
分布式数据库
详细内容
定义
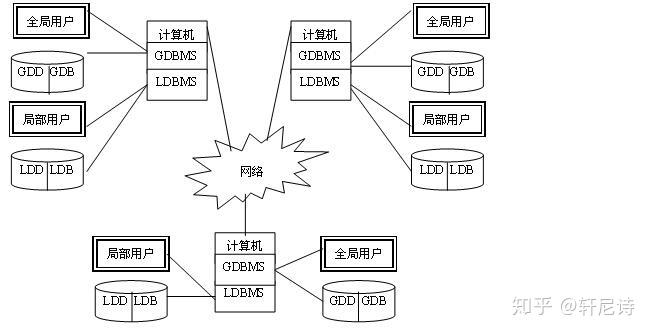
分布式数据库是由一组数据组成的,这组数据分布在计算机网络中的不同的计算机上,网络中的每个节点具有独立处理的能力(称为场地自治),可以执行局部应用。同时,每个节点也能通过网络通信子系统执行全局应用。与之前的定义相比,更注重场地自治性以及自治场地之间的协作性。
分布式数据库的研究始于20世纪70年代中期。世界上第一个分布式数据库系统SDD-1是由美国计算机公司(CCA)于1979年在DEC计算机上实现。20世纪90年代以来,分布式数据库系统进入商品化应用阶段,传统的关系数据库产品均发展成以计算机网络及多任务操作系统为核心的分布式数据库产品,同时分布式数据库逐步向客户机/服务器模式发展。
特性
1.场地自治性(Local Autonomy)
2.非集中式管理(NoReliance On Central Site)
3.高可靠性(Contiuous Operation)
4.位置独立性(Location Transparency and Location Independence)
5.数据分割独立性(Fragmentation Independence)
6.数据复制独立性(Replication 02Independence)
7.分布式查询处理(Distributed Query Processing)
8.分布式事务管理(Distributed Transaction Management)
9.硬件独立性(Hardware Independence)
10.操作系统独立性 (Operating System Independence)
11.网络独立性(Network Independence)
12.数据库管理系统独立性(DBMS Independence)
历史发展
从单机分布式数据库说起,关系型数据库起源自1970年代,其最基本的功能有两个:把数据存下来;满足用户对数据的计算需求。第一点是最基本的要求,如果一个数据库没办法把数据安全完整存下来,那么后续的任何功能都没有意义。当满足第一点后,用户紧接着就会要求能够使用数据,可能是简单的查询,比如按照某个Key 来查找Value;也可能是复杂的查询,比如要对数据做复杂的聚合操作、连表操作、分组操作。往往第二点是一个比第一点更难满足的需求。在数据库发展早期阶段,这两个需求其实不难满足,比如有很多优秀的商业数据库产品,如Oracle/DB2。
在1990 年之后,出现了开源数据库MySQL和PostgreSQL。这些数据库不断地提升单机实例性能,再加上遵循摩尔定律的硬件提升速度,往往能够很好地支撑业务发展。接下来,随着互联网的不断普及特别是移动互联网的兴起,数据规模爆炸式增长,而硬件这些年的进步速度却在逐渐减慢,人们也在担心摩尔定律会失效。在此消彼长的情况下,单机数据库越来越难以满足用户需求,即使是将数据保存下来这个最基本的需求。
2005 年左右,人们开始探索分布式数据库,带起了NoSQL 这波浪潮。这些数据库解决的首要问题是单机上无法保存全部数据,其中以HBase/Cassadra/MongoDB 为代表。为了实现容量的水平扩展,这些数据库往往要放弃事务,或者是只提供简单的KV接口。存储模型的简化为存储系统的开发带来了便利,但是降低了对业务的支撑。
类型
Greenplum
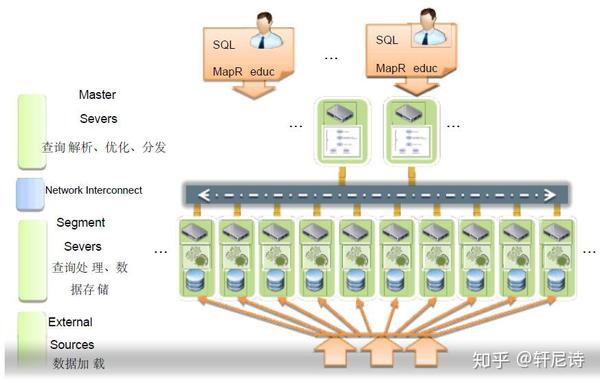
基础架构:Greenplum 是基于Hadoop 的一款分布式数据库产品,在处理海量数据方面相比传统数据库有着较大的优势。
1.数据库由Master Severs 和Segment Severs通过Interconnect 互联组成。
2.Master 主机负责:建立与客户端的连接和管理;SQL的解析并形成执行计划;执行计
划向Segment的分发收集Segment的执行结果;Master不存储业务数据,只存储数据字典。
3.Segment 主机负责:业务数据的存储和存取;用户查询SQL的执行
主要特性
架构:海量数据库采用最易于扩展的Shared-nothing 架构,每个节点都有自己的操作系统、数据库、硬件资源,节点之间通过网络来通信。
并行加载技术:利用并行数据流引擎,数据加载完全并行,加载数据可达到4.5T/ 小时(理想配置)。并且可以直接通过SQL 语句对外部表进行操作。
支持行、列压缩存储技术:海量数据库支持ZLIB 和QUICKLZ 方式的压缩,压缩比可到10:1。压缩数据不一定会带来性能的下降,压缩表通过利用空闲的CPU 资源,而减少I/O 资源占用。海量数据库除支持主流的行存储模式外,还支持列存储模式。如果常用的查询只取表中少量字段,则列模式效率更高,如查询需要取表中的大量字段,行模式效率更高。海量数据库的多种压缩存储技术在提高数据存储能力的同时,也可根据不同应用需求提高查询的效率。
主要局限:列存储模式的使用有限制,不支持delete/update 操作。用户不可灵活控制事务的提交, 用户提交的处理将被自动视作整体事务, 整体提交,整体回滚。数据库需要额外的空间清理维护( vacuum ),给数据库维护带来额外的工作量。用户不能灵活分配或控制服务器资源。对磁盘IO 有比较高的要求。备份机制还不完善,没有增量备份。
Vertica
基础架构
与以往常见的行式关系型数据库不同,Vertica 是一种基于列存储(Column-Oriented)的数据库体系结构,这种存储机构更适合在数据仓库存储和商业智能方面发挥特长。常见的RDBMS 都是面向行(Row-Oriented Database )存储的,在对某一列汇总计算的时候几乎不可避免的要进行额外的I/O 寻址扫描, 而面向列存储的数据库能够连续进行I/O操作,减少了I/O 开销,从而达到数量级上的性能提升。同时, Vertica 支持海量并行存储(MPP)架构,实现了完全无共享,因此扩展容易,可以利用廉价的硬件来获取高的性能,具有很高的性价比。
主要特性
列存储( Column-orientation )
由于大多数的查询都是要从磁盘读取数据, 因此可以说disk I/O 在很大程度上决定了一个查询的最终响应时间。
压缩机制(Aggressive Compression )
在数据存储方面, Vertica 利用内部的特定算法对数据进行压缩处理。这样的机制会大大减少disk I/O 的时间( D),同时由于Vertica 对扫描和聚合等操作也在内部进行了优化,可以直接处理压缩后的数据,这样CPU 的工作负载( C)也减少了。如上例中的AVG 聚合函数, Vertica 是不需要将压缩数据先做类似解压这种处理的,因此查询性能得到优化。
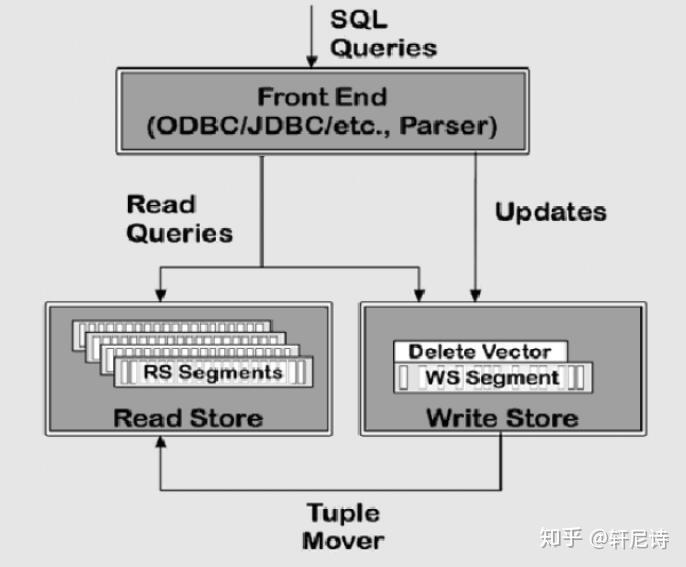
读优化存储( Read-Optimized Storage)
Vertica 的数据库存储容器ROS Container 专门为读操作进行了优化设计,且其中的数据是经过了排序和压缩处理的, 即每个磁盘页上不会有空白空间, 而传统的数据库一般会在每页上预留空间以便日后的insert 操作来使用。
多种排序方式的冗余存储
为了高可用性和备份恢复的需要, Vertica 会按照不同的排序方式对数据做冗余存储,这不但避免了大量的日志操作,也为查询带来了便利。Vertica 的查询优化器会自动选择最优的排序方式来完成特定的查询。
并行无共享设计
Vertica 支持完全无共享海量并行存储( MPP)架构,随着硬件Server 的增加,多个CPU并行处理,性能也可以得到线性的扩展,这样用户使用廉价的硬件就可以获得较高的性能改善。
其他管理特征
除了有优越的性能以外, Vertica 在数据库管理方面也进行了非常人性化的设计。Vertica Database Designer 是一个界面化的日常管理工具, 并且能为用户作出详尽的DB层物理设计方案,大大减少了日后的性能调优方面的开销。
Vertica 通过K-Safety 值的设置,完成了数据库的备份恢复机制,并保证了高可用性。对于数据库中的每个表每个列, Vertica 都会在至少K+1 个节点上存储,如果有K个节点宕机,依然能够保证Vertica DB 是完整可用的;当损坏的节点恢复时, Vertica 自动完成节点间的热交换,把其他节点上的正确数据恢复过来。通过这种机制也保证了Vertcia 库的节点数目可以自由伸缩而不会影响到数据库的操作。
Vertica 通过两种技术来实现在线的持续数据装载而不会影响到数据库的访问。Vertica 通常运行在快照隔离(Snapshot Isolation)模式下,该模式下查询读取的是最近的一致的数据库快照,这个快照是不能被并发的update 或delete 操作更改的,因此查询操作也不需要占用锁, 这种方式保证了数据装载(insert)和其他查询能互不干扰。另外,Vertica
可以把数据直接装载到WOS 结构中,WOS 中的数据是不排序或索引的,所以装载速度会很快,然后再由Tuple Mover 进程在后台把数据移入ROS 中,由于TupleMover 的操作是大块读取(bulk-load)的,所以性能也很好。
主要局限
不支持SQL 存储过程及函数, 用户需通过UDFs( User Defined Function ,基于C++)来自定义函数或过程。软件授权按原始未经压缩的裸数据量计算。列存储的一些劣势,复杂查询等性能不理想。对内存有比较高的要求。在国内还没有成功案例。
Sybase IQ
基础架构
SYBASEIQ是Sybase公司推出的特别为数据仓库设计的关系型数据库。SYBASE IQ的架构与大多数关系型数据库不同, 它特别的设计用以支持大量并发用户的即席查询。其设计与执行进程优先考虑查询性能, 其次是完成批量数据更新的速度。而传统关系型数据库引擎的设计既考虑在线的事务进程又考虑数据仓库(而事实上,往往更多的关注事务进程) 。
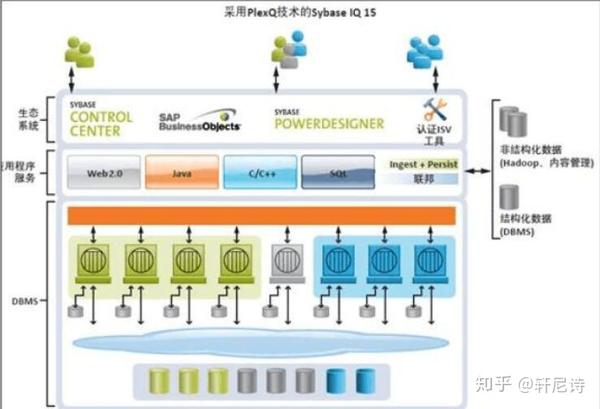
Sybase 在2010 年推出的Sybase IQ 15.3 就采用了全共享架构的PlexQ 技术,该技术重新定义了企业范围的业务信息,全共享架构可轻松支持涉及海量数据集、海量并发用户数和独特工作流程的多种复杂分析样式,大大增加了其效益。与其他MPP 解决方案不同,SybaseIQ 的PlexQ 网格技术能够动态管理可轻松扩展并且专用于不同组和流程的一系列计算与存储资源中的分析工作量, 从而使其能够以更低的成本更轻松地支持日益增长的数据量以及快速增长的用户社区。Sybase IQ 15.4 采用业内领先的MPP 列式数据库和最先进的数据库内分析技术, 并革命性地加入MapReduce 与Hadoop 集成, 以应对大数据时代的分析挑战, 开启洞察关键业务的能力。Sybase IQ 15.4 正在打破数据分析的壁垒,彻底改变―大数据分析‖领域。基于成熟的PlexQ 技术构建的Sybase IQ 采用下图所示的三层构架:
基本层:数据库管理系统(DBMS) ,这是一个全共享MPP 分析DBMS 引擎,是SybaseIQ 最大的独特优势。
第二层:分析应用程序服务层,其提供C++ 和Java 数据库内API ,并可实现与外部数据源的集成和联邦;包括四种与Hadoop 的集成方法。
顶层: Sybase IQ 生态系统,由四个强大且不同的合作伙伴和认证ISV 应用程序组成。基于这种PlexQ 技术, Sybase IQ 15.4 将大数据转变成可指挥每个人都行动的情报信息,从而在整个企业的用户和业务流程范围内轻松具备大数据的分析能力。
主要特性
Sybase IQ( 15.4)的关键特性:
1. 更强的数据管理
大量增强的功能改善了Sybase IQ 的数据管理、部署和可维护性。更快速的批量加载: 批量加载数据通过ODBC 和JDBC 接口插入到Sybase 中,从而实现具有更高可扩展性的应用程序,同时可极大提高加载性能。更出色的文本压缩: 更出色地对VARCHAR 、VARBINARY、CHAR 和BINARY 压缩可实现以更高效率、更低成本部署高性能文本分析应用程序,同时极大提高压缩速率。
2. 丰富的应用程序
Sybase IQ 15.4 增加了一系列API 和工具, 用于创建在数据库内运行的高级分析算法,并且能通过PlexQ 网格能充分利用大规模并行处理的能力。
支持自带Map Reduce 的表参数化用户自定义函数(UDF) —— 这是Sybase IQ 的本地应用程序编程接口,可使应用程序编程人员在Sybase IQ 数据库服务器内构建和部署C++库。使用这些API 可实现专有算法或算法包,安全地位于Sybase IQ 内,通过在保存于Sybase IQ 数据库服务器中的数据附近执行,以快10 倍的速度返回结果。此框架可实现在Sybase IQ 中开发和部署MapReduce 程序,以分析涉及结构化、半结构化和非结构化数据格式的超大数据集。C++、Map 和Reduce 算法通过标准SQL 加以调用, 并且由Sybase IQ强大的查询引擎自动在PlexQ 网格中进行分发和并行化。
Hadoop 集成与联邦—— 将基于Hadoop 的分析的结果与运行于Sybase IQ 中的查询相集成。Sybase 是唯一一家提供4 种不同方法将标准SQL 查询(客户端联邦、ETL 处理、数据联邦和查询联邦)中的Hadoop 数据和分析与分析数据库相集成的厂商。Sybase IQ 15.4充分利用Hadoop 来识别海量结构化和非结构化数据集中的相关数据点, 然后将Hadoop 中的相关数据点集成到Sybase IQ 中,以便利用传统数据和来自其他数据源的结果集进行分析。
预测模型标记语言(PMML) 支持—— 通过Zementis 提供的认证插件,自动执行使用业界标准语言定义在SAS、SPSS、―R‖等工具以及其他流行预测工作平台产品中所创建的分析模型。充分利用流行的分析工具构建预测模型,自动执行在Sybase IQ 中部署的预测模型,并使用业界标准语言,以避免形成厂商捆绑。
― R‖ 集成: —— 用户可使用RJDBC 接口,以及流行的开源统计工具― R‖查询Sybase IQ数据库。此外,用户还可以将来自Sybase IQ 的―R‖库作为SQL 查询中的函数调用加以执行,并返回结果集。
数据库内分析库
更新的数据库内统计和数据挖掘库(来自Fuzzy ? Logix 的DBLytix): 在Sybase IQ 内运行的高级分析、统计和数据挖掘算法库。Sybase IQ 15.4 中的更新可使该库充分利用一些数据挖掘算法中的MapReduce API 进行大规模并行处理,并且包含多种新函数,例如支持向量机、神经网络和Adaptive Boosting。
扩展的生态系统
Sybase IQ 还非常适合面向大数据分析的端到端全面解决方案。重要的工具和互补的合作伙伴产品可在以下方面提供帮助:
Sybase PowerDesigner? 16.1 参考架构生成器: 可通过在实施Sybase IQ 数据仓库和数据集市时生成最佳硬件配置,快速实现价值。
Sybase Control Center(SCC) : 改进方面包括大量管理功能,例如过程、函数、UDF( TPF 和JavaEE )及文本索引。用户能够更轻松地管理SCC 中频繁使用的功能, 以及更轻松地部署内置、外部和文本数据库内分析。此外该版本还包含了新的SQL 执行窗口,该窗口可实现易于测试的特定SQL 例程。已通过SAP?BusinessObjects认证: Sybase IQ 15.4 已通过认证,可与SAP BusinessObjects Business Intelligence Platform 4.0 和SAP Business Objects Data Services 4.0 配合使用,以提供丰富的端到端业务分析框架。
主要局限
Sybase IQ MPP 是Share-Disk 架构增加硬件,无法线性的提升数据库性能。列存储的一些劣势,装载速度,复杂查询等性能不理想。插入操作上表级锁,影响数据导入时影响表上的并发操作。
Teradata Aster Data
Teradata 天睿公司的Aster Data 分析平台是市场领先的大数据分析解决方案。AsterData 分析平台嵌入了MapReduce,对新数据源和多结构数据类型进行更深入的分析处理,提供具有突破性的性能和可扩展性的分析能力。Aster Data 解决方案利用Aster Data 专利SQL-MapReduce 来并行处理数据和应用程序,可在大范围内提供丰富的分析洞察。
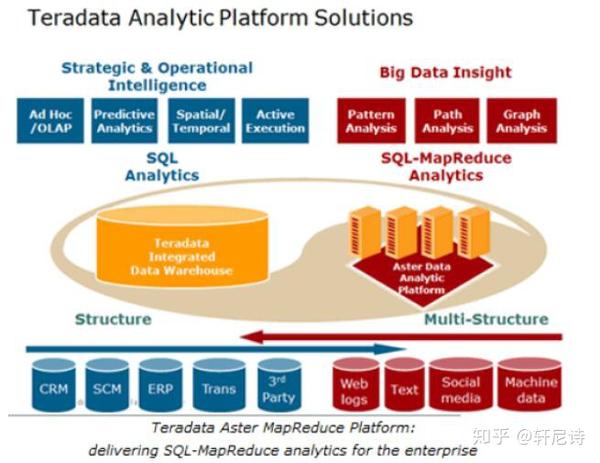
主要特性
TD Aster Data 有如下技术特点:
Shared-nothing 架构海量数据库采用最易于扩展的Shared-nothing 架构,每个节点都有自己的操作系统、数据库、硬件资源,节点之间通过网络来通信。
S Q L –MapReduce
SQL-MapReduce 是Aster Data 公司的专利, 在同类技术中(Greenplum)属于领先地位。
SQL-MapReduce 框架可以使数据科学家和商业分析师对复杂的信息进行快速调查分析,允许一组关联计算机(计算机群集)使用软件语言(如Java、C#、Python、C++ 和R)并行进行程序表达,然后通过标准SQL 激活(调用)使用。
基于MPP 的并行分析平台,第一个大规模并行分析平台,借助S Q L -MapReduce 支持嵌入式分析应用程序,使企业能显著加快TB 乃至PB 级数据的处理,为提供新的交互性大数据应用带来了无数机会可视化集成开发环境第一个可视化集成开发环境(Aster Data Developer Express) ,拥有立即可用的SQL-MapReduce 模块( Aster Data Analytic Foundation 的一部分),使大数据分析更快、更简单。
动态负载管理( Dynamic Mixed Workload Management )
支持最细粒度的负载均衡管理机制。多种容错、自动恢复机制Aster Data nCluster 的设计彻底地避免了由于硬件和软件故障、用户或管理员的错误以及本地或站点的破坏引起的意外停机。
此外,现场管理的独特功能尽量减少或完全避免了计划停机。倘若出现了硬件和软件故障,ROC(面向修复计算)技术便在在线数据重新分配中提供了大规模容错性的实时修复。同时, 它允许在查询、在线备份和修复、在线复原和在线向外扩展过程中进行下载或导出,这样就不再需要考虑停工计划预算了。支持行、列压缩存储技术。
主要局限
在国内目前没有发现有实施案例,没有较完整的解决方案,应用市场较小;产品还不够成熟,如表管理可能导致性能问题;混合负载控制能力较差。
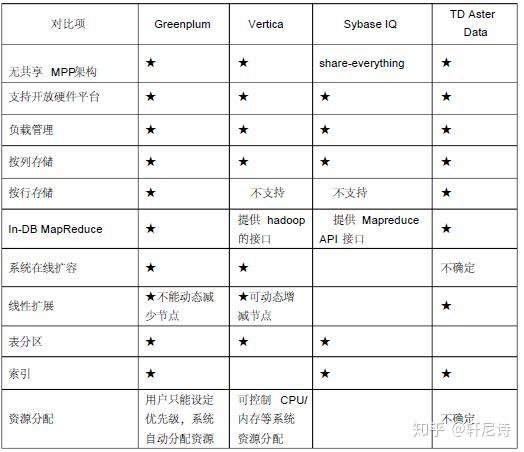
对比分析
优势与劣势
分布式数据库系统的优势
分布式数据库系统是在冀中是数据库系统的基础上发展来的,比较分布式数据库系统与集中式数据库系统,可以发现分布是数据库系统具有下列优点:
1.更适合分布式的管理与控制。分布式数据库系统的结构更适合具有地理分布特性的组织或机构使用,允许分布在不同区域\不同级别的各个部门对其自身的数据实行局部控制。例如:实现全局数据在本地录入、查询、维护,这时由于计算机资源靠近用户,可以降低通信代价, 提高响应速度, 而涉及其他场地数据库中的数据只是少量的,从而可以大大减少网络上的信息传输量;同时,局部数据的安全性也可以做得更好。
2.具有灵活的体系结构。集中式数据库系统强调的是集中式控制,物理数据库是存放在一个场地上的,由一个DBMS集中管理。多个用户只可以通过近程或远程终端在多用户操作系统支持下运行该DBMS来共享集中是数据库中的数据。而分布式数据库系统的场地局部DBMS的自治性,使得大部分的局部事务管理和控制都能就地解决,只有在涉及其他场地的数据时才需要通过网络作为全局事务来管理。分布式DBMS可以设计成具有不同程度的自治性,从具有充分的场地自治到几乎是完全集中式的控制。
3.系统经济,可靠性高,可用性好。与一个大型计算机支持一个大型的冀中是数据库在加一些进程和远程终端相比, 由超级微型计算机或超级小型计算机支持的分布式数据库系统往往具有更高的性价比和实施灵活性。分布式系统比集中式系统具有更高的可靠性和更好的可用性。如由于数据分布在多个场地并有许多复制数据, 在个别场地或个别通信链路发生故障时,不致于导致整个系统的崩溃,而且系统的局部故障不会引起全局失控。
4.在一定条件下响应速度加快。如果存取的数据在本地数据库中,那末就可以由用户所在的计算机来执行,速度就快。
5.可扩展性好,易于集成现有系统,也易于扩充。对于一个企业或组织,可以采用分布式数据库技术在以建立的若干数据库的基础上开发全局应用,对原有的局部数据库系统作某些改动,形成一个分布式系统。这比重建一个大型数据库系统要简单,既省时间,又省财力、物力。也可以通过增加场地数的办法,迅速扩充已有的分布式数据库系统。
分布式数据库系统的劣势
分布数数据库系统有如下劣势:
1.通信开销较大,故障率高。例如,在网络通信传输速度不高时,系统的响应速度慢,与通信县官的因素往往导致系统故障, 同时系统本身的复杂性也容易导致较高的故障率。当故障发生后系统恢复也比较复杂,可靠性有待提高。
2.数据的存取结构复杂。一般来说,在分布时数据库中存取数据,比在集中时数据库中存取数据更复杂,开销更大。
3.数据的安全性和保密性较难控制。在具有高度场地自治的分布时数据库中,不同场地的局部数据库管理员可以采用不同的安全措施,但是无法保证全局数据都是安全的。安全性问题式分布式系统固有的问题。因为分布式系统式通过通信网络来实现分布控制的,而通信网络本身却在保护数据的安全性和保密性方面存在弱点,数据很容易被窃取。分布式数据库的设计、场地划分及数据在不同场地的分配比较复杂。数据的划分及分配对系统的性能、响应速度及可用性等具有极大的影响。不同场地的通信速度与局部数据库系统的存取部件的存取速度相比,是非常慢的。通信系统有较高的延迟,在 CPU上处理通信信息的代价很高。分布式数据库系统中要注意解决分布式数据库的设计、查询处理和优化、事务管理及并发控制和目录管理等问题。
未来趋势
1.数据库会随着业务云化,未来一切的业务都会跑在云端,不管是私有云或者公有云,运维团队接触的可能再也不是真实的物理机,而是一个个隔离的容器或者计算资源,这对数据库也是一个挑战,因为数据库天生就是有状态的,数据总是要存储在物理的磁盘上,而数据移动的代价比移动容器的代价可能大很多。
2.多租户技术会成为标配,一个大数据库承载一切的业务,数据在底层打通,上层通过权限,容器等技术进行隔离,但是数据的打通和扩展会变得异常简单,结合第一点提到的云化,业务层可以再也不用关心物理机的容量和拓扑,只需要认为底层是一个无穷大的数据库平台即可,不用再担心单机容量和负载均衡等问题。
3.OLAP和OLTP 业务会融合,用户将数据存储进去后,需要比较方便高效的方式访问这块数据,但是OLTP 和OLAP在SQL优化器/ 执行器这层的实现一定是千差万别的。以往的实现中,用户往往是通过ETL 工具将数据从OLTP数据库同步到OLAP数据库,这一方面造成了资源的浪费,另一方面也降低了OLAP的实时性。对于用户而言,如果能使用同一套标准的语法和规则来进行数据的读写和分析,会有更好的体验。
4.在未来分布式数据库系统上,主从日志同步这样落后的备份方式会被Multi-Paxos / Raft 这样更强的分布式一致性算法替代,人工的数据库运维在管理大规模数据库集群时是不可能的,所有的故障恢复和高可用都将是高度自动化的。
参考资料
- php中文网, 分布式数据库是什么?有什么优缺点-mysql教程-PHP中文网,2019-01-21
- 电子发烧友网,分布式数据库系统的优缺点, 分布式数据库系统的优缺点-电子发烧友网,2019-01-04
- 分布式系统中的多数据库远程访问 - 计算机应用研究 - 2001, 18(1)
- 实时数据库及其在分布式系统中的应用 中国科协第五届青年学术年会——陕西卫星会议 - 2005
- 论分布式系统的网络漏洞及解决方案 - 中国民航飞行学院学报 - 2004, 15(2)
- 分布式系统数据时序更新方法 - 软件工程 - 2016, 19(5)


