NLP系列-关键词抽取技术(一)-技术原理篇

一、背景介绍
关键词提取就是从文本里面把跟这篇文章意义最相关的一些词语抽取出来,在文献检索、自动文摘、文本聚类和文本分类等方面有着重要的应用。
关键词提取算法一般分为有监督和无监督两类:
- 有监督:有监督的关键词提取方法主要是通过分类的方式进行,通过构建一个较为丰富和完善的词表,然后判断每个文档与词表中每个词的匹配程度,以类似打标签的方式,达到关键词提取的效果。优点是精度较高,缺点是需要大批量的标注数据,人工成本过高,并且词表需要及时维护。
- 无监督:相比较而言,无监督的方法对数据的要求低,既不需要一张人工生成且需要持续维护的词表,也不需要人工标注语料辅助训练。目前比较常用的关键词提取算法都是基于无监督算法。如TF-IDF算法,TextRank算法和主题模型算法(包括LSA,LSI,LDA等)。
二、TF-IDF算法简介
TF-IDF(term frequency–inverse document frequency,词频-逆向文件频率)是一种用于信息检索(information retrieval)与文本挖掘(text mining)的常用加权技术。
TF-IDF是一种统计方法,用以评估一字/词对于一个文件集合或一个语料库中的其中一份文档的重要程度。字/词的重要性随着它在文档中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
TF-IDF的主要思想是:如果某个单词在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
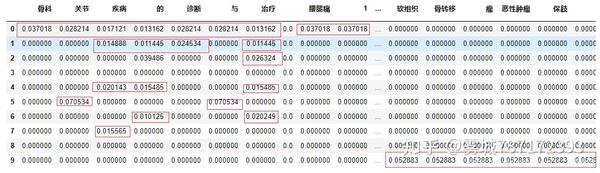

图1:TF-IDF实例矩阵 如图1所示,图示为一个TF-IDF的实例矩阵,该矩阵有10行,即语料库一共有十篇文档,每列表示整个语料库内的某一个词典的字/词,如果谋篇文档中出现了词典中的字/词,那么在实例矩阵中,该位置不为0;若用字/词在该文档中出现的词频来填充,则该实例矩阵为TF矩阵,又称为词频矩阵。当使用逆文档率乘以对应的词频矩阵即可得到如图1所示的TF-IDF矩阵。
2.1 TF-词频(Term Frequency)
词频(TF)表示字/词(关键字)在文档中出现的频率。
这个数字通常会被归一化(一般是词频除以文档总词数), 以防止它偏向长的文档。
TF_{ij}=\frac{n_{ij}}{\sum_{k}n_{ij}}$ $TF_{w}=\frac{某一类字/词w出现的次数}{该类字/词出现的总次数}
其中$n_{ij}$是该字/词在文档$d_{j}$中出现的次数,分母则是文档$d_{j}$中所有字/词出现的次数总和;
2.2 IDF-逆向文件频率(Inverse Document Frequency)
逆向文档频率 (IDF) :某一特定字/词的IDF,可以由总文档数目除以包含该词语的文件的数目,再将得到的商取对数得到。
如果包含字/词w的文档越少, IDF越大,则说明字/词具有很好的类别区分能力。
IDF_{i}=log\frac{D}{|{j:w_{i}\in{d_{j}}}|}
其中,|D|是语料库中的文件总数。 {|{j:w_{i}\in{d_{j}}}|} 表示包含词语 w_i 的文档数目(即 n_{ij}\neq0 的文档数目)。如果该词语不在语料库中,就会导致分母为零,因此一般情况下使用 拉普拉斯平滑化处理 {1+|{j:w_{i}\in{d_{j}}}|} 即:
IDF=log(\frac{语料库的文档总数}{包含字/词w的文档数+1}) ,其中分母加1是为了避免分母为0
2.3 TF-IDF 实际为TF*IDF
某一特定文件内的高词语频率,以及该词语字/词在整个文档集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的字/词,保留重要的字/词。
TF-IDF=TF \times{IDF}
注: TF-IDF算法非常容易理解,并且很容易实现,但是其简单结构