
分享一下基于encoder-decoder的小说续写模型

去年 @PENG Bo 开源了一个基于GPT模型的ai写小说模型(RWKV),虽然不是写手但也一直在群里潜水。一年下来模型已经从最初版话都说不顺进化到现在具有较为自洽的逻辑。但从网文作者的反馈来看依然存在两个问题,首先是根据作者反映该模型十分容易跑题,前文还在写吃饭的话后文就开始打架了。其次是模型总会出现新的人名地名,把这些人名地名揪出来就成为了新的难题。
如果技术细节没兴趣或者看不懂的读者可以拉到最后直接看效果。
首先分析下为什么会出现这些问题。对于长文本生成来说跑题并不难理解,因为实际上模型只能看到最后的几百个字如果要生成几千上万字那跑题是理所当然的,但很多时候哪怕只生成几百字依然会跑题。在我看来,这是因为attention的稀疏性导致的。
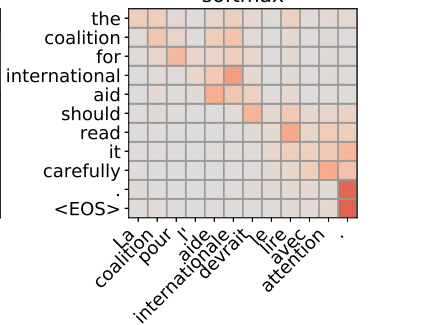

如图所示尽管理论上多头自注意力能关注到全文信息,但实际上只能只会关注到周围的几个字而已。当然RWKV使用的是魔改的AFT,但AFT自己的实验里就说了局部的loacl-AFT表现是好于全局AFT的。不止AFT,相当多的local-attention在很多任务上都能获得优于原版attention的效果。某种程度上可以说transformer结构的模型是带有局部性建模的倾向的。在写小说这个任务上,局部性或者说稀疏性就表现为写着写着模型就跑题了。
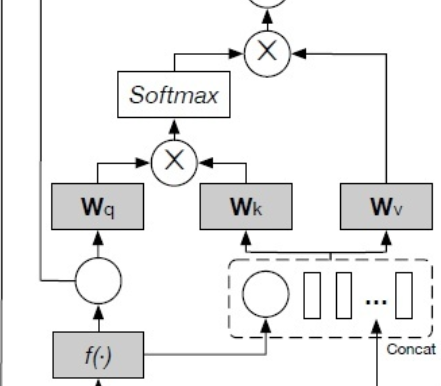

问题的解决方案也很简单,让输入和输出做cross-attention让模型每次生成都回顾输入就能避免模型跑的跑偏了。说白了,就是捡回最初版本的transformer模型结构。用encoder-decoder模型去写小说,将任务类型从小说写作转为小说续写。这两个任务的区别主要在小说续写是一个seq2seq任务,需要定义明确上下文并根据上文生成对应的下文,而小说写作没有严格的上下文定义通常你给个开始符他也能自顾自地写起来。
既然小说续写任务有明确的上下文定义,那问题二也很容易解决了。之所以下文会出现新的人名和地名,是因为人在写小说时本来就会出现很多新的人名和地名,模仿ai的人类自然也会学到这一点。既然是语料上的问题,那就从语料的角度上解决。因为有了明确的上下文定义,那我只要保证下文里不出现上文么米出现过的人名地名那问题不就解决了吗。
基于上述思路,我使用100G中文语料和50G英文语料训练了一个8+8 512的transformer模型。训练时参考了lamb的训练方式,第一阶段先用256输入512输出(这里的256和512是最大长度的意思)过两轮语料,再用512-512的方式过一轮语料。
当然,这种情况下模型训练得不是很充分,生成效果并不好,问题二也没有得到实际的解决。
不过问题不大,我在综合模型的基础上对已有的综合语料进行进一步的精洗进一步得出了针对某一类型小说的语料,通过LAC进行实体识别从而保证下文不会出现上文没出现过的人名地名。目前已经有了"穿越重生" "都市" "二次元" "古言" "洪荒" "科幻" "虐文" "女言" "日轻" "网游电竞" "武侠" "西方名著" "玄幻" "玄幻v2" "娱乐圈" "中国现代文学" "综合言情"这么多专用小说版本。
说了这么多,来看一下实际写作效果。在此感谢北大美少女 @忘忧北萱草 提供的ui。
模型续写长度是自适应的,换句话说续写多少字是模型自己控制的,因此建议多生成几个挑自己满意的使用。
科幻模型续写三体:
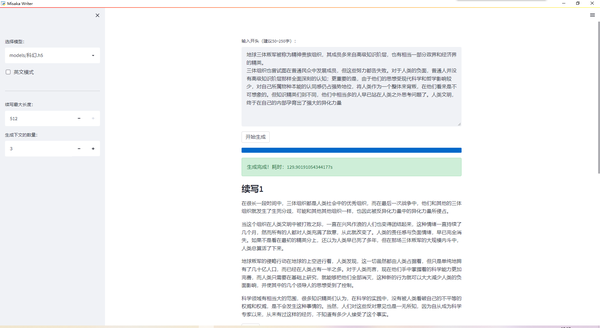

武侠模型续写:
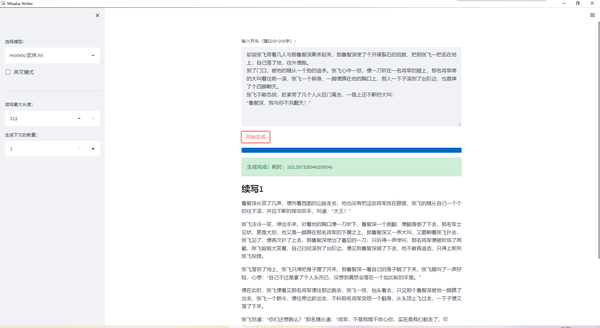

玄幻模型续写盘龙:
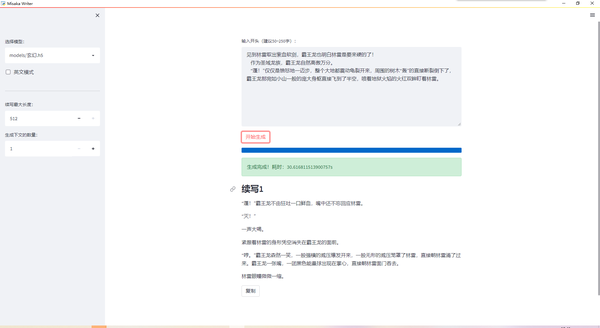

古言模型续写同人
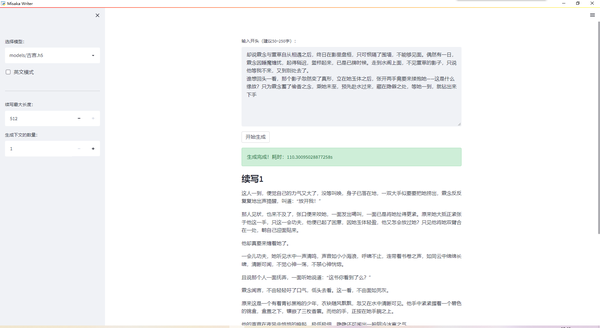

更多玩法有兴趣的可以加我们的交流群体验一下我们的ai续写模型。
对于部分纯小白来说,配环境是个很头疼的事情,因此北大美少女 @忘忧北萱草 为我们提供了傻瓜包。可以在交流群下载,免去你配环境的烦恼。
项目地址: GitHub - pass-lin/misaka-writer
交流群:905398734