AI底层软硬件设计探索(硬件层)

01概述
一个完整的AI软硬件栈主要包括:应用层、框架层、软件层、以及硬件层,如下图1所示。其中底层的软件:包括编译器、优化的库函数、底层驱动等,根据具体情况,决定上层的算法是部署到硬件的哪一个模块去高效执行。

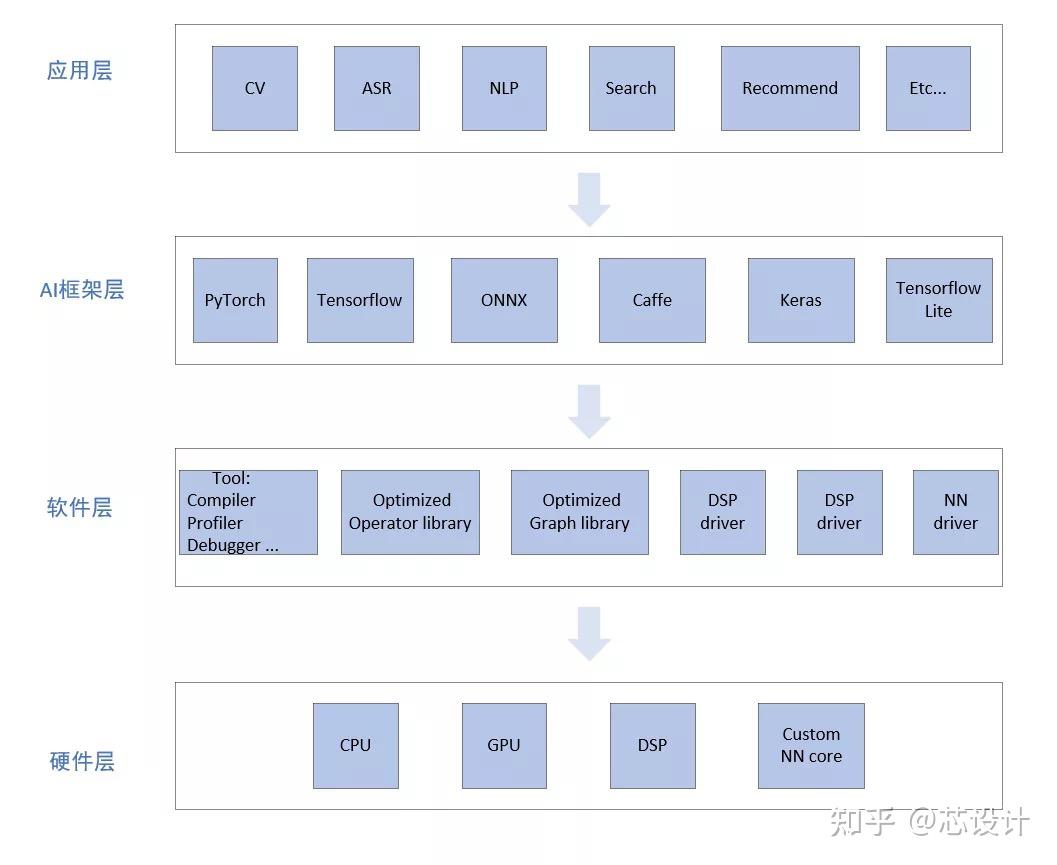
图1: 软件栈
对于AI的应用而言,为了追求更高的能效比,性能,针对该类算法的特点,硬件也会考虑设计一个AI 加速器去加速这类算法,而一个新的硬件单元也需要上述的软件栈配合才能工作。
本文从最底层的硬件角度出发,去探索AI的设计。
02硬件层
硬件的设计现状是用Patterson.David所述:“A New Golden Age for Computer Architecture”. 从云、边缘、端,每一种应用场景下,都有相应的AI 硬件。不同的应用场景,设计上要考虑的点也有不同之处,例如:云上的AI硬件要考虑算力可扩展性,更大的存储带宽、多核与多核的互联通信,数据间交互,以及虚拟化等功能;端侧的AI硬件对功耗的要求会更苛刻。
通常AI硬件主要的数据指标:TOPS; TOPS/W;TOPS/mm2; inf/sec。TOPS: 理论算力;TOPS/W:每瓦的算力,1次乘累加等于2 OPS; TOPS/mm2: 单位面积的算力;inf/Sec:真实的推理性能,每秒能处理多少帧视频或者图片。
这里列举了一些典型的AI硬件架构:
1.DSA的硬件架构:(Domain Specific Architecture,DSA),类似:Nvidia DLA 、Imagination NNA、DianNao.
以Nvidia 开源的DLA为例,图2所示,是典型的面向CNN网络应用的加速器。整个架构设计保证数据流可以在模块间流水线计算,图中数据流走向和卷积网络的算法是一致的,从MEM interface read -> convolution buffer -> convolution core-> SDP -> PDP -> CDP -> MEM interface write,这样的设计可以减小数据带宽,提高能效与性能。为了保证设计的灵活性,每个模块也可以单独工作,提供软件的编程接口,例如SDP、PDP、CDP、RUBIK、BDMA可以独立配置工作。


图2: 第一代 DLA
单核DLA,算力是可以扩展的,从64 mac(8x8) 到 2048 mac(8x8), 测试ResNet50网络模型,在16nm工艺下:能效上可以做到2 -6.4TOPS/W, 性能上:7 - 269frames/s 。
而用在自动驾驶芯片orin的第二代DLA,图3所示,从相关文档中可以看到架构上的一些变化,主要增加的特征点:支持结构化的稀疏,推测应该是Nvidia A100中的4:2稀疏计算的方式; 支持Depth-wise Convolution处理,因为conovlution core 没法对这种类型的卷积进行友好的支持;支持专用的硬件调度器,因为神经网络中一般有多个网络层,为了在网络层与层之间替代CPU来调度配置,所以硬件增加了这个模块,类似cpu中断处理功能;还有算力上的提升,单核变为双核,共享1 MB的缓存。
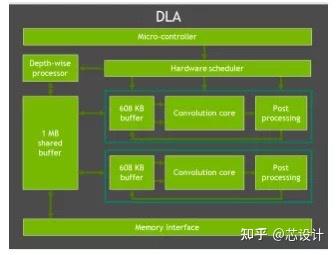
图3: 第二代 DLA
类似DLA 这种专用领域的加速器设计,对专用的算子加速收益比较大的,但存在的一个问题就是:如果算子出现变化,就没法做到及时的支持,此时就会对性能造成影响。最常用的做法就是把这些DLA没法支持的算子,通过编译器部署到通用计算的处理器上,但会带来数据交互的额外开销、性能的损失。
所以目前的设计更倾向下面的思路:
2.CPU+AI core:
类似Arm Ehos-N NPU、Tesla Dojo、Tenstorrent Wormhole/Grayskull. 这里以ARM Ehos-N NPU为例,图4所示。
每一个计算引擎Compute Engine包括:Mac Engine: 处理卷积、矩阵运算;Programmable Layer Engine: 通用的计模块,是一个图灵完备的处理器,里面包括cpu和矢量的引擎,用于处理非卷积的操作:例如激活、池化等操作。这两者Engine可以通过local memory 交互数据。
多个计算引擎之间的数据交互可以通过Network control unit完成。


图4:Ethos-N NPU
MAC Engine 的数据写到通用的矢量寄存器组中,通过中断通知CPU, 然后CPU调度完成后续的数据处理,写回到Local Memory中。


图5:Programmable Layer Engine
以ARM N77为例,单核4TOPS INT8算力,1MB的核内存储,能效大于3TOPS/ W (7nm)。
3.DSP + AI core:
类似Qualcomm cloud AI 100、candence DNA100/150.
这里以Qualcomm AI core为例,图6所示,整个设计包括:scalar processor、vector、Tensor、memory unit,以及共享 8MB VTCM存储模块。scalar processor采用VLIW的指令集、负责整体的调度功能, scalar/vector/tensor 模块是可以并行执行的;8MB VTCM 可以最大程度的数据复用,减小DDR带宽和功耗。


图6:AI core
在soc侧有16 AI core,图7所示,多核之间的NOC互联,存储互联,控制互联结构, 每一个AI core 的激活值可以通过muticast实现共享,提供最高400TOPS的INT8 ; 片上144 MB 的存储空间保证能将权重全部存储。

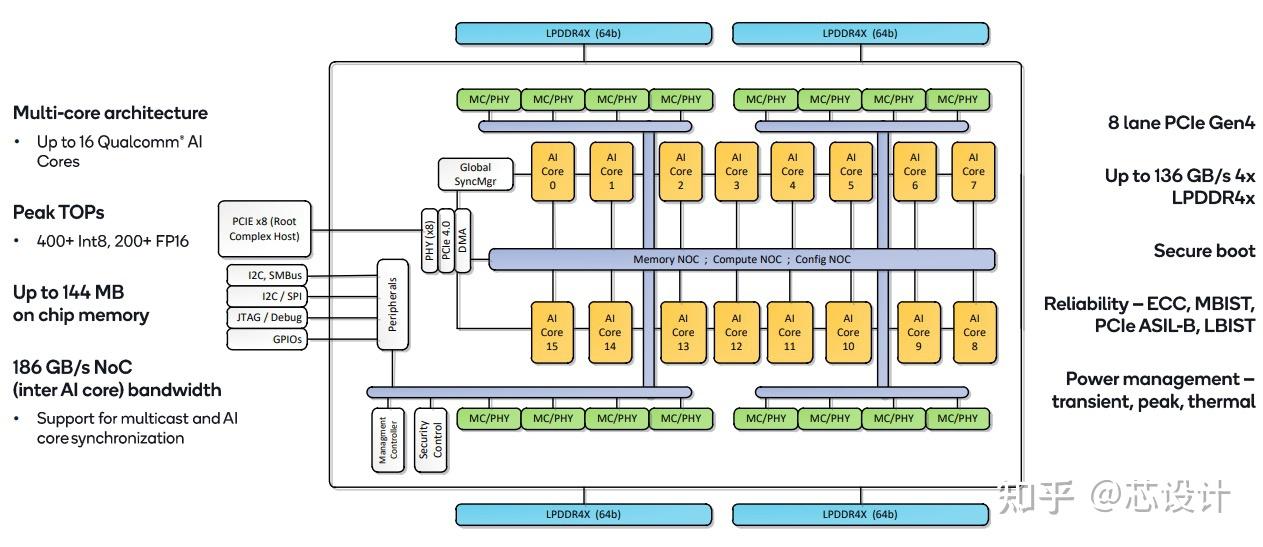
图7:Cloud AI 100 Soc
AI 100 SOC 整体的能耗(7nm),在不同的算力下:5-12TOPS/W。
4.GPU cuda + AI core:
类似Nvidia A100/H100、VeriSilicon’s Vivante VIP9000.
以Nvidia H100 SM为例,图8所示,里面包括 cuda 计算核和tensor 计算核,tensor 计算核负责矩阵相关的运算,cuda 计算核提供其他通用的算力。相对于A100, H100增加了专用的TMA 模块,即asynchronous copies 机制,提供global memory 和 shared memory的数据搬运;以及 Thread Blocks也就是SM2SM的数据搬运,目的是为了提升性能。


图8:H100 SM
在A100 里面 每一个tensor core 折算下来,提供峰值 1TOPS INT8稠密算力@1GHz, H100 的tensor core 做MMA 矩阵乘累加相对于A100 有两倍的性能提升。
5.Google TPU V1-V4:
TPUv1是一个类似于cpu的协处理器设计,数据流固定,定制化的设计,图9所示。只有5条指令,面向推理应用的芯片,其中Matrix Multiply unit采用256x256的脉动阵列结构。


图9:TPUv1
TPUv2: ML 通用的处理器,支持训练。
相对于v1, 用Vector memory代替激活值缓存buffer;用更通用的vector unit 代替定制的激活函数;使用HBM代替DDR, 提高带宽,HBM和 Vector memroy 相连,代替直接与Matrix unit连接;添加Scalar 单元,负责指令的取指和译码,以及标量执行;以及 Memory Processor unit;添加核间互联的模块, 图10所示。
采用VLIW指令架构,和Qualcomm cloud AI 100类似,支持322b VLIW bundle:2 scalar slots、4 vector slots (2 for load/store)、2 matrix slots (push, pop)、1 misc slot、6 immediates。


图10:TPUv2
每一个Matrix unit 由之前的256x256变为128x128,是基于实际的利用率和数据复用率综合考虑,图11所示。

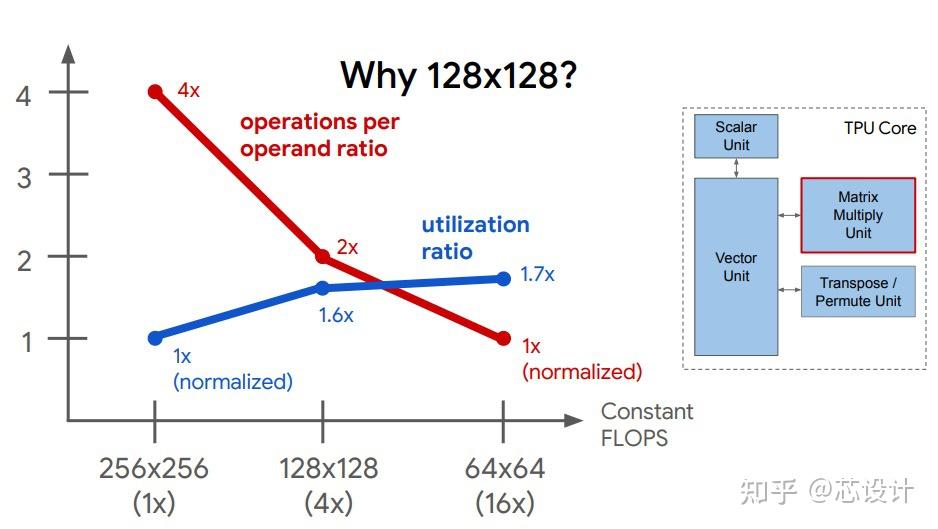
图11:Matrix size
TPUv3相对于v2的算力、带宽提升如下图12所示,最新的TPUv4 能效TOPS/W相对于v3提高了3倍。


图12:TPUv3
从Google TPU V1到V2的产品迭代中,可以看到AI core 设计从专用、定制化的AI到通用AI的设计思想,AI硬件设计趋势大致如此。V2到V4 的演进更多是性能、带宽、能效的提升,而指令集架构、微架构没有明显的变动。
03总结
单个AI core 主要考虑两部分:一部分是专用计算的硬件加速模块、一部分是通用计算的模块。专用的计算模块,目标是为了在运行特定的AI算子上具有更好的能效,更高的性能。而通用的计算模块一方面是加速一些非特定的AI 算子;另一方面保证算法不断迭代过程中,硬件能够依旧适配该变化。以及考虑每一个AI core 内部专用的计算模块与通用计算模块之间的数据交互问题。
多个AI core设计,要考虑算力可扩展性,核与核之间的通信,缓存一致性等,多个AI core 之间的数据交互代价要低,性能要好 。
上述是一些个人的理解,有不足的地方,望谅解。
Citation:
1: https://www.nvidia.com/content/dam/en-zz/Solutions/gtcf21/jetson-orin/nvidia-jetson-agx-orin-technical-brief.pdf
2: http://nvdla.org/hw/v1/hwarch.html
3: https://resources.nvidia.com/en-us-tensor-core
4: https://www.servethehome.com/qualcomm-cloud-ai-100-ai-inference-card-at-hot-chips-33/
5: https://www.arm.com/products/silicon-ip-cpu/ethos/ethos-n78
6: https://old.hotchips.org/hc30/2conf/2.07_ARM_ML_Processor_HC30_ARM_2018_08_17.pdf
7: https://www.verisilicon.com/cn/IPPortfolio/VivanteVIP9000
8: https://hc32.hotchips.org/assets/program/conference/day2/HotChips2020_ML_Training_Google_Norrie_Patil.v01.pdf