparkPi源码解析
运行模式_spark-submit
运行模式_Standalone架构分析
运行模式_Standalone模式安装一
运行模式_Standalone模式安装二
运行模式_Standalone启动测试
运行模式_Standalone执行任务
运行模式_查看历史日志WebUI
运行模式_StandaloneHA安装
运行模式_StandaloneHA测试
运行模式_Yarn模式概述
运行模式_Yarn模式安装
运行模式_Yarn Client
运行模式_Yarn Cluster
运行模式_spark-submit参数
6_RDD
RDD_为什么需要RDD
RDD_定义
RDD_五大特性总述
RDD_五大特性1
RDD_五大特性2
RDD_五大特性3
RDD_五大特性4
RDD_五大特性5
RDD_五大特性总结
RDD_创建概述
RDD_并行化创建
RDD_读取文件创建RDD
RDD_读取小文件创建RDD
RDD_算子概述
RDD_转换算子map
RDD_转换算子flatMap
RDD_转换算子reduceByKey
RDD_转换算子filter
RDD_转换算子distinct
RDD_转换算子glom
RDD_转换算子groupBy
RDD_转换算子groupByKey
RDD_转换算子sortBy
RDD_转换算子sortByKey
RDD_转换算子union并集
RDD_转换算子交集和差集
RDD_转换算子关联算子
RDD_转换算子partitionBy
RDD_转换算子mapPartitions
RDD_转换算子sample
RDD_行动算子foreachPartition
RDD_行动算子foreach
RDD_行动算子saveAsTextFile
RDD_行动算子countByKey
RDD_行动算子reduce
RDD_行动算子fold
RDD_行动算子first_take_count
RDD_行动算子top_takeOrdered
RDD_行动算子takeSample
7_内核进阶
内核进阶_DAG概述
内核进阶_血缘关系
内核进阶_宽窄依赖关系
内核进阶_Stage划分
内核进阶_任务调度概述
内核进阶_管道计算模式上
内核进阶_管道计算模式下
内核进阶_Cache缓存
内核进阶_CheckPoint检查点
内核进阶_Cache和CheckPoint区别
内核进阶_并行度
内核进阶_广播变量
内核进阶_累加器一
内核进阶_累加器二
内核进阶_累加器之重复计算
内核进阶_项目实战PVUV需求分析
内核进阶_项目实战PV分析
内核进阶_项目实战UV分析
内核进阶_二次排序实战
内核进阶_分组取topN实战
内核进阶_卡口统计项目需求分析
内核进阶_卡口统计项目统计正常的卡口
内核进阶_卡口统计项目Top5
内核进阶_卡口统计项目统计不同区域同时出现的车辆
内核进阶_卡口统计项目统计某卡口下通过的车辆轨迹一
内核进阶_卡口统计项目统计某卡口下通过的车辆轨迹二
内核进阶_卡口统计项目统计某卡口下通过的车辆轨迹三
内核进阶_卡口统计项目统计某卡口下通过的车辆轨迹四
8_SparkSQL
SparkSQL_简介
SparkSQL_发展史
SparkSQL_与Hive区别
SparkSQL_SparkSession
SparkSQL_数据抽象
SparkSQL_DataFrame概述
SparkSQL_DataSet概述
SparkSQL_DataFrame构成
SparkSQL_创建项目
SparkSQL_createDataFrame创建DF
SparkSQL_toDF创建DF
SparkSQL_toDF使用样例类创建DF
SparkSQL_DataFrame转换RDD
SparkSQL_创建DataSet
SparkSQL_DataSet和RDD转换
SparkSQL_DataSet和DataFrame转换
SparkSQL_读写parquet文件
SparkSQL_读写parquet文件扩展
SparkSQL_读写text文件
SparkSQL_读写json文件
SparkSQL_读写csv文件
SparkSQL_JDBC读MySQL
SparkSQL_JDBC写MySQL
SparkSQL_SparkOnHive概述
SparkSQL_SparkOnHive配置
SparkSQL_SparkOnHive代码开发一
SparkSQL_SparkOnHive代码开发二
SparkSQL_SparkOnHive代码集群提交
SparkSQL_DSL API
SparkSQL_数据去重
SparkSQL_functions包
SparkSQL_SQL API
SparkSQL_SQL API实战
SparkSQL_自定义函数概述
SparkSQL_自定义UDF函数
SparkSQL_自定义UDF函数扩展
SparkSQL_ArrayType返回值类型的UDF
SparkSQL_UDAF函数Old一
SparkSQL_UDAF函数Old二
SparkSQL_UDAF函数Old三
SparkSQL_UDAF函数Old四
SparkSQL_UDAF函数New一
SparkSQL_UDAF函数New二
SparkSQL_UDAF函数New三
SparkSQL_开窗函数概述
SparkSQL_开窗函数实战
SparkSQL实战_找出变化的行一
SparkSQL实战_找出变化的行二
SparkSQL实战_函数转换Json数据
SparkSQL实战_读取嵌套的Json
SparkSQL实战_解析JsonArray数据
SparkSQL实战_行列转换一
SparkSQL实战_行列转换二
SparkSQL实战_行列转换三
SparkSQL实战_行列转换四
SparkSQL实战_用户7日留存分析一
SparkSQL实战_用户7日留存分析二
SparkSQL实战_用户7日留存分析三
SparkSQL实战_统计访问总时长一
SparkSQL实战_统计访问总时长二
SparkSQL实战_用户在线分析_需求分析
SparkSQL实战_用户在线分析_错位关联
SparkSQL实战_用户在线分析_数据补全和过滤
SparkSQL实战_用户在线分析_总时长_次数_最大时长
SparkSQL实战_用户在线分析_每小时在线人数一
SparkSQL实战_用户在线分析_每小时在线人数二
SparkSQL实战_用户在线分析_每小时在线人数三
SparkSQL实战_用户在线分析_每小时在线人数四
9_SparkStreaming
SparkStreaming概述
SparkStreaming_架构
SparkStreaming_创建项目
SparkStreaming_WordCount
SparkStreaming_数据抽象
SparkStreaming_RDD队列创建DStream
SparkStreaming_自定义数据源一
SparkStreaming_自定义数据源二
SparkStreaming_DStream无状态转换
SparkStreaming_DStream无状态转换transform
SparkStreaming_DStream有状态转换
SparkStreaming_窗口操作reduceByKeyAndWindow概述
SparkStreaming_窗口操作reduceByKeyAndWindow实战
SparkStreaming_窗口操作reduceByKeyAndWindow优化
SparkStreaming_窗口操作Window
SparkStreaming_输出
SparkStreaming_优雅关闭一
SparkStreaming_优雅关闭二
SparkStreaming_优雅关闭测试
SparkStreaming_整合Kafka模式
SparkStreaming_整合Kafka开发一
SparkStreaming_整合Kafka开发二
SparkStreaming_整合Kafka测试
10_Superset可视化系统
Superset概述
环境搭建_安装Python环境
环境搭建_安装配置Superset_time
环境搭建_启停Superset
环境搭建_Superset启停脚本.
SuperSet实战_整合MySQL数据源
SuperSet实战_操作MySQL数据库表
SuperSet实战_仪表盘操作
SuperSet实战_图表操作
11_百战出行
百战出行
百战出行架构设计
环境搭建_HBase安装部署
环境搭建_Kafka安装部署
环境搭建_MySQL安装部署
环境搭建_Redis安装部署
构建父工程项目
订单监控_收集订单数据
订单监控_订单数据分析
订单监控_存储数据之读取数据
订单监控_存储数据之保存数据至MySQL
订单监控_Maxwell介绍
订单监控_Maxwell安装
订单监控_Spark_Streaming整合Kafka_上
订单监控_Spark_Streaming整合Kafka_下
订单监控_实时统计订单总数之消费订单数据
订单监控_实时统计订单总数之构建订单解析器
订单监控_实时统计订单总数之解析订单JSON数据
订单监控_实时统计订单总数
订单监控_实时统计乘车人数统计
订单监控_Redis工具类
订单监控_保存数据到Redis中
虚拟车站_需求分析
虚拟车站_虚拟车站实现思路
虚拟车站_Uber h3介绍
虚拟车站_H3算法使用
虚拟车站_HBase工具类上
虚拟车站_HBase工具类下
虚拟车站_Kafka消费订单数据
虚拟车站_储存订单数据至HBase
虚拟车站_Spark SQL读取HBase订单数据
虚拟车站_创建订单数据的DataFrame
虚拟车站_Spark SQL集成H3
虚拟车站_虚拟车站站点统计
虚拟车站_保存虚拟车站信息
订单交易数据统计分析_数据准备
订单交易数据统计分析_kafka消费数据至HBase_上
订单交易数据统计分析_kafka消费数据至HBase_下
订单交易数据统计分析_自定义Spark SQL多数据
订单交易数据统计分析_自定义外部数据源HbaseR
订单交易数据统计分析_自定义外部数据源HbaseRel
订单交易数据统计分析_自定义外部数据源HbaseRelation
订单交易数据统计分析_订单总数统计
订单交易数据统计分析_订单月总数统计
订单交易数据统计分析_公里数统计
订单交易数据统计分析_汇总结果
订单交易数据统计分析_保存汇总数据
订单交易数据统计分析_当日各城市的车辆分布
订单交易数据统计分析_当月各城市的车辆分布
订单交易数据统计分析_汇总当日车辆和当月车辆
订单交易数据统计分析_当日订单分布
订单交易数据统计分析_当月订单分布
订单交易数据统计分析_汇总日、月订单分布
订单交易数据统计分析_车辆分布和订单分布的汇总
订单交易数据统计分析_保存车辆分布和订单分布的汇总结果
司机数据统计分析_数据准备
司机数据统计分析_kafka消费数据至HBase
司机数据统计分析_当日各城市的司机注册数
司机数据统计分析_当月各城市的司机注册数
司机数据统计分析_本年各城市的司机注册数
司机数据统计分析_汇总各城市司机注册数
司机数据统计分析_各城市司机注册数保存HBase
司机数据统计分析_当日平台有效订单总数
司机数据统计分析_当月平台有效订单总数
司机数据统计分析_本年平台有效订单总数
司机数据统计分析_当日司机总订单
司机数据统计分析_本月司机总订单
司机数据统计分析_本年度司机总订单
司机数据统计分析_当日的人均订单完成率
司机数据统计分析_本月的人均订单完成率
司机数据统计分析_本年度的人均订单完成率
司机数据统计分析_汇总司机订单完成率
司机数据统计分析_用户数据统计分析_数据准备
用户数据统计分析_日新增用户
用户数据统计分析_周、月新增用户
用户数据统计分析_汇总日、周、月新增用户数据
用户数据统计分析_统计日活跃用户
用户数据统计分析_统计周、月活跃用户
用户数据统计分析_次日留存用户
用户数据统计分析_周留存率
用户数据统计分析_月留存率
用户数据统计分析_汇总日、周、月留存率
即席查询_Phoenix介绍
即席查询_Phoenix安装
即席查询_Phoenix常用的命令操作
即席查询_JDBC连接接Phoenix
Phoniex生成表_订单、司机、用户数据表
大数据WEB平台_项目创建
大数据WEB平台_整合Mybatis框架
大数据WEB平台_查询新增用户数据
大数据WEB平台_查询留存率数据
大数据WEB平台_查询订单汇总数据
大数据WEB平台_查询车辆订单汇总数据
大数据WEB平台_查询各城市司机注册数据
大数据WEB平台_查询司机订单完成率数据
大数据WEB平台_查询虚拟车站信息
大数据WEB平台_查询实时订单和乘车人数
用户数据统计分析_汇总日、周、月活跃用户
12_大数据概述
大数据是什么?
大数据能做什么?
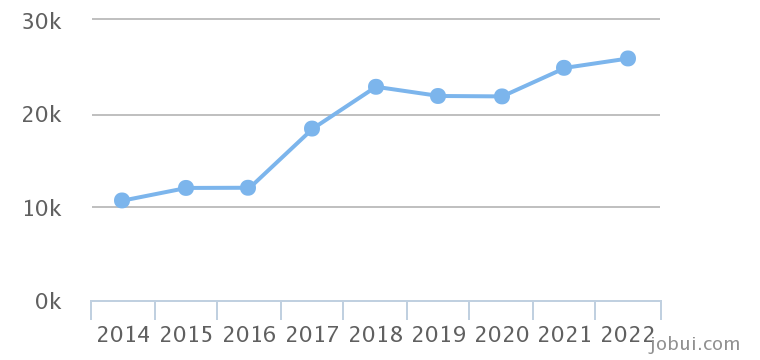
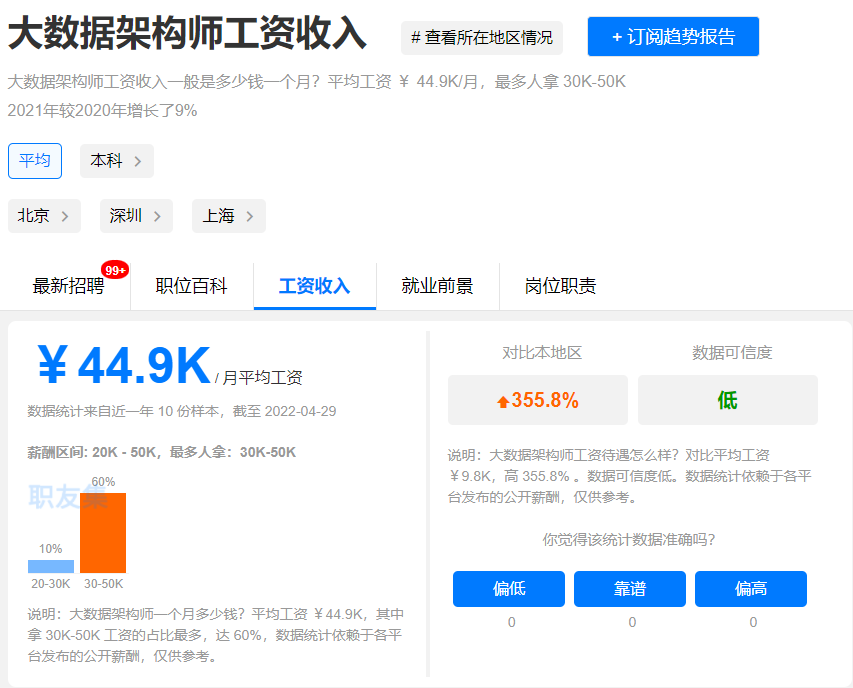
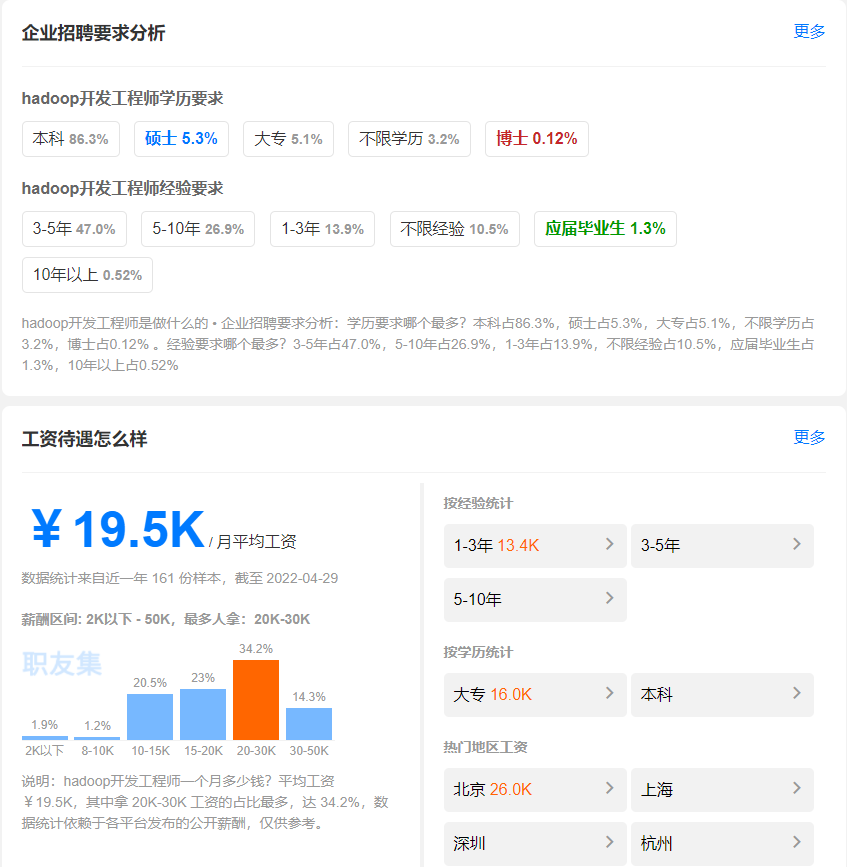
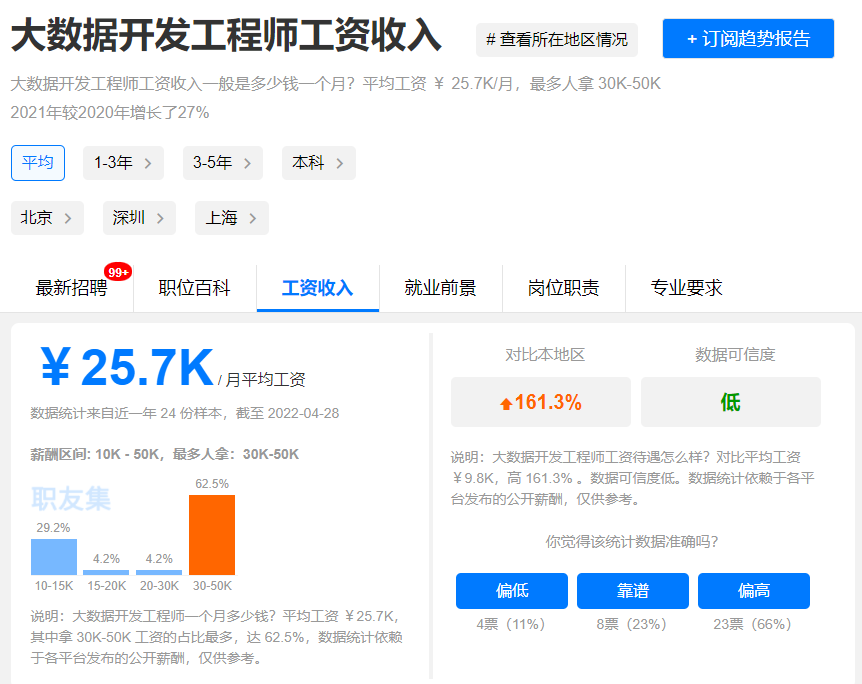
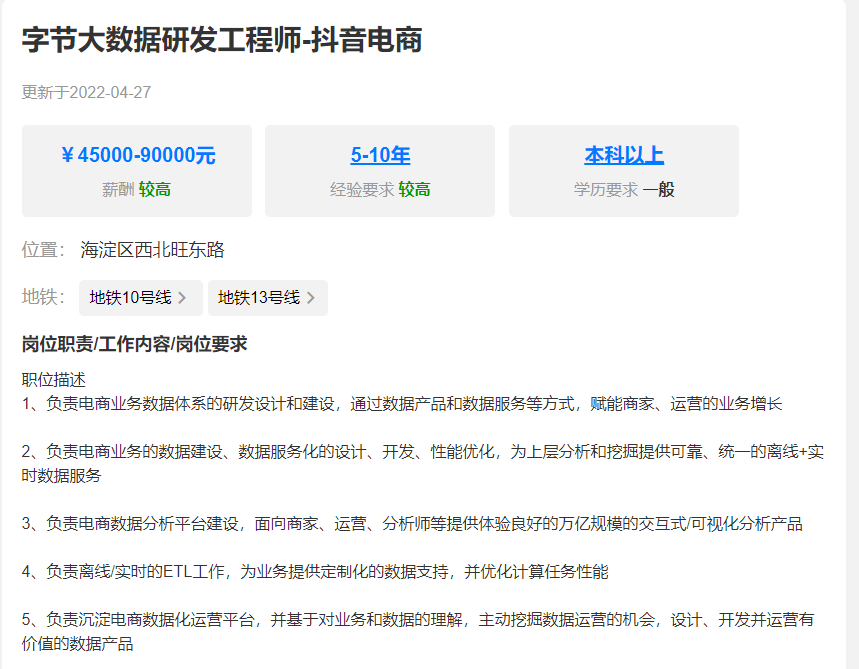
大数据相关岗位
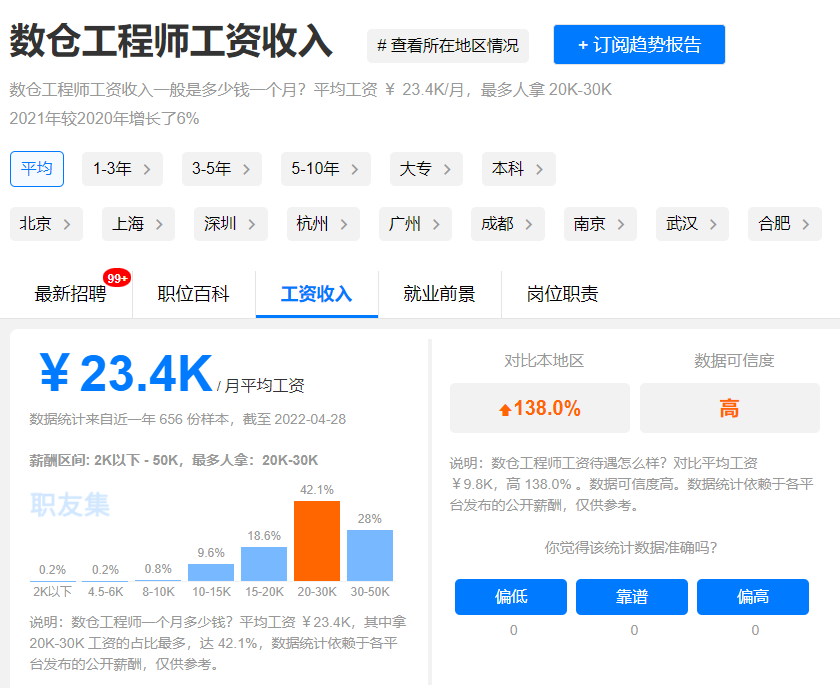
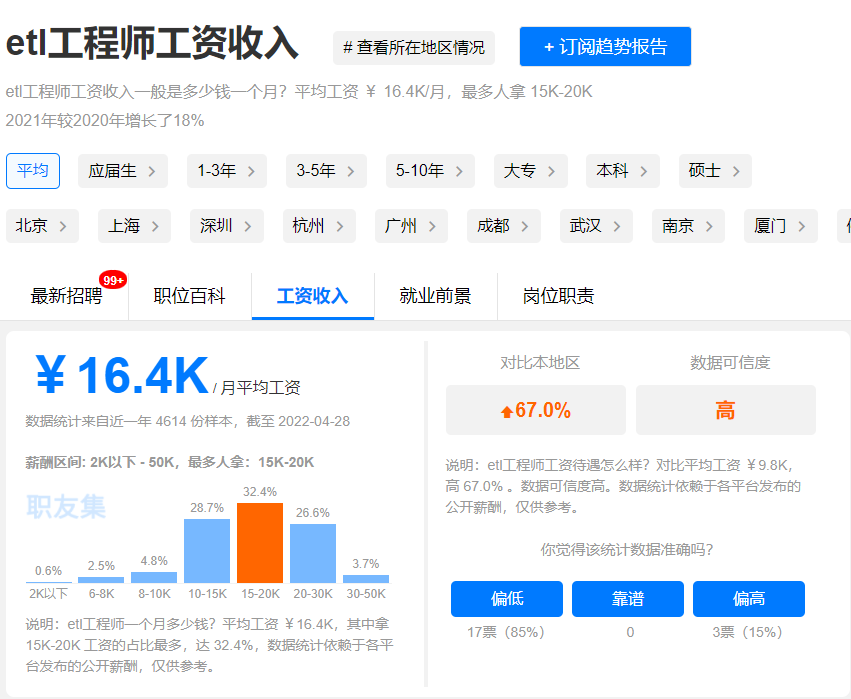
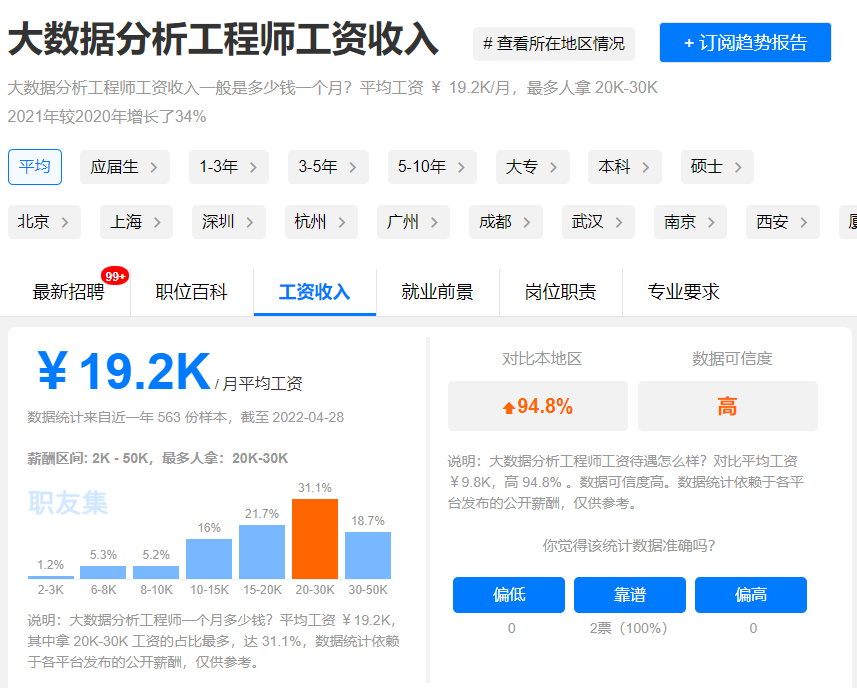
大数据薪资待遇怎么样?
什么人适合学习大数据?
大数据课程都学习什么?
大数据怎么学?
13_Linux操作系统概述与安装
Linux操作系统
安装VMWare软件
安装Centos操作系统上
安装Centos操作系统下
网络设置
安装Xshell7和Xftp7
配置主机名和静态映射
配置时间同步
禁用防护墙
禁用selinux
关闭sshd服务的DNS验证
关机重启命令
拍摄快照
克隆虚拟机
14_Linux常用命令
基本命令_命令入门
基本命令_获取命令的帮助上
基本命令_获取命令的帮助下
基本命令_echo PATH ls
基本命令_pwd cd mkdir
基本命令_cp mv
基本命令_ln rm
文件系统命令_虚拟目录树
文件系统命令_df mount umount
系统操作命令_du stat history
系统操作命令_date
进程相关命令_ps kill
进程相关命令_pstree
进程相关命令_top
进程相关命令_netstat
设置定时任务和时间同步完善
文本操作命令_touch cat head tail
文本操作命令_管道 xargs 数据重定向
文本操作命令_cut
文本操作命令_sort
文本操作命令_sed上
文本操作命令_sed下
文本操作命令_awk上
文本操作命令_awk下
文本操作命令_wc
文本操作命令_vim上
文本操作命令_vim下
文件压缩与打包_zip与unzip
文件压缩与打包_gzip和gunzip
文件压缩与打包_tar上
文件压缩与打包_tar下
15_Linux用户权限和软件安装与管理
用户 用户组 其他人概述
用户管理_添加用户
用户管理_修改与删除用户
用户管理_用户口令管理
用户组管理
用户用户组相关系统文件详讲
Linux文件属性与权限概述
修改所属的用户组
修改文件的所有者
改变权限_数字类型改变权限
改变权限_符号类型改变权限
权限对文件的重要性
权限对于目录的重要性
rpm概述
rpm安装
rpm查询和卸载
yum概述
yum命令
16_ShellScript脚本编程
Shell脚本编程_概述
awk脚本编程实现消费统计
函数的定义与调用
Shell脚本中的变量_本地变量
Shell脚本中的变量_局部变量
shell脚本中的变量_位置变量
Shell脚本中的变量_特殊变量1
数组
横跨父子进程的变量
单双引号和反引号
逻辑表达式
算术表达式
条件表达式
分支结构_if
分支结构_case
循环语句_while
循环语句_for
正则表达式_基本匹配上
正则表达式_基本匹配下
正则表达式_扩展匹配
shell脚本检查
企业面试真题_小米 搜狐
企业面试真题_金山
17_大型网站高并发处理
Nginx是什么
为什么学习Nginx之现实生活中的案例分析
web系统架构变迁中遇到的问题
如何解决这些问题
Nginx作用
Nginx下载与依赖程序的安装
Nginx安装上
Nginx安装下
Nginx目录介绍
Nginx启动与关闭
设置开机自启动
Nginx配置文件之全局快和event块
Nginx配置文件之http块
虚拟主机介绍
基于IP的虚拟主机配置方式上
基于IP的虚拟主机配置方式下
基于端口的虚拟主机配置
基于域名的虚拟主机配置方式
配置服务的反向代理上
配置服务的反向代理中
配置服务的反向代理下
什么是负载均衡和负载均衡策略
实现负载均衡配置
Location配置上
Location配置中
Location配置下
配置动静分离上
配置动静分离下
什么是动态负载均衡
动态负载均衡相关技术
Consul环境搭建
Consul添加服务
nginx-upsync-module简介与安装
Nginx重新安装
Nginx动态负载均衡配置
动态负载均衡测试
生活中的限流和为什么需要限流
如何限流之控制速率
如何限流之限制连接数和设置白名单
Nginx原理
Nginx优化
为什么要学习keepalived
Keepalived概述
VRRP协议的工作原理和VRRP选举机制
keepalived实现Nginx高可用_安装上
keepalived实现Nginx高可用_安装下
Keepalived实现Nginx高可用_配置上
Keepalived实现Nginx高可用_配置下
Keepalived实现Nginx高可用测试
Nginx总结
18_Maven项目管理
为什么要使用Maven
什么是Maven
Maven的作用和Maven工程类型
Maven下载安装
IDEA下载 安装和破解
IDEA整合Maven
Maven仓库是什么
仓库的访问优先级
配置Maven和IDEA整合Maven设置更新
在IDEA中创建Maven工程
Maven项目目录介绍
POM模型_依赖关系
依赖关系_依赖的传递性
依赖关系_依赖相同资源的依赖原则
依赖关系_依赖排除
依赖关系_依赖范围
依赖关系_依赖管理
POM模型_继承关系
POM模型_多继承
POM模型_聚合关系
内置插件_配置编译插件
内置插件_资源拷贝插件
Maven中的常见插件_扩展插件Tomcat
Maven中的常见插件_插件管理
Maven常用命令
Maven项目命名规范
基于Maven创建war工程上
基于Maven创建war工程下
Tomcat热部署上
Tomcat热部署下
19_zookeeper分布式协调服务框架
为什么使用Zookeeper
Zookeeper概述
分布式编程容易出现的问题
拜占庭将军问题
Paxos小岛的故事上
Paxos小岛的故事中
Paxos小岛的故事下
集群架构剖析_ZooKeeper之攘其外
集群架构剖析_Zookeeper之安其内
集群架构剖析_脑裂和服务器数量选取
四台服务器之间免密登录
JDK安装和环境变量配置
集群搭建_下载
集群搭建_搭建步骤上
集群搭建_搭建步骤下
集群搭建_启动和关闭
Znode数据结构
客户端命令行操作一
客户端命令行操作二
客户端命令行操作三
客户端命令行操作四
会话(Session)
事件监听原理刨析
工作原理
Zookeeper集群的特点
IDEA环境搭建
创建ZooKeeper客户端
创建节点
判断节点是否存在
获取节点值和状态信息
获取子节点信息
修改节点值
删除节点
验证注册事件被触发的一次性
分布式协调案例_RMI概述
Java原生RMI实现
开发RMI接口和实现类
通过JNDI发布服务
调用RMI服务
RMI服务的局限性
高可用RMI原理分析上
高可用RMI原理分析下
服务生产者代码分析上
服务生产者代码分析下
服务消费者代码分析
程序测试和总结
20_Git项目版本管理
什么是Git
本地版本控制和集中式版本控制工具
分布式版本控制工具和版本控制工作的作用
为什么要学习Git
Git下载
Git安装
工作机制剖析
常用命令_设置签名与初始化
常用命令_添加、删除文件和文件状态查看
常用命令_提交文件和查看日志
常用命令_修改文件和状态的变化
常用命令_版本切换
什么是分支?
创建分支
查看分支
分支切换
合并分支和删除分支
代码托管中心和码云介绍
Git整合码云_创建SSH Key
Git整合码云_创建远程仓库
Git整合码云_克隆远程仓库到本地
Git整合码云_推送
Git整合码云_拉取
Git整合码云_创建和删除远程库地址别名
Git整合码云_版本冲突的产生
Git整合码云_版本冲突的解决
使用IDEA提交代码
使用IDEA提交代码问题解决
在idea中用git获取新项目代码
版本冲突
21_Hadoop 分布式文件系统HDFS
1TB大文件操作的思考
分治思想引入案例
单机处理大数据的问题上
单机处理大数据的问题下
集群分布式处理大数据
集群分布式处理大数据优劣的辩证
Hadoop是什么?
Hadoop发展历史
Hadoop三大发行版本(了解)
Hadoop核心组件
Hadoop关联项目
HDFS介绍
HDFS架构剖析
HDFS完全分布式搭建_规划和前置环境
hadoop安装包相关上
hadoop安装包相关下
HDFS完全分布式搭建_HDFS集群配置上
HDFS完全分布式搭建_HDFS集群配置中
HDFS完全分布式搭建_HDFS集群配置下
HDFS完全分布式搭建_格式化、启动和测试上
HDFS完全分布式搭建_格式化、启动和测试下
HDFS完全分布式搭建_常见的HDFS命令行操作上
HDFS完全分布式搭建_常见的HDFS命令行操作下
HDFS完全分布式搭建_集群启动和停止总结
NameNode角色分析上
NameNode角色分析下
NameNode_FsImage和Edits log文件分析上
NameNode_FsImage和Edits log文件分析中
NameNode_FsImage和Edits log文件分析下
SecondaryNameNode分析上
SecondaryNameNode分析下
NameNode故障处理(扩展)
NameNode多目录配置(了解)
DataNode分析上
DataNode分析中
DataNode分析下
时间未同步bug解决(选学)
权限(了解)
Hadoop集群的安全模式
Hadoop集群的安全模式_参数配置
Hadoop集群的安全模式_命令操作
准备Hadoop的Windows开发环境
HDFS之JavaAPI_项目搭建
HDFS之JavaAPI_创建目录上
HDFS之JavaAPI_创建目录下
HDFS之JavaAPI_上传文件准备
HDFS之JavaAPI_上传文件高级API实现
HDFS之JavaAPI_上传文件之基础API实现(选学)
HDFS之JavaAPI_上传文件之参数优先级
HDFS之JavaAPI_文件改名和移动
HDFS之JavaAPI_下载文件
HDFS之JavaAPI_文件和目录的删除
HDFS之JavaAPI_获取指定文件的详情
HDFS之JavaAPI_获取指定目录下文件详细
HDFS之JavaAPI_文件和目录的判断
HDFS之JavaAPI_获取指定目录下文件详细测试和总结
HDFS写文件流程_流程剖析一
HDFS写文件流程_流程剖析二.
HDFS写文件流程_流程剖析三
HDFS写文件流程_流程剖析四
HDFS写文件流程_节点距离的计算(理解)
HDFS写文件流程_数据块副本放置策略
HDFS读文件流程(重点)
HDFS Federation联邦
NameNode HA概述
手动NameNode HA概述
自动NameNode HA概述
NameNode自动HA 集群搭建_规划
ssh时不提示信息配置
NameNode自动HA集群搭建_HDFS配置上
NameNode自动HA集群搭建_HDFS配置下
NameNode自动HA集群搭建_首次启动HDFS HA集群一
NameNode自动HA集群搭建_首次启动HDFS HA集群二
NameNode自动HA集群搭建_首次启动HDFS HA集群三.
NameNode自动HA集群搭建_首次启动HDFS HA集群四
NameNode自动HA集群搭建_首次启动HDFS HA集群五
编写HDFS HA启动脚本
编写HDFS HA关闭脚本
22_Hadoop 分布式计算MapReduce和资源管理Yarn
MapReduce的定义
MapReduce优缺点
MapReduce工作流程一
MapReduce工作流程二
MapReduce工作流程三
Yarn资源管理器_架构剖析
Yarn资源管理器_工作机制上
Yarn资源管理器_工作机制下
Yarn RM HA搭建_文档查看与集群规划
Yarn RM HA搭建_相关文件配置
Yarn RM HA搭建_启动
Yarn RM HA搭建_测试
Yarn RM HA搭建_高可用测试
Yarn RM HA搭建_启动脚本编写
Yarn RM HA搭建_关闭脚本编写
Yarn RM HA搭建_资源调度器介绍
Yarn RM HA搭建_FIFO资源调度器
Yarn RM HA搭建_容量(Capacity)调度
Yarn RM HA搭建_公平(Fair)调度器上
Yarn RM HA搭建_公平(Fair)调度器下
单词数量统计案例实战_运行自带的wordcount上
单词数量统计案例实战_运行自带的wordcount下
自带的wordcount源码分析
手写wordcount_环境准备
手写WordCount_Mapper类编写上
手写WordCount_Mapper类编写下
手写WordCount_Reducer类编写
手写WordCount_Driver类编写
手写WordCOunt_本地运行测试
手写WordCOunt_集群中运行测试
Hadoop序列化与反序列化一
Hadoop序列化与反序列化二
Hadoop序列化与反序列化三
MapReduce源码分析_准备工作一
MapReduce源码分析_准备工作二
客户端提交作业_waitForCompletion
客户端提交作业_monitorAndPrintJob
客户端作业提交_submit
客户端作业提交_job资源在hdfs上的路径(选学)
切片数量的计算(重点)一
切片数量的计算(重点)二
切片数量的计算(重点)三
切片数量的计算(重点)四
切片数量的计算(重点)五
切片数量的计算(重点)六
切片数量的计算(重点)七
切片数量的计算(重点)八
切片数量的计算(重点)九
Map阶段源码分析_源码从哪里看
Map阶段源码分析_runNewMapper引入
Map阶段源码分析_runNewMapper分析
Map阶段源码分析_mapper和inputFormat对象如何创建?
Map阶段源码分析_input对象如何创建?
Map阶段源码分析_initialize分析
Map阶段源码分析_run(mapperContext)分析
Map阶段源码分析_nextKeyValue()分析
Map阶段源码分析_out对象如何创建
Map阶段源码分析_有Reduce时out对象创建
Map阶段源码分析_分区
Map阶段源码分析_自定义分区类
Map阶段源码分析_圆形缓冲区引入
Map阶段源码分析_圆形缓冲区一
Map阶段源码分析_圆形缓冲区二
Map阶段源码分析_圆形缓冲区三
Map阶段源码分析_圆形缓冲区四
Map阶段源码分析_排序比较器一
Map阶段源码分析_排序比较器二
Map阶段源码分析_排序比较器三
Map阶段源码分析_没有Reduce
Reduce阶段源码分析_概述
Reduce阶段源码分析_copy数据源码一
Reduce阶段源码分析_copy数据源码二
Reduce阶段源码分析_copy数据源码三
Reduce阶段源码分析_分组比较器一
Reduce阶段源码分析_分组比较器二
Reduce阶段源码分析_如何自定义分组比较器
Reduce阶段源码分析_Reduce类
Reduce阶段源码分析_Reducer运行时run方法一
Reduce阶段源码分析_Reducer运行时run方法二
Reduce阶段源码分析_Reducer运行时run方法三
温度分析案例实战_需求分析
温度分析案例实战_Weather类开发上
温度分析案例实战_Weather类开发下
温度分析案例实战_WeatherMapper类开发上
温度分析案例实战_WeatherMapper类开发下
温度分析案例实战_分区类编写
温度分析案例实战_排序比较器编写
温度分析案例实战_分组比较器编写
温度分析案例实战_WeatherReducer类编写
温度分析案例实战_WeatherDriver类编写
温度分析案例实战_运行测试上
温度分析案例实战_运行测试下
Reduce中遍历values时key是否改变一
Reduce中遍历values时key是否改变二
好友推荐案例实战_需求
好友推荐案例实战_数据集
好友推荐案例实战_案例分析
好友推荐案例实战_项目搭建
好友推荐案例实战_FOFDriver1开发一
好友推荐案例实战_FOFDriver1开发二
好友推荐案例实战_FOFMapper1开发
好友推荐案例实战_FOFReducer1开发
好友推荐案例实战_MR1测试
好友推荐案例实战_FOFDriver2开发
好友推荐案例实战_FOFMapper2开发
好友推荐案例实战_FOFReducer2开发一
好友推荐案例实战_FOFReducer2开发二
好友推荐案例实战_FOFReducer2开发三
好友推荐案例实战_MR2测试
hadoop 3.x 新特性
23_数据仓库 Hive
Hive概述_简介
Hive概述_系型数据库区别
Hive概述_Hive的优缺点
Hive概述_Hive架构一
Hive概述_Hive架构二
Hive下载与安装_三种安装方式区别
Hive下载与安装_下载地址
Hive下载与安装_官网阅读
Hive下载与安装_MySQL安装一
Hive下载与安装_MySQL安装二
Hive下载与安装_直连数据库模式安装一
Hive下载与安装_直连数据库模式安装.二
Hive下载与安装_直连数据库式启动和使用一
Hive下载与安装_直连数据库式启动和使用二
Hive下载与安装_远程服务器模式安装一
Hive下载与安装_远程服务器模式安装二
Hive下载与安装_远程服务器模式安装三
Hive下载与安装_远程服务器模式测试
Hive SQL_官网介绍
Hive SQL_数据库实例创建
Hive SQL_数据库实例查询.showmp4
Hive SQL_数据库实例查询desc
Hive SQL_数据库实例修改
HiveSQL_数据库实例删除
HiveSQL_数据类型
HiveSQL_完整的DDL建表语法规则
HiveSQL_创建表
HiveSQL_查看表描述信息
HiveSQL_删除表
HiveSQL_添加数据load 一
HiveSQL_添加数据load 二
HiveSQL_添加数据insert 一
HiveSQL_添加数据insert 二
HiveSQL_默认分隔符
HiveSQL_删除表中数据
HiveSQL_内部表和外部表一
HiveSQL_内部表和外部表二
HiveSQL_内部表和外部表三
HiveSQL_表分区概述
表分区_单分区
表分区_双分区
表分区_添加分区
表分区_删除分区
表分区_修复分区
HiveSQL_使用已有表建表(扩展)
HiveSQL_SerDe
查询语句_语法规则与数据准备
查询语句_全表和指定列查询
查询语句_列别名和算术运算符
查询语句_常用聚合函数 where语句 limit语句
查询语句_比较运算符一
查询语句_比较运算符二
查询语句_逻辑运算符
查询语句_分组
查询语句_表别名
查询语句_笛卡尔积
查询语句_join语句
查询语句_order by排序
查询语句_sort by排序
查询语句_distribute by
查询语句_cluster by
查询语句_基站掉话率分析实战上
查询语句_基站掉话率分析实战下
函数_内置函数
函数_数学函数
函数_收集函数和类型转换函数
函数_日期函数
函数_条件函数
函数_字符串函数
函数_内置的聚合函数和内置表生成函数
函数_复杂函数
函数_自定义函数
函数_自定义UDF函数一
函数_自定义UDF函数二
函数_自定义UDF函数三和自定义UDAF函数
函数_hive实现wordcount单词统计
函数_struct的使用
Hive参数与动态分区_参数一
Hive参数与动态分区_参数二
Hive参数与动态分区_动态分区
Hive分桶_分桶概述
Hive分桶_创建分桶表二
Hive分桶_抽样查询分析(了解)
Lateral View
视图View
索引(了解)
Hive运行方式_命令行方式cli
Hive运行方式_脚本运行方式(重点)
Hive优化_Fetch抓取
Hive优化_执行计划
Hive优化_本地运行模式
Hive优化_并行运行
Hive优化_严格与非严格模式
Hive优化_行列过滤
Hive优化_JVM重用和推测执行
Hive优化_小表与大表join
Hive优化_大表与大表join
Hive优化_MapSide聚合
Hive优化_去重统计和避免笛卡尔积出现
Hive优化_合理设置MapTask数量mp4
Hive优化_合理设置Reduce数
24_Scala介绍与安装
什么是Scala
为什么学习Scala
六大特性
Scala环境安装
IDEA插件安装
第一个程序
第一个程序的简介
查看字节码文件
25_Scala基础
标识符_基本规则
标识符_特殊符号
标识符_关键字处理方案
变量
数据类型一
数据类型二
类型转换一
类型转换二
分支控制
循环控制_to和until
循环控制_for循环一
循环控制_for循环二
循环控制_for循环三
循环控制_for循环四
循环控制_while和do while
循环中断
字符串_String一
字符串_String二
字符串_StringBuilder
输入输出_控制台输入
输入输出_本地文件输入
输入输出_互联网文件输入
输入输出_写文件操作
26_基础功能搭建
函数和方法的区别
函数定义_无参无返回值函数
函数定义_有参无返回值函数
函数定义_无参有返回值函数
函数定义_有参有返回值函数
函数定义_总结
不定参数的函数一
不定参数的函数二
默认值参数函数
函数至简原则一
函数至简原则二
函数作为值一
函数作为值二
函数作为值三
函数作为值四
函数作为参数_无参无返回值
函数作为参数_有参有返回值
函数作为参数_有参有返回值简化演示
函数作为参数_一参无返回值简化演示
函数作为参数_两参有返回值简化演示
函数作为参数_案例三
函数作为返回值一
函数作为返回值二
闭包
匿名函数
控制抽象
柯里化函数
递归函数
尾递归函数(选修)
惰性函数(选修)
27_面向对象基础
面向对象基础概述
面向对象基础_包package
面向对象基础_类
面向对象基础_java中的导入import
面向对象基础_Scala中的导入import一
面向对象基础_Scala中的导入import二
面向对象基础_属性一
面向对象基础_属性二
面向对象基础_访问权限
面向对象基础_方法
面向对象基础_对象
面向对象基础_构造方法
28_面向对象高级
伴生类和伴生对象一
伴生类和伴生对象二
伴生类和伴生对象三
抽象类和抽象方法一
抽象类和抽象方法二
抽象属性一
抽象属性二
Trait_Java中的接口
Trait_基本使用一
Trait_基本使用二
Trait_作用解耦合
Trait_原理
Trait_初始化叠加一
Trait_初始化叠加二
Trait_功能叠加
Trait_反射一
Trait_反射二
多学三招_枚举类
多学三招_应用类
多学三招_type定义新类型
29_异常
Java中的异常一
Java中的异常二
Scala中的异常
30_集合类
集合类概述
队列Queue
元组一
元组二
Seq_不可变List一
Seq_不可变List二
Seq_不可变List三
Seq_不可变List四
Seq_可变ListBuffer一
Seq_可变ListBuffer二
Seq_可变ListBuffer三
Seq_ 可变List和不可变List转换
不可变Set
可变Set一
可变Set二
不可变Map集合一
不可变Map集合二
不可变Map集合三
可变Map一
可变Map二
可变Map三
不可变数组一
不可变数组二
不可变数组三
不可变数组四
可变数组一
可变数组二
可变数组和不可变数组转换
集合常用方法_基础方法
集合常用方法_衍生方法一
集合常用方法_衍生方法二
集合常用方法_计算方法一
集合常用方法_计算方法二
集合常用方法_折叠方法
集合常用方法_功能方法map一
集合常用方法_功能方法map二
集合常用方法_功能方法flatten
集合常用方法_功能方法flatMap
集合常用方法_单词数量统计一
集合常用方法_单词数量统计二
集合常用方法_单词数量统计三
31_分布式数据库 HBase
HBase概述、架构与搭建_HBase概述一
HBase概述、架构与搭建_HBase概述二
HBase概述、架构与搭建_数据模型
HBase概述、架构与搭建_名词解释
HBase概述、架构与搭建_架构一
HBase概述、架构与搭建_架构二
HBase概述、架构与搭建_架构三
HBase概述、架构与搭建_搭建一
HBase概述、架构与搭建_搭建二
HBase概述、架构与搭建_集群启动测试一
HBase概述、架构与搭建_集群启动测试二
HBase概述、架构与搭建_HBase Shell一
HBase概述、架构与搭建_HBase Shell二
HBase概述、架构与搭建_HBase特点
数据模型进阶_RowKey
数据模型进阶_列族和列描述符
数据模型进阶_Timestamp
RegionServer架构_RegionServer组成
RegionServer架构_RegionServer管理
HBase进阶_HBase读流程一
HBase进阶_HBase读流程二
HBase进阶_Hbase写完整流程
HBase进阶_HBase写流程之WAL
HBase进阶_HBase写流程之MemStoreFlush
HBase进阶_HBase写流程之minor和major
HBase进阶_HBase写流程之RegionSplit
HBase Java API_环境准备
HBase Java API_创建命名空间
HBase Java API_删除命名空间
HBase Java API_判断表是否存在
HBase Java API_创建表
HBase Java API_删除表
HBase Java API_添加数据
HBase Java API_get数据查询
HBase Java API_scan数据查询一
HBase Java API_scan数据查询二
HBase Java API_删除数据
通话记录分析实战_需求分析
通话记录分析实战_before和after方法
通话记录分析实战_生成数据代码实现一
通话记录分析实战_createTable方法
通话记录分析实战_生成数据代码实现二
通话记录分析实战_生成数据代码实现三
通话记录分析实战_查询某用户3月份的通话记录
通话记录分析实战_删除和添加数据
客户端请求过滤器一
客户端请求过滤器二
过滤器查询实战
表设计_用户角色表设计
表设计_组织(或分类)表设计
Protocol Bufffers压缩_问题引入
Protocol Bufffers压缩_简介
Protocol Bufffers压缩_安装准备
Protocal Buffers压缩_安装及使用步骤
Protocal Buffers压缩_proto文件转java类
Protocal Buffers压缩_insertProtocBuf
Protocal Buffers压缩_scanProtocBuf
HBase与MR整合_HDFS2MR2HBase需求与准备工作
HBase与MR整合_HDFS2MR2HBase开发Main类
HBase与MR整合_HDFS2MR2HBase开发Mapper类
HBase与MR整合_HDFS2MR2HBase开发Reducer类
HBase与MR整合_HDFS2MR2HBase测试
HBase与MR整合_Hbase2MR2HDFS插入数据一
HBase与MR整合_Hbase2MR2HDFS插入数据二
HBase与MR整合_Hbase2MR2HDFS开发Main类
HBase与MR整合_Hbase2MR2HDFS开发Mapper类
HBase与MR整合_Hbase2MR2HDFS开发Reducer类
HBase与MR整合_Hbase2MR2Hbase开发Main类
HBase与MR整合_Hbase2MR2Hbase开发Mapper类
HBase与MR整合_Hbase2MR2Hbase开发Reducer类
HBase优化面试题_PreCreating Regions
HBase优化面试题_Column Family相关优化
HBase优化面试题_Row Key
HBase优化面试题_写表操作优化
HBase优化面试题_读表操作优化
HBase与Hive整合_准备工作
HBase与Hive整合_内部表一
HBase与Hive整合_内部表二
HBase与Hive整合_外部表一
HBase与Hive整合_外部表二
32_模式匹配
switch回顾
基本使用
匹配规则_匹配常量
匹配规则_匹配类型一
匹配规则_匹配类型二
匹配规则_匹配数组
匹配规则_匹配元祖
匹配规则_匹配列表
匹配规则_匹配对象
匹配规则_样例类
应用场景一
应用场景二
应用场景_升级WordCount
偏函数_全量函数实现偏函数场景一
偏函数_全量函数实现偏函数场景二
偏函数_声明和使用
33_隐式转换
隐式转换概述
隐式函数
隐式参数和隐式变量一
隐式参数和隐式变量二
隐式类
隐式转换机制
34_泛型
泛型概述
泛型协变和逆变
泛型的上下边界
常用方法中的泛型
上下文限定
35_正则表达式
正则表达式概述
正则表达式基本使用
正则案例实战
36_Kafka入门
Kafka入门_什么是Kafka
Kafka入门_消息队列应用场景
Kafka入门_消息队列两种模式
Kafka入门_架构相关名词
Kafka入门_基础架构
Kafka入门_下载安装一
Kafka入门_下载安装二
Kafka入门_集群启停脚本
Kafka入门_Topic命令行操作
Kafka入门_消息发送和接收
37_生产者
生产者_发送数据原理剖析一
生产者_发送数据原理剖析二
生产者_同步发送数据一
生产者_同步发送数据二
生产者_异步发送数据
生产者_异步回调发送数据
生产者_拦截器一
生产者_拦截器二
生产者_消息序列化一
生产者_消息序列化二
生产者_分区的优势
生产者_分区策略
生产者_分区实战一
生产者_分区实战二
生产者_自定义分区机制一
生产者_自定义分区机制二
生产者_消息无丢失
生产者_数据去重
生产者_ 数据去重_幂等性
生产者_ 数据去重_事务原理分析
生产者_ 数据去重_事务代码实现
38_Broker
Broker_Zookeeper存储信息
Broker_工作流程
Broker_服役新节点
Broker_退役节点
Broker_Replica
39_消费者
消费者_消费方式
消费者_消费规则
消费者_独立消费主题实战
消费者_独立消费分区实战一
消费者_独立消费分区实战二
消费者_消费者组概述
消费者_消费者组实战
消费者_offset剖析
消费者_offset自动提交
消费者_offset手动提交
消费者_offset手动提交实战
40_Azkaban概述
为什么需要工作流调度系统
Azkaban是什么?
41_Azkaban安装部署
Azkaban下载
制作安装包
tar包准备
MySQL配置Azkaban
配置Executor Server
配置WebServer
42_工作流实战
单作业实战_yaml语言
单作业实战
多作业依赖实战
失败自动重试实战
失败手动重试实战
Java代码作业类型实战
定时任务
43_日志采集Flume
Flume概述_介绍
Flume概述_系统需求
Flume概述_架构
Flume概述_与Scribe区别
Flume安装配置
入门案例一
入门案例二
Flume事务剖析一
Flume事务剖析二
Exec Source案例一
Exec Source案例二
spooldir Source案例一
spooldir Source案例二
Taildir Source案例一
Taildir Source案例二
Sink实战_HDFS Sink参数介绍
Sink实战_HDFS Sink案例一
Sink实战_HDFS Sink案例二
Sink实战_HDFS Sink案例三
Sink实战_Hive Sink
Sink实战_HBase Sink
Flume高级_Agent原理剖析一
Flume高级_Agent原理剖析二
Flume高级_串联架构
Flume高级_串联架构配置实战
Flume高级_串联架构测试与总结
Flume高级_复制和多路复用_定义和案例需求
Nginx安装与配置
Flume高级_复制flume配置
Flume高级_复制测试
Flume高级_聚合架构
聚合架构_配置实战
聚合架构_测试
Flume高级_故障转移
故障转移_配置实战
故障转移_测试
Flume高级_负载均衡
负载均衡_配置实战
负载均衡_测试
企业面试题_Flume的使用场景
企业面试题_Flume存在丢包的问题吗
企业面试题_数据采集到Kafaka的实现方式
企业面试题_Flume组件相关
企业面试题_Flume事务机制
企业面试题_Flume参数调优
44_项目需求分析
项目需求分析_概述
项目需求分析_名称解释
项目需求分析_各模块需求说明
45_系统架构
系统架构_数据流程设计
系统架构_框架版本选型
系统架构_服务器选型
系统架构_集群资源规划设计
系统架构_测试服务器规划
47_JS SDK
JS SDK_概述
JS SDK_执行工作流
JS SDK_数据参数说明
JS SDK_事件分析概述
JS SDK_事件分析_Launch事件
JS SDK_事件分析_PageView事件
JS SDK_事件分析_chargeRequest事件
JS SDK_Event事件和其他api方法
49_数据来源设计
数据来源设计_项目搭建(选学)
数据来源设计_配置tomcat
数据来源分析_JS代码分析一
数据来源分析_JS代码分析六
数据来源分析_Java代码ChargeSuccess分析一
数据来源分析_Java代码ChargeSuccess分析二
数据来源分析_JS代码分析二
数据来源分析_JS代码分析三
数据来源分析_JS代码分析四
数据来源分析_JS代码分析五
数据来源分析_Java代码ChargeSuccess测试
数据来源分析_Java代码ChargeRefund分析与测试
50_Nginx和Flume应用
添加Nginx服务与开机启动(选学)
Nginx日志格式配置
项目中Flume的配置
Flume Avro Source JavaAPI(选学)
51_ETL
ETL_解析思路
ETL_项目搭建一
ETL_项目搭建二
ETL_解析IP地址到地域
ETL_解析浏览器信息
ETL_常量类和工具类剖析一
ETL_常量类和工具类剖析二
ETL_实现Tool接口一
ETL_实现Tool接口二
ETL_实现Tool接口三
ETL代码开发详讲_setConf方法
ETL代码开发详讲_run方法
ETL代码开发详讲_processArgs方法
ETL代码开发详讲_setJobInputPaths方法
ETL代码开发详讲_cleanup方法
ETL代码开发详讲_map方法
ETL代码开发详讲_handleLog方法上
ETL代码开发详讲_handleLog方法下
ETL代码开发详讲_handleRequestData方法上
ETL代码开发详讲_handleRequestData方法下
ETL代码开发详讲_handleUserAgent方法
ETL代码开发详讲_handleIp方法
ETL代码开发详讲_handleData方法
ETL代码开发详讲_generateRowKey方法
ETL代码开发详讲_测试准备工作
ETL代码开发详讲_代码测试一
ETL代码开发详讲_代码测试二
ETL代码开发详讲_代码测试Debug调试一
ETL代码开发详讲_代码测试Debug调试二
ETL代码开发详讲_生成数据
52_新增用户数据处理
新增用户数据处理_思路分析一
新增用户数据处理_思路分析二
新增用户数据处理_思路分析三
新增用户数据处理_创建项目
新增用户数据处理_SQLyog安装配置(选学)
新增用户数据处理_新建数据库和表
新增用户数据处理_维度相关类一
新增用户数据处理_维度相关类BrowserDimension一
新增用户数据处理_维度相关类BrowserDimension二
新增用户数据处理_维度相关类BrowserDimension三
新增用户数据处理_维度相关类BrowserDimension四
新增用户数据处理_维度相关类PlatformDimension
新增用户数据处理_维度相关类KpiDemension
新增用户数据处理_维度相关类DateDimension一
新增用户数据处理_维度相关类DateDimension二
新增用户数据处理_维度相关类DateDimension三
新增用户数据处理_维度相关类StatsDimesion
新增用户数据处理_维度相关类StatsCommonDimesion
新增用户数据处理_维度相关类StatsUserDimesion
新增用户数据处理_维度相关类KpiType
新增用户数据处理_Mapper输出Value类
新增用户数据处理_Reducer输出Value类
新增用户数据处理_添加写入MySQL表相关类
新增用户数据处理_Runner开发一
新增用户数据处理_Runner开发二
新增用户数据处理_Runner开发三
新增用户数据处理_Runner开发四
新增用户数据处理_Runner开发五
新增用户数据处理_Mapper开发一
新增用户数据处理_Mapper开发二
新增用户数据处理_Mapper开发三
新增用户数据处理_Reducer开发
新增用户数据处理_程序测试一
新增用户数据处理_程序测试二
新增用户数据处理_程序测试三
结果存入MySQL的源码解析一
结果存入MySQL的源码解析二
结果存入MySQL的源码解析三
结果存入MySQL的源码解析四
结果存入MySQL的源码解析五
53_活跃用户数据处理
活跃用户数据处理_需求分析
活跃用户数据处理_Runner开发提示
活跃用户数据处理_Mapper开发提示
活跃用户数据处理_Reducer开发提示和相关类以及配置文件
开发其他模块的步骤
54_Sqoop
Sqoop_概述
Sqoop_导入和导出原理剖析
Sqoop_安装和测试一
Sqoop_安装和测试二
Sqoop_查询数据库实例
Sqoop_命令行导入
Sqoop_将脚本写入文件运行
Sqoop_指定SQL导入
Sqoop_指定导入字段间的分隔符
Sqoop_导入到HIVE
Sqoop_导出数据到mysql
Sqoop_默认的hive分隔符
55_用户浏览深度分析
用户浏览深度分析_需求分析
站在用户维度的浏览深度_hql编写一
站在用户维度的浏览深度_hql编写二
站在用户维度的浏览深度_hql编写三
站在用户维度的浏览深度_Hive中创建表
站在用户维度的浏览深度_hql行转列join方式
站在用户维度的浏览深度_hql行转列union all方式
站在用户维度的浏览深度_hql完善一
站在用户维度的浏览深度_hql完善二
站在用户维度的浏览深度_编写UDF类DateDimensionUDF
站在用户维度的浏览深度_编写UDF类PlatformDimensionUDF
站在用户维度的浏览深度_Hive创建函数
站在用户维度的浏览深度_sqoop脚本编写
站在会话维度的浏览深度
56_理论知识和项目需求
数据库与ER建模_数据库三范式
数据库与ER建模_ER实体关系模型
数据仓库与维度建模_数据仓库(Data Warehouse)
数据仓库与维度建模_数据库与数据仓库区别
数据仓库与维度建模_数据仓库的发展历程
数据仓库与维度建模_维度建模
数据仓库与维度建模_维度建模案例
数据仓库与维度建模_数仓分层设计一
数据仓库与维度建模_数仓分层设计二
数据仓库与维度建模_数仓分层设计案例
项目需求_项目介绍
项目需求_项目架构
项目需求_集群配置-项目人数-周期
项目需求_数据来源及采集
项目需求_数仓模型设计
57_歌曲热度与歌手热度排行
歌曲热度与歌手热度排行_需求描述
歌曲热度与歌手热度排行_需求分析一
歌曲热度与歌手热度排行_需求分析二
歌曲热度与歌手热度排行_需求分析三
歌曲热度与歌手热度排行_DataGrip安装激活
歌曲热度与歌手热度排行_配置HiveServer2
歌曲热度与歌手热度排行_DataGrip配置
歌曲热度与歌手热度排行_模型设计
歌曲热度与歌手热度排行_Sqoop数据全量同步
歌曲热度与歌手热度排行_Sqoop数据全量同步解决bug
歌曲热度与歌手热度排行_项目搭建
歌曲热度与歌手热度排行_ 歌曲播放日志解析思路
歌曲热度与歌手热度排行_ 歌曲播放日志解析编码一
歌曲热度与歌手热度排行_ 歌曲播放日志解析编码二
歌曲热度与歌手热度排行_ 歌曲播放日志解析编码三
歌曲热度与歌手热度排行_ 歌曲播放日志解析编码三
歌曲热度与歌手热度排行_ 歌曲播放日志解析编码四
歌曲热度与歌手热度排行_ 歌曲播放日志解析编码五
歌曲基本信息TO至TW思路分析
歌曲基本信息TO至TW编码一
歌曲基本信息TO至TW编码一
歌曲基本信息TO至TW编码二
歌曲基本信息TO至TW编码三
歌曲基本信息TO至TW编码四
歌曲基本信息TO至TW编码五
歌曲基本信息TO至TW编码六
歌曲基本信息TO至TW编码七
歌曲特征N日统计思路分析
歌曲特征N日统计编码一
歌曲特征N日统计编码二
歌曲特征N日统计编码三
歌曲特征N日统计编码四
歌曲特征N日统计编码五
歌曲特征N日统计编码六
歌曲特征N日统计编码测试
歌曲影响力指数日统计思路分析一
歌曲影响力指数日统计思路分析二
歌手影响力指数日统计编码一
歌手影响力指数日统计编码二
歌手影响力指数日统计编码三
歌手影响力指数日统计编码测试
Azkaban配置任务流一
Azkaban配置任务流二
Azkaban配置任务流二
Azkaban配置任务流三
Azkaban配置任务流四
Azkaban配置任务流五
Azkaban配置任务流六
Azkaban配置任务流执行测试
歌曲影响力指数日统计编码一
歌曲影响力指数日统计编码二
歌曲影响力指数日统计编码三
歌曲影响力指数日统计编码四
歌曲影响力指数日统计编码五
歌曲影响力指数日统计编码测试
SuperSet数据可视化
58_活跃用户日统计
活跃用户日统计_需求分析
活跃用户日统计_数仓模型设计
活跃用户日统计_Sqoop数据同步一
活跃用户日统计_Sqoop数据同步二
活跃用户日统计_ETL数据清洗思路
活跃用户日统计_ETL数据清洗编码一
活跃用户日统计_ETL数据清洗编码二
活跃用户日统计_ETL数据清洗编码三
活跃用户日统计_ETL数据清洗编码四
活跃用户日统计_ETL数据清洗编码五
活跃用户日统计_ETL数据清洗编码测试
活跃用户日统计_Azkaban配置任务流一
活跃用户日统计_Azkaban配置任务流二
活跃用户日统计_Azkaban配置任务流三
活跃用户日统计_Superset数据可视化
59_商户营收统计和地区营收日统计
商户营收日统计_需求描述
商户营收日统计_需求分析
商户营收日统计_数仓模型设计一
商户营收日统计_数仓模型设计二
商户营收日统计_抽取user_location到ODS层
商户营收日统计_抽取机器消费订单明细到ODS层
商户营收日统计_高德API概述
商户营收日统计_高德账号申请key
商户营收日统计_高德API调用
商户营收日统计_高德API响应结果分析
商户营收日统计_机器位置信息日统计思路分析
商户营收日统计_机器位置信息日统计编码一
二
三
四
五
六
七
八
九
商户营收日统计_机器位置信息日统计编码总结
商户营收日统计_消费退款订单流水日增量思路分析
商户营收日统计_消费退款订单流水日增量编码
商户营收日统计_消费退款订单流水日增量测试和总结
商户营收日统计_机器营收情况日统计思路分析
商户营收日统计_机器营收情况日统计编码一
商户营收日统计_机器营收情况日统计编码二
三
四
五
六
商户营收日统计_EDS至DM思路分析
商户营收日统计_EDS至DM编码一
商户营收日统计_EDS至DM编码二
商户营收日统计_Superset数据可视化
地区营收日统计_需求分析
地区营收日统计_数仓模型设计
地区营收日统计_数据统计思路分析
地区营收日统计_数据统计编码一
地区营收日统计_数据统计编码二
地区营收日统计_Azkaban配置任务流一
地区营收日统计_Azkaban配置任务流二
地区营收日统计_Azkaban配置任务流三
地区营收日统计_Azkaban配置任务流四
地区营收日统计_Superset数据可视化一
地区营收日统计_Superset数据可视化二
地区营收日统计_Superset数据可视化三
60_机器详细信息统计
机器详细信息统计_需求分析
机器详细信息统计_MySQL表概述一
机器详细信息统计_MySQL表概述二
机器详细信息统计_Hive模型设计
机器详细信息统计_Sqoop数据同步一
机器详细信息统计_Sqoop数据同步二
机器详细信息统计_ETL数据清洗思路
机器详细信息统计_ETL数据清洗编码一
二
三
四
五
六
七
八
机器详细信息统计_ETL数据清洗编码九
机器详细信息统计_ETL数据清洗编码测试一
机器详细信息统计_ETL数据清洗编码测试二
机器详细信息统计_Azkaban配置任务流一
机器详细信息统计_Azkaban配置任务流二
机器详细信息统计_SuperSet数据可视化一
二
三
61_实时分析
实时分析_技术架构
实时分析_项目添加Module
实时分析_数据采集接口
实时分析_数据采集接口部署
实时分析_生产数据代码剖析
实时分析_Flume采集配置
实时分析_日志采集实战
实时分析_Redis安装
实时分析_用户PV和UV需求分析
实时分析_用户PV和UV编码_存偏移量
实时分析_用户PV和UV编码_取偏移量
实时分析_用户PV和UV编码_存HSet
实时分析_用户PV和UV编码_RealTimePVUV一
实时分析_用户PV和UV编码_RealTimePVUV二
实时分析_用户PV和UV编码_RealTimePVUV三
实时分析_用户PV和UV编码_RealTimePVUV四
实时分析_用户PV和UV编码_RealTimePVUV五
实时分析_用户PV和UV测试一
实时分析_用户PV和UV测试二
实时分析_歌曲热榜需求分析
实时分析_歌曲热榜编码一
实时分析_歌曲热榜编码二
实时分析_歌曲热榜编码三
实时分析_歌曲热榜Flume配置
实时分析_歌曲热榜测试
实时分析_歌曲热榜数据可视化
62_Flink实时计算引擎_基础
Flink概述_无界流和有界流
Flink概述_有状态的计算
Flink概述_Flink是什么?
Flink概述_发展历史
Flink概述_为什么用Flink?
Flink概述_应用场景
入门案例_创建项目
入门案例_编程模型
入门案例_单词统计批处理Java版一
入门案例_单词统计批处理Java版二
入门案例_单词统计流处理Java版一
入门案例_单词统计流处理Java版二
入门案例_单词统计批处理Scala版
入门案例_单词统计流处理Scala版
入门案例_单词统计流批统一
Flink架构与部署_运行模式概述
Flink架构与部署_Standalone集群架构
Flink架构与部署_Standalone集群部署
Flink架构与部署_Standalone集群测试
Flink架构与部署_StandaloneHA集群部署
Flink架构与部署_StandaloneHA集群测试
Flink架构与部署_FlinkOnYarn集群架构
Flink架构与部署_FlinkOnYarn集群部署
Flink架构与部署_FlinkOnYarnPerJob原理
Flink架构与部署_FlinkOnYarnPerJob实战
Flink架构与部署_FlinkOnYarnSession原理
Flink架构与部署_FlinkOnYarnSession实战
Flink架构与部署_FlinkOnYarnApplication原理
Flink架构与部署_FlinkOnYarnApplication实战
63_流批一体
流批一体基础知识_概述
流批一体基础知识_并行度
流批一体基础知识_资源槽
流批一体DataSource_概述
流批一体DataSource_File-based
流批一体DataSource_Collection-based一
流批一体DataSource_Collection-base二
流批一体DataSource_Custom
流批一体DataSource_Custom实战一
流批一体DataSource_Custom实战二
流批一体DataSource_ CustomMySQL一
流批一体DataSource_CustomMySQL二
流批一体DataSource_KafkaConnector
流批一体DataSource_FlinkKafkaConsumer实战
流批一体DataSource_FlinkKafkaConsumer测试
流批一体DataSource_Kafka数据源Offset
流批一体DataSource_Kafka数据源Offset扩展
流批一体DataSource_KafkaSource
流批一体DataSink_FlinkKafkaProducer
流批一体DataSink_FlinkKafkaProducer
流批一体DataSink_RedisSink一
流批一体DataSink_RedisSink二
流批一体DataSink_FileSink一
流批一体DataSink_FileSink二
流批一体DataSink_JdbcSink
流批一体DataSink_自定义Sink一
流批一体DataSink_自定义Sink二
流批一体数据转换_基本转换算子
流批一体数据转换_聚合算子一
流批一体数据转换_聚合算子二
流批一体数据转换_union算子
流批一体数据转换_connect算子
流批一体数据转换_函数类
流批一体数据转换_富函数类一
流批一体数据转换_富函数类二
流批一体数据转换_ProcessFunction
流批一体数据转换_SideOutputs
65_窗口、时间和状态
窗口与时间_窗口概述
窗口与时间_窗口类型
窗口与时间_窗口API概述
窗口与时间_时间窗口实战一
二
窗口与时间_时间窗口实战三
窗口与时间_滚动计数窗口实战
窗口与时间_滑动计数窗口实战
窗口与时间_会话窗口实战一
二
窗口与时间_时间语义
窗口与时间_ 事件时间实战一
二
窗口与时间_ 事件时间实战三
窗口与时间_EventTime窗口时间
窗口与时间_Watermark
窗口与时间_Watermark
窗口与时间_AllowedLateness
窗口与时间_Watermark与AllowedLateness
窗口与时间_丢弃SideOutput一
二
窗口与时间_丢弃SideOutput三
状态相关_状态概述
状态相关_状态分类
状态相关_状态存储结构
状态相关_键控状态实战一
状态相关_键控状态实战二
状态相关_键控状态实战三
状态相关_Checkpoint
状态相关_StateBackend
状态相关_Checkpoint配置
状态相关_Checkpoint实战一
状态相关_Checkpoint实战二
状态相关_Checkpoint实战
状态相关_Checkpoint手动恢复
状态相关_Checkpoint自动恢复
状态相关_Savepoint
状态相关_Savepoint实战
66_TableAPI、SQL和CDC
TableAPI与SQL_概述
TableAPI与SQL_发展历史
TableAPI与SQL_执行原理一
TableAPI与SQL_执行原理二
TableAPI与SQL_执行原理三
TableAPI与SQL_SQL入门案例一
TableAPI与SQL_SQL入门案例二
TableAPI与SQL_TableApi入门案例
SQLConnector_KafkaSource一
SQLConnector_KafkaSource二
SQLConnector_KafkaSink一
SQLConnector_KafkaSink二
SQLConnector_JDBCSink
SQLConnector_JDBCSource
SQLConnector_FileSystem
SQLConnector_HBaseSink一
二
三
SQLConnector_HBaseSource
集成Hive_SQLClient
集成Hive_Flink&Hive优势
集成Hive_Catalog概述
集成Hive_SQLClint整合Hive一
集成Hive_SQL整合Hive
集成Hive_SQLClint整合Hive
CDC_概述
CDC_MySQL配置
CDC_基于DataStream实战一
二
CDC_基于SQL实战
扩展应用场景_事件驱动型应用
扩展应用场景_数据分析应用
扩展应用场景_数据管道应用
67_ 亚秒级智慧交通实时监控平台
项目介绍_项目架构
项目介绍_名称解释
项目介绍_数据流
项目介绍_模块划分
数据字典_创建Maven项目
数据字典_卡口车辆采集数据
数据字典_城市交通管理数据表
数据字典_超速车辆数据表
数据字典_违法车辆数据表
数据字典_车辆轨迹数据表
实时卡口监控分析_生产数据
实时卡口监控分析_数据入kafka
实时卡口监控分析_实时车辆超速监控需求
实时卡口监控分析_实时车辆超速监控编码一
实时卡口监控分析_实时车辆超速监控bug解决
实时卡口监控分析_实时车辆超速监控编码二
三
四
实时卡口监控分析_卡口拥堵情况分析需求
实时卡口监控分析_卡口拥堵情况分析编码一
二
三
四
五
六
实时卡口监控分析_平均速度TopN的卡口_需求分析
实时卡口监控分析_平均速度TopN的卡口_编码
实时卡口监控分析_平均速度TopN的卡口_编码与测试
复杂事件处理CEP_概述
复杂事件处理CEP_快速入门一
复杂事件处理CEP_快速入门二
复杂事件处理CEP_量词
复杂事件处理CEP_近邻关系
复杂事件处理CEP_处理匹配事件
智能实时报警_套牌分析需求
一
二
三
智能实时报警_危险驾驶分析需求
一
二
三
四
五
测试
智能实时报警_出警分析需求
一
二
三
四
五
测试
智能实时报警_出警分析IntervalJoin编码一
二
智能实时报警_出警分析IntervalJoin测试
智能实时报警_出警分析扩展
智能车辆布控_违法车辆轨迹跟踪需求
一
测试
二
三
测试
智能车辆布控_车辆分布情况分析需求
智能车辆布控_车辆分布情况分析编码测试
智能车辆布控_布隆过滤器
智能车辆布控_布隆过滤器编码一
智能车辆布控_布隆过滤器编码二
智能车辆布控_布隆过滤器编码和测试
智能车辆布控_外地车分布情况分析
 目录
目录