学习算法的意义?
18 个回答

算法完全不是一个单调的知识,它可以为我们的生活,带来更多新奇的思考方向~
「策略问题」只是一个通俗的说法,「算法问题」才是一个更加恰当的说法。中学时苦苦钻研信息学竞赛,注定将是我人生最难忘的经历之一。在那段时间里,我第一次听说了「算法」这个词,并且有机会接触了大量经典的算法问题。我从中选择了 32 个自认为最漂亮的问题,希望能让大家体会到算法的魅力。
1. 将一个人的眼睛蒙上,然后在他前面的桌子上摆放 52 张扑克牌,并告诉他里面恰好有 10 张牌是正面朝上的。要求他把所有牌分成两堆,使得这两堆牌里正面朝上的牌的张数一样多。他应该怎么做?
首先把扑克牌分成两堆,一堆 10 张,一堆 42 张。当然,那 10 张正面朝上的牌并不见得正好都在小的那一堆里,不过很容易看出,小的那一堆里有多少背面朝上的,大的那一堆里就会有多少正面朝上的。因此,最后只需把小的那一堆里的所有牌全部翻过来,目的就达成了。
2. 某种药方要求非常严格,你每天需要同时服用 A、B 两种药片各一粒,不能多也不能少。这种药非常贵,你不希望有任何一点的浪费。一天,你打开装药片 A 的药瓶,倒出一粒药片放在手心;然后打开另一个药瓶,但不小心倒出了两粒药片。现在,你手心上有一粒药片 A,两粒药片 B,并且你无法区别哪个是 A,哪个是 B。你如何才能严格遵循药方服用药片,并且不能有任何的浪费?
再取出一粒药片 A,也放在手心上,因而你的手心上就有两片 A 和两片 B 了。把手上的每一片药都切成两半,分成两堆摆放。现在,每一堆药片恰好包含两个半片的 A 和两个半片的 B。一天服用其中一堆即可。
3. A、B 两人分别在两座岛上。B 生病了,A 有 B 所需要的药。C 有一艘小船和一个可以上锁的箱子。C 愿意在 A 和 B 之间运东西,但东西只能放在箱子里。只要箱子没被上锁,C 都会偷走箱子里的东西,不管箱子里有什么。如果 A 和 B 各自有一把锁和只能开自己那把锁的钥匙,A 应该如何把东西安全递交给 B?
首先 A 把药放进箱子,用自己的锁把箱子锁上。B 拿到箱子后,再在箱子上加一把自己的锁。箱子运回 A 后,A 取下自己的锁。箱子再运到 B 手中时,B 取下自己的锁,获得药物。
这是应用密码学中一个非常有用的技巧,它可以用于很多协议问题,比方说抛硬币问题。如果 A、B 两人远隔千里,他们怎样才能采用抛掷硬币的方法来解决争端?当然,A 可以自己先抛掷,然后把结果告诉 B,不过前提是 B 必须要能完全相信 A 才行。如果两人互相之间都不信任,我们还有办法吗?其中一种办法是,A 先准备两个盒子,每个盒子里各放一张纸条,上面分别写着「正面」和「反面」。然后,A 在两个盒子上各加一把锁,并把这两个盒子都寄给 B。当 B 收到这两个盒子后,他显然没法判断出哪个盒子装着「正面」,哪个盒子装着「反面」,只好随机选择一个盒子。这个盒子里面的字就表示抛掷硬币的结果。B 把这个盒子回寄给 A,然后让 A 来公布结果。B 怎么知道 A 是否诚实地公布了结果呢?很简单,B 手里不是还有另外一个盒子吗?B 可以向 A 索要另外一个盒子的钥匙,然后把它打开来,看看里面装的是否是另一种结果就行了。
不过,这个协议有一个巨大的漏洞:A 可以在寄盒子之前,在两个盒子里都装进「正面」,然后不管 B 寄回来的是哪个盒子,都骗他说「你选中的是反面」。那怎么办呢?于是,刚才的递药方法就派上用场了。B 选完盒子以后,在这个盒子上再加一把自己的锁,然后把盒子寄回给 A。A 收到盒子后,发现自己没法改动盒子里的内容,只好解开自己的锁,把盒子再寄给 B。最后,B 打开盒子,看到里面写的是什么,从而得出硬币抛掷的结果。B 应当把这张纸条寄给 A,让 A 知晓硬币抛掷的结果,并让 A 验证这张纸条确实是 A 当初自己写的那张;然后,A 也应当把另一个盒子的钥匙寄给 B,让 B 验证这两个盒子里的纸条确实是一张「正面」一张「反面」。

促使人类进步的不是新发明的算法有多牛,而是人类面临的问题得以解决!
随着计算机和人工智能的发展,算法这个词似乎变得很重要,甚至被很多人奉为解决问题的唯一办法。有多少科研工作者,在遇到一个课题或问题之后,第一件事就是去寻找一个厉害的算法,好像寻找救世主一样。感谢提出这个问题的人,让我们有辩证思考这个问题的机会。
纵观人类进步的历史,牛顿是通过算法发现万有引力的吗,富兰克林是通过算法发现电的吗,都不是。尽管那时可能没有算法,但起码能说明:算法不是人类解决问题的唯一途径。
天下没有免费的午餐定理告诉我们:在没有问题对象的先验知识情况下,任何算法都不会优于随机枚举算法。可见,问题能否得到解决的关键,在于对问题的本质(即先验知识)了解得是否足够透彻。而算法,只不过是一种利用已有先验知识来探索、归纳更多先验知识的一种工具罢了。
现在所有的数据模型都面临着一个问题:贝叶斯误差。这导致人类几乎不可能完全依赖数据模型,不然容易犯错。也许这就是强行利用算法从数据中总结知识带来的后果吧。并不是说这样做就一定不对,甚至很多时候只能这样做,但是我们得知道,这样做有什么坏处。
对于科研问题的解决,可能存在一个更加正确的思路:解决问题的关键在于发现问题的本质,而对于问题本质的探索,可以利用算法,也可以不利用算法(如通过观察、实验、归纳、推理、类比等)。然而,往往利用算法是最简单的那条路。

本文转自 审计中计算机与数学的艺术——查找对方科目中的递归、回溯与剪枝算法(零基础算法入门科普-Python) - 夜莺的文章 - 知乎,其中讲述了算法在财务审计中一个基本的应用场景,以体现算法的意义
1.引言
做过审计工作的读者都知道,对方科目是账目分析要用到的重要数据,比如勾稽分析时需要精确的对方科目和金额分析账款的去向
而客户在给我们序时账时,其中的数据往往是不带对方科目的,需要我们自行计算
之前用AudTool(使用VSTO开发)的对方科目精确查找模式,让我还算性能不错的电脑在项目办公室里卡死了足足15分钟,当时我就非常疑惑——一张凭证一般只有几条数据,算个对方科目至于这么卡吗?
在结束了那年年报审计的工作后,为了不再在关键时刻掉链子,我决定自己开发一个更快的版本(令人震惊的是,我没有找到有人开发过更好的版本,甚至很多审计师都不知道对方科目可以自动生成),其中遇到的算法问题感觉很适合作为算法入门科普,于是就有了这篇文章
本文2~5节引入了一些算法在审计、会计上的应用案例和经典问题,为没有接触过算法的读者做铺垫,从 6.为什么算法必须优化? 开始讲述核心问题,本文代码使用Python3语言,并对代码做了详细的注释,编程小白也能快速理解
需要注意的是,本人并非专业的计算机相关工作者,还请各位读者帮忙纠正文中的一些错误
2.本问题的会计知识背景
如果你是没有做过审计或者会计工作的读者,可以先听我说说后面那些问题的应用场景,避免不知道算法有什么意义
在会计记账时,记一次帐需要记录两个方向(借和贷),两个方向的金额是相等的
比如我们使用银行存款购买1000元的原材料,会减少1000元的银行存款,增加1000元的原材料,记账会记成这样
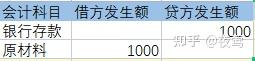
可以发现,借方加起来和贷方加起来是相等的,且借方和贷方是对应的,这种“对应”就是对方科目,这里的对方科目就很明显了
(对会计感兴趣的详见: 会计中关于借贷怎么区分,感觉好乱啊,求指导?? - 夜莺的回答)


看到这,你会觉得查找对方科目是很简单的事情,找另一边金额一样的不就完事了?可在很多情况下它们会出现一对多、多对多、甚至不在另一边而是负数在同一边的情况,如:


可以发现想找到对方科目并不是一件简单的事,接下来我们进入正题——怎么通过数学办法编写脚本找到对方科目
3.这个问题为什么深奥——由两数之和问题说起
我们从一对多开始讲起,把一对多这个问题简化下,比如固定成一对二

这样问题就可以简化成:
在 [60,40,20,10] 这个列表里,哪两个两两相加可以得到 100 和 30?
稍作思考就可以发现一个最简单的办法——穷举所有两两相加的情况,得到相加等于100 和 30 的两个数
def twoSum(nums,target): #定义一个名为twoSum的函数,它需要提供nums(一组数字)和target(要求的相加结果)两个信息来计算结果
n = len(nums) #得到你提供名为nums的一组数字中有多少个数字,结果保存到名为n的变量,如果nums是[60,40,20,10],那n=4
for i in range(n): #从0开始循环到n,循环到0到n的哪里保存到名为i的变量,因为python列表是从0开始的,这样方便从列表中取值
for j in range(i + 1, n): #在循环中循环,从 i+1 开始循环到n,这样做是为了跳过自己和已经求过的数,不理解可以看后面图例,循环到第几个保存到名为j的变量
print(nums[i],"+",nums[j],"=",nums[i] + nums[j]) #为便于理解,打印穷举的结果
twoSum([60,40,20,10],100) #调用函数,传入需要的两个参数
'''
运行结果如下
60 + 40 = 100 60 + 20 = 80 60 + 10 = 70 40 + 20 = 60 40 + 10 = 50 20 + 10 = 30
'''
#加一个判断和返回,让得到结果后结束计算并返回要的结果即可
def twoSum2(nums,target): #定义一个名为twoSum的函数,它需要提供nums(一组数字)和target(要求的相加结果)两个信息来计算结果
n = len(nums) #得到你提供名为nums的一组数字中有多少个数字,结果保存到名为n的变量,如果nums是[60,40,20,10],那n=4
for i in range(n): #从0开始循环到n,循环到0到n的哪里保存到名为i的变量,因为python列表是从0开始的,这样方便从列表中取值
for j in range(i + 1, n): #在循环中循环,从 i+1 开始循环到n,这样做是为了跳过自己和已经求过的数,不理解可以看后面图例,循环到第几个保存到名为j的变量
if nums[i] + nums[j] == target: #判断nums的第i项与nums的第j项相加是否等与target
return [nums[i],nums[j]] #如果是,返回这两个数
twoSum2([60,40,20,10],100) #调用函数,传入需要的两个参数
'''
返回结果如下
[60,40]
'''

如果你理解了这个案例,那么恭喜你学会了LeetCode第一题的解法其一
LeetCode第一题:两数之和
有人相爱,有人夜里开车看海,有人leetcode第一题都做不出来。
看到这里你可能觉得算法还挺简单嘛,让我们回到原来的问题:一对多的情况如何查找?——它可能是两数之和、可能是三数之和、也可能是四数之和

用前面的办法是不能解答的,因为你不知道答案由几个数相加,所以你需要用一种方法,遍历所有可能出现的情况
4.排列
前面遇到的问题变成了:在 [70,10,40,30,20] 中,任意长度排列组合,哪些数加起来会得到80和100? 注:不与任何数相加,自己就是目标数的话就直接算是对方科目了,这种情况也是答案
要说遍历所有可能出现的情况,你应该想到了排列,python的permutations函数可以完成这个功能
用法:itertools.permutations(要排列的列表, 排列的长度)
[70,10,40,30,20] 五个数太长了,这里用 [1,2,3] 三个数举例
import itertools #导入函数
list1 = [1,2,3] #定义测试用的数据
answer = [] #定义用于保存结果的空列表
for i in range(1,len(list1)+1): #因为按长度1到3全都排列一次才能遍历所有情况,所以套一个次数循环
for j in itertools.permutations(list1,i): #调用permutations函数
answer.append(list(j)) #写入结果至列表
print (answer) #打印列表
'''
排列结果:[[1], [2], [3], [1, 2], [1, 3], [2, 1], [2, 3], [3, 1], [3, 2], [1, 2, 3], [1, 3, 2], [2, 1, 3], [2, 3, 1], [3, 1, 2], [3, 2, 1]]
'''到这一步,恭喜你学会了Leetcode第46题的解法其一,那题甚至还简单一点,不用所有长度都排列一次
LeetCode第46题:全排列
看到返回结果你会想不太对啊,像 [1,2]和[2,1],[1,2,3]和[3,2,1] 这种不都是一样的么,这算的时候怎么分得清楚啊
那恭喜你进入第47题
5.去重
想要去重,首先要知道两点
python可以用sort()函数给列表的元素进行排序,如果两个列表里面的元素是一样的,那排序后整个列表就都是一样的
python判断是可以判断一个元素是否在列表里的,我们可以使用这个思路来去重,具体做法还是嵌套循环
list1 = [[1, 2], [1, 3], [2, 1], [2, 3], [3, 1], [3, 2], [1, 2, 3], [1, 3, 2], [2, 1, 3], [2, 3, 1], [3, 1, 2], [3, 2, 1]]
#定义测试用的列表
for i in range(len(list1)): #做一个次数循环,目的是记录循环项的位置,方便从list1中取数并把排序后的元素覆盖回去
i_item = list1[i] #从列表中取出当前循环位置的元素
i_item.sort() #对取出的元素排序
list1[i] = i_item #把排序后的元素覆盖回去
new = [] #新建一个空列表,把没有记录过的元素写进来
for i in list1:
if i not in new: #判断当前循环的元素没有被记录过
new.append(i) #如果没有被记录过,则写入新列表,如果被记录过就不会写入,这样可以得到不重复的元素
print (new)
'''
执行结果:[[1, 2], [1, 3], [2, 3], [1, 2, 3]]
'''如果你看懂了这个案例,恭喜你学会了Leetcode第47题的解法其一,那题也是简单一点,不用排序,直接去重就行了
LeetCode第47题:全排列 II
至此我们的问题是不是解决了呢?我们来试试
在 [70,10,40,30,20] 中,任意长度排列组合,哪些数加起来会得到80和100?
import itertools #导入函数
def duifangkemu(list1,target):
answer = [] #定义用于保存全排列结果的空列表
for i in range(1,len(list1)+1): #因为按长度1到n全都排列一次才能遍历所有情况,所以套一个次数循环
for j in itertools.permutations(list1,i): #调用permutations函数
answer.append(list(j)) #写入排列结果至列表
an = [] #新建一个空列表,用于存储相加符合目标值的结果
for i in answer:
if sum(i) == target:
an.append(i) #写入相加等于目标的元素
list1 = an #重新定义列表名字,因为前后命名不一样所以得重新定义下,这是我写的太随意的问题
for i in range(len(list1)): #做一个次数循环,目的是记录循环项的位置,方便从list1中取数并把排序后的元素覆盖回去
i_item = list1[i] #从列表中取出当前循环位置的元素
i_item.sort() #对取出的元素排序
list1[i] = i_item #把排序后的元素覆盖回去
new = [] #新建一个空列表,待会把没有记录过的元素写进来
for i in list1:
if i not in new: #判断当前循环的元素没有被记录过
new.append(i) #如果没有被记录过,则写入新列表,如果被记录过就不会写入,这样可以得到不重复的元素
return new
print(duifangkemu([70,10,40,30,20],80)) #测试总和为80的情况
print(duifangkemu([70,10,40,30,20],100)) #测试总和为100的情况
'''
执行结果
[[10, 70], [10, 30, 40]]
[[30, 70], [10, 20, 70], [10, 20, 30, 40]]
'''看样子是解决了,本文完结?
恭喜你上当了,问题并没有解决,真正的问题现在才开始

6.为什么算法必须优化?
前面我们举例的会计凭证贷方只有5个数据,任意长度的排列组合有325种,算325个数对计算机来说当然是小菜一碟
但在结账的时候,一张会计凭证会有长达几十条数据,假设现在结账的凭证贷方有11条数据,那总共有多少种任意的排列组合?
108505111(1亿多)种!
我16G内存的电脑,32位编辑器只跑得倒10个数据的排列组合,而64位也只能跑到11个,再多会导致内存溢出
你可以截取前面的代码测试不同位数的排列组合有多少个,并试试自己的电脑在算多少位时会卡死
import itertools #导入函数
def boom(list1):
answer = [] #定义用于保存全排列结果的空列表
for i in range(1,len(list1)+1):
a = list(itertools.permutations(list1,i)) #调用permutations函数
answer.append(len(a))
print("组合个数:",sum(answer))
boom([1,2,3,4,5,6,7,8,9,10,11])
'''
运行结果
组合个数: 108505111
'''所以这样算的问题在哪呢?——函数只能直接给我们所有的排列结果,我们在后面要手动筛选出重复的才能得到答案
但排列结果太多导致内存溢出,搞得我们筛都没法筛
所以,要有一种办法,在排列时就筛掉重复的元素,或者说不对重复的元素进行排列,以此减少排列结果的数量,避免搞出几亿种组合导致内存溢出
7.递归算法
我们现在的问题变成了
找到一种办法,在排列时就筛掉重复的元素,或者说不对重复的元素进行排列,以此减少排列结果的数量,避免搞出几亿种组合导致内存溢出 人家给的全排列函数我们肯定是动不了的,虽然我不喜欢造轮子,但为了优化我们得自己写一个
写这个东西需要用到回溯算法,在说回溯之前,先要知道什么是递归
我们回到排列问题,并把问题简化一下,之前我们是任意长度排列,现在我们按列表本身的长度全排列
我们再来统计一下,按列表本身的长度全排列会有多少种结果
import itertools
def lens(list1):
print(len(list(itertools.permutations(list1,len(list1))))) #调用permutations函数
lens([1,2,3,4,5])
'''
运行结果:120
'''可以发现,结果就是长度的阶乘,也就是5!,(5×4×3×2×1,这个东西概率论应该讲过)
我们只要理论上的个数,排列完再统计的问题我们已经体会过了,数字一多就会内存溢出,那就写个代码算阶乘吧
可以发现,阶乘的每一次运算都是n*(n-1),我们是否可以把n设为函数的传入参数,然后玩俄罗斯套娃?
def factorial(n):
return n * factorial(n-1)
print(factorial(3))
'''
运行结果:报错, maximum recursion depth exceeded
这是递归没有设置暂停条件造成的,它一直n-1,给乘到负数去了,一直乘直到超过了可以计算的能力,而阶乘乘到1就可以停止了,所以得加个停止条件
'''
def factorial(n):
if n <= 1: #暂停条件,别忘了0的阶乘是1,所以判断条件是小于等于,这个忘了概率论老师就要吐血了
return 1
return n * factorial(n-1)
print(factorial(3))
'''
运行结果:6
这个“暂停条件”的概念很重要,后面都需要用到
它的运算过程展开是这样的:
=返回 3 * factorial(2) #factorial(2)是自己调用自己,并传入参数2,这个2的来源是n-1
=返回 3 * 2 * factorial(1) #展开,factorial(2)的返回值为 2 * factorial(1)
=返回 3 * 2 * 1 #展开,因为有暂停条件判断,传入参数为1时,直接返回1,并且return后不会再执行后面的语句,所以不再调用自身
= 6 #计算完成,返回结果
'''这样不断调用自身直到暂停条件触发的过程,就是递归
8.回溯入门:使用递归自己写一个全排列以便进行优化
尝试为[1,2,3]写一个自身长度的全排列
到这里要说的东西就开始抽象起来了,好在这是一个经典问题,网上有很多教程,可以直接去看
LeetCode全排列问题题解
但他们讲的都过于专业了,萌新去看可能会一脸懵逼,我们现在只是不想爆内存而已。所以我仍然会尽量帮助各位理解这个问题
我是不喜欢去讲冗长的定义和概念问题的,回溯问题练熟以后模板自在心中,大家直接把下面这个答案复制一下自己跑一遍,配合后面的图,尝试理解回溯算法中的“树”、“节点”和“返回”
注:回溯就是指下文中”返回上一节点“的过程
def permute(list1):
out = []
def dfs(list1, jiedian):
print('传入:list1=',list1,",节点=",jiedian)
if len(jiedian) == len(list1):
out.append(jiedian)
print('!此时两个列表长度相等,写入 节点 :',jiedian,'进入out列表')
print('进入循环')
for i in range(len(list1)):
if list1[i] in jiedian:
print('第',i+1,'次递归,跳过,因为list1[',i,']=',list1[i],'在 节点 里了')
print('pass')
continue
print('第',i+1,'次递归,给 节点 加上一个',list1[i])
dfs(list1, jiedian+[list1[i]])
print('3次递归完成,结束递归,返回上一节点')
dfs(list1, [])
return out
print(permute([1,2,3]))对打印结果做个缩进,再配合这张图就很好理解了,为便于对回溯的理解,为返回的方向做出了特别标注,也可以把返回理解为递归停止,停止后继续执行上一层还没完成的循环:


传入:list1= [1, 2, 3] ,'节点'= []
进入循环
第 1 次递归,给'节点'加上一个 1
传入:list1= [1, 2, 3] ,'节点'= [1]
进入循环
第 1 次递归,跳过,因为list1[ 0 ]= 1 在'节点'里了
pass
第 2 次递归,给'节点'加上一个 2
传入:list1= [1, 2, 3] ,'节点'= [1, 2]
进入循环
第 1 次递归,跳过,因为list1[ 0 ]= 1 在'节点'里了
pass
第 2 次递归,跳过,因为list1[ 1 ]= 2 在'节点'里了
pass
第 3 次递归,给'节点'加上一个 3
传入:list1= [1, 2, 3] ,'节点'= [1, 2, 3]
!此时两个列表长度相等,写入 节点 : [1, 2, 3] 进入out列表
进入循环
第 1 次递归,跳过,因为list1[ 0 ]= 1 在'节点'里了
pass
第 2 次递归,跳过,因为list1[ 1 ]= 2 在'节点'里了
pass
第 3 次递归,跳过,因为list1[ 2 ]= 3 在'节点'里了
pass
3次递归完成,结束递归,返回上一节点
3次递归完成,结束递归,返回上一节点
第 3 次递归,给'节点'加上一个 3
传入:list1= [1, 2, 3] ,'节点'= [1, 3]
进入循环
第 1 次递归,跳过,因为list1[ 0 ]= 1 在'节点'里了
pass
第 2 次递归,给'节点'加上一个 2
传入:list1= [1, 2, 3] ,'节点'= [1, 3, 2]
!此时两个列表长度相等,写入 节点 : [1, 3, 2] 进入out列表
进入循环
第 1 次递归,跳过,因为list1[ 0 ]= 1 在'节点'里了
pass
第 2 次递归,跳过,因为list1[ 1 ]= 2 在'节点'里了
pass
第 3 次递归,跳过,因为list1[ 2 ]= 3 在'节点'里了
pass
3次递归完成,结束递归,返回上一节点
第 3 次递归,跳过,因为list1[ 2 ]= 3 在'节点'里了
pass
3次递归完成,结束递归,返回上一节点
3次递归完成,结束递归,返回上一节点
第 2 次递归,给'节点'加上一个 2
传入:list1= [1, 2, 3] ,'节点'= [2]
进入循环
第 1 次递归,给'节点'加上一个 1
以此类推,直到第一层递归3次请仔细理解这个过程,主要是”节点“和“返回”的操作,直到看懂下面这段删去了打印的答案
def permute(list1):
out = []
def dfs(list1, jiedian):
if len(jiedian) == len(list1): #因为这里是按自生长度排列,所以当长度为输入长度的时候为有效结果
out.append(jiedian)
for i in range(len(list1)):
if list1[i] in jiedian: #暂停条件,这种写法便于理解,但暂停条件的设置和之前算阶乘的写法不太一样
continue #在python中contiune会直接进入下一次循环,不执行后面的语句
#if list1[i] in jiedian:在找到目标后list1[i]注定在节点里,所以会跳过并停止这一层的递归
dfs(list1, jiedian+[list1[i]])
dfs(list1, [])
return out
print(permute([1,2,3]))看懂了的话,恭喜你正式步入了算法的大门,并且又上当了
这种解法只能解决不含重复数字的数组(但会计凭证中发生额相等的科目很常见的)

不信你输入 [1,1,2] 试试,直接排不出来


如果你理解了前面“节点”和“返回”的操作,可以发现很明显是跳过条件的问题,如果按内容跳过,来个重复的元素就全被误杀了,应该按位置跳过
可以打开PPT,尝试自己画一个正确的树
按位置跳过的话,思路是这样的


我们再回忆一下代码,看看怎么改
def permute(list1):
out = []
def dfs(list1, jiedian):
if len(jiedian) == len(list1):
out.append(jiedian) #顺带一提,得到答案后不用再等后面三次递归跳过再返回了,加个return直接跳过后面并返回就好
for i in range(len(list1)):
if list1[i] in jiedian: #问题出在这里,这里应该判断的是 本轮节点添加值 在列表的位置,而不是内容
continue
dfs(list1, jiedian+[list1[i]]) #我们在这里的 jiedian+[list1[i] 传入了 本轮节点添加值 的内容
dfs(list1, []) #那我们能不能传入添加值的位置呢?
return out
'''
答案是可以,让我们增加一个表示位置的传入值,位置很明显,就是i(前面还从list1把第i项取出来加给jiedian呢)
'''
def permute2(list1):
out = []
def dfs(list1, jiedian, weizhi): #加上一个名为weizhi的传入参数
if len(jiedian) == len(list1):
out.append(jiedian)
return #加个return,得到答案后就不用等后面递归全部跳过再返回了,会快一些
for i in range(len(list1)):
if i in weizhi: #判断条件改为 本轮添加节点的位置 是否被 列表weizhi 记录过
continue
dfs(list1, jiedian+[list1[i]], weizhi+[i]) # weizhi 的传入方法照着节点就行
dfs(list1, [], []) #调用时也要同时传入weizhi为空列表,和传入节点一样的
return out
print(permute2([1,1,2]))
'''
运行结果:[[1, 1, 2], [1, 2, 1], [1, 1, 2], [1, 2, 1], [2, 1, 1], [2, 1, 1]]
'''
这样纯真的写法是不是好理解多了?它在 LeetCode第46题:全排列中比permutations函数快一些


但我们面对的问题并没有突破性的进展,长度上去后该爆内存还得爆内存

9. 算的更快 和 不爆内存 的矛盾——时间复杂度 与 空间复杂度
去leetcode写两题会发现,很难在执行用时和内存消耗上同时打败更多人,这是为什么?
就拿搬砖举例吧,100块砖,一次搬两块,那要搬50次,得很久;如果一次搬50块砖,那两次就搬完了,可惜一般人搬不动(爆内存)
所以大多数情况下,时间复杂度 与 空间复杂度 是矛盾的,并且大多数情况下 时间复杂度的优化 更为重要,因为空间用完了就可以腾出来了,但时间过去了可没办法“回溯”。审计这种极其注重效率的工作也不喜欢等,可程序执行要提升速度可以写空间复杂度更高的算法并花钱加内存,审计项目要提升速度往往却不会给组里加够相应的“内存容量(人员)”,这是谁的锅呢?我不好说,但我们可以借助编程技术减少人员配置需求

为帮助大家理解,我们来想一个很简单的问题:
给定正整数 n ,计算 \sum_{i=1}^{n} i ,这个问题有两种方法可以解决
- 方法一:使用循环计算,则需要进行 n 次相加的操作,这样的时间复杂度确界就是 \Theta(\mathrm{n})
- 方法二:使用等差数列求和公式 \frac{n(n+1)}{2} 计算,只算一次就能得到结果,这样的时间复杂度确界就是 \Theta(\mathrm{1})
由此可以知道,递归越多,循环就越多,这两一多,时间复杂度就指数级上涨
10.剪枝入门——在排列中去重
别忘了我们的问题
找到一种办法,在排列时就筛掉重复的元素,或者说不对重复的元素进行排列,以此减少排列结果的数量,避免搞出几亿种组合导致内存溢出
在前面画的树中,我们可以很直观的发现,同一层的节点内容是一样的话,那后面的排列也都是一样的




知道这个后接下来要干啥就很明显了——判断同层的节点(也可以说是循环)中有没有已经排列过且内容一样的节点,有的话直接跳过
这样搞得想想怎么把这个判断条件加进去,有人可能想到了写个和out一样的列表,保存每次递归的节点,发现当前遍历的节点在列表里,就跳过
def permute2(list1):
out = []
used_jeidian = [] #新建一个空列表,保存已遍历过的节点
def dfs(list1, jiedian, weizhi):
if len(jiedian) == len(list1):
out.append(jiedian)
return
for i in range(len(list1)):
if i in weizhi:
continue
if jiedian+[list1[i]] in used_jeidian: #判断当前循环节点是否已遍历过,如果有,则跳过
continue #continue会跳过后面语句的执行,进入下一循环
used_jeidian.append(jiedian+[list1[i]]) #写入节点至已遍历过的节点
dfs(list1, jiedian+[list1[i]], weizhi+[i])
dfs(list1, [], [])
return out
print(permute2([1,1,2]))
'''
运行结果:[[1, 1, 2], [1, 2, 1], [2, 1, 1]]
看上去还不错
'''这样写 LeetCode第47题:全排列 II也能过,也比之前permutations函数排完去重要快得多,从792ms减少到了168ms,但标准解法是52ms,而且我们这种搞法输入长度长一点后我们这种写法会算得非常慢,别说在项目办公室让电脑卡死十五分钟了,卡到报告都出完了也算不出来
高情商:算法上还有很大优化空间;低情商:写的一拖史
你有没有想过,这样保存一个又一个的节点,和对列表本身进行任意长度的排列有什么区别?
比如 [1,1,2] 跳过重复的节点后的节点有 [[1], [1, 1], [1, 1, 2], [1, 2], [1, 2, 1], [2], [2, 1], [2, 1, 1]] ,这不是任意长度的排列是什么,这会导致 已遍历节点列表 非常长,每一次判断 当前循环节点 是否在 已遍历节点里,就要耗费很久的时间
让一个元素在一个列表中一路对比过去,何尝不是一种循环呢,前面也说过了,循环和递归都会导致时间复杂度增加
看样子我们暂时陷入了死局,算法路就要梦碎于此吗?

11.剪枝进阶——园林艺术
所以很明显,现在问题又变成了
如何用更少的条件判断节点是否已遍历?
要化繁为简,那注定是要用更加抽象的手段
我们可以从位置上动手,排列前给列表排个序,这样如果上一个位数字没有被节点选中,两个数字内容又一样的话,那我们就可以跳过了,直到两数字不一样,就会连续跳过一大段重复内容
这种方法的话只需要做一个 列表 位置被节点选中的状态 就行,比如三个位置没有被选中的话,就weizhi = [False,Flase,Flase],比起冗长的节点列表,这样会简洁非常多


记得一定要排序,这个例子也可以体现“连续跳过一大段重复内容”




解法和树树帮各位画出来了当然很好理解,但这种抽象的东西不看保姆教程就想不到怎么办呢?只能等死吗?

别急,文章结尾会和大家探讨学习的意义,我们先来看看代码上这种想法如何实现,从之前的代码开始分析
之前的代码是用数字表明 已被节点选中的位置 的,而不是布尔值,其实用数字判断在代码实现上简单一点,但不适合前面画PPT举例
我们先按照之前的方法,用 数字表示并判断 已被节点选中的位置
#以下为之前的代码
def permute2(list1):
out = [] #首先,要加个对列表进行排序
def dfs(list1, jiedian, weizhi):
if len(jiedian) == len(list1):
out.append(jiedian)
return
for i in range(len(list1)):
if i in weizhi: #这里原本判断的是节点位置i已被占用就跳过这个循环
continue #得再加一个判断,节点位置i-1没被占用,并且第i位数等于第i-1位时就跳过
dfs(list1, jiedian+[list1[i]], weizhi+[i])
dfs(list1, [], [])
return out
'''
排序用sort函数,在文章开头去重时用过的
加判断也是照着,节点位置i已被占用是 if i in weizhi,那节点位置i-1没被占用就是 if i-1 not in weizhi
第i位数等于第i-1位就很简单了,list1[i]==list1[i-1]
要注意i>0时这样取数才有意义,所以还要加个i>0的判断
'''
def permute2(list1):
out = []
list1.sort() #加个对列表进行排序
def dfs(list1, jiedian, weizhi):
if len(jiedian) == len(list1):
out.append(jiedian)
return
for i in range(len(list1)):
if i in weizhi:
continue
if i>0 and i-1 not in weizhi and list1[i]==list1[i-1]: #新加的判断,符合就剪枝
continue
dfs(list1, jiedian+[list1[i]], weizhi+[i])
dfs(list1, [], [])
return out拿去 LeetCode第47题:全排列 II跑一下试试



当然,你要用PPT里那种写法也可以,就是改动会大一点,而且更加抽象:
def permute2(list1):
out = []
list1.sort() #加个对列表进行排序
weizhi = [False] * len(list1) #建立一个用于判断选中状态的列表,默认全未选中
def dfs(list1, jiedian,weizhi):
if len(jiedian) == len(list1):
out.append(jiedian)
return
for i in range(len(list1)):
if weizhi[i] == True: #之前是用 i in weizhi 判断节点是否选中,因为被选中过的位置会加在列表weizhi里,而当前位置是i
continue #改了以后,i还是代表位置,不过取weizhi[i]看看状态就知道有没有选中了
if i>0 and weizhi[i-1]==False and list1[i]==list1[i-1]: #新加的判断,符合就剪枝
continue
weizhi[i] = True #开始递归,把i的位置改成被占用
dfs(list1, jiedian+[list1[i]],weizhi) #因为上一行代码改过占用位置了,这里直接把weizhi传过去就行
weizhi[i] = False #完成递归,把i的位置改回不被占用
dfs(list1,[],weizhi)
return out虽然快是很快了,但我们的问题还是一筹莫展,长度一长还是爆内存
令人高兴的是,我们已经学会了解决这个问题的必要基础,接下来就只是修修补补了
我们需要在任意长度的排列中避免[1,2]和[2,1] 或[1,2,3] 和 [3,2,1]这种实质上重复,以避免爆内存
12.回溯剪枝的灵活运用
12.1 不重复数组的去重
我们现在的问题变成了:
我们需要在任意长度的排列中排除[1,2]和[2,1] 或[1,2,3] 和 [3,2,1]这种实质上重复,以避免爆内存
我们再为之前 [1,2,3] 的回溯排列画一颗树,看看重复是如何产生的


很明显的发现,重复存在的原因是 添加了 比自己位置小 的 节点,如果不想重复应该这样:


那代码怎么写呢?我们之前是每次递归后 for循环所有数字 尝试添加节点,所以会有 位置 有没有被节点选中 的判断,现在这样不需要for循环所有数字了,直接往 自己后面的 位置 循环就行了,所以要改下for循环的起始点,并且删掉 位置 有没有被节点选中 的判断,剪枝同样也不需要了
同样从之前的代码开始
#以下为之前的代码
def permute2(list1):
out = []
list1.sort() #排序暂时没有必要,删掉
def dfs(list1, jiedian, weizhi):
if len(jiedian) == len(list1): #判断条件要改为小于等于,以记录所有节点
out.append(jiedian)
return #因为要记录所有节点,所以关掉返回,不然一开始递归就被结束了
for i in range(len(list1)):
if i in weizhi: #判断位置没有必要,删掉
continue
if i>0 and i-1 not in weizhi and list1[i]==list1[i-1]: #剪枝没有必要,删掉
continue
dfs(list1, jiedian+[list1[i]], weizhi+[i])
dfs(list1, [], [])
return out
'''
修改后
'''
def permute2(list1):
out = []
def dfs(list1, jiedian,start): #添加开始位置参数start
if len(jiedian) <= len(list1): #判断条件改为小于等于
out.append(jiedian) #写入节点
for i in range(start,len(list1)): #往后循环,所以开始位置要改成start
dfs(list1, jiedian+[list1[i]],i+1) #往后循环,所以传入的开始位置start要加1(i是节点位置)
dfs(list1, [],0) #有人会想问return和continue全删掉了,停止条件这一块谁给我补啊?
return out #循环到后面start会大于len(list1)的,这样就自然停止了(for循环中的递归语句不会被执行)LeetCode第78题:子集也是同样的问题,我们看看这种解法行不行


12.2 重复数组的去重
然而事情没有那么简单,在数组有重复的时候,这种办法并不能很好的去重
如经典的 [1,1,2] ,它的树是这样的
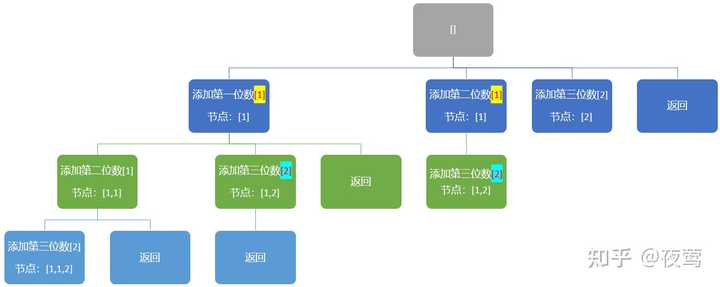

那就很简单了,经典去掉已经使用过的节点,这个在剪枝中说过,排序,判断list1[i]是否和list[i-1]相等即可
写入列表对比节点是否在列表里那种蠢办法千万不要再用了
def permute2(list1):
out = []
list1.sort() #排序对于剪枝的意义很重要,之前说过的
def dfs(list1, jiedian,start):
if len(jiedian) <= len(list1):
out.append(jiedian)
for i in range(start,len(list1)):
if i>start and list1[i] == list1[i-1]: #新加的剪枝条件,i>start这样取数才有意义,和之前i>0一样
continue
dfs(list1, jiedian+[list1[i]],i+1)
dfs(list1, [],0)
return outLeetCode第90题:子集 II 问的也是同样的问题,我们看看这种写法效果如何


然而这还是不足以解决我们的问题,长度一长还是“等通知”,因为它还是排列完再找符合条件的结果
我们需要一种方法,在排列的过程中不仅去掉实质的重复,也要去掉相加不可能为目标数的节点
现在开始往终极目标进发

13. 最终之战——组合总和
我们从 4.排列 开始,为了解决排列问题,我们递归、回溯、剪枝讲了好长一段,但最初的问题仍然没有进展:
在 [70,10,40,30,20] 中,任意长度排列组合,哪些数加起来会得到80和100?
为什么?因为我们一直在不爆内存和算的更快的问题上兜兜转转,在完成了所有的优化后,迎来了最后一个问题:
在排列的过程中去掉相加不可能为目标数的节点
我们在之前的回溯代码中,不断的尝试给节点添加数字,在经过排序后,给节点添加的数字那注定是越来越大的
这样的话,检测节点的相加值,一旦超过目标数,也给来个剪枝行不行呢?
我们接着之前子集Ⅱ的思路,为( [1,2,3,4] ,目标:3 )画一个树看看如何剪


再从之前的代码开始分析
#以下为之前子集Ⅱ的代码
def permute2(list1):
out = []
list1.sort() #排序对于剪枝的意义很重要,之前说过的
def dfs(list1, jiedian,start):
if len(jiedian) <= len(list1): #这里的写入条件要修改,加一个 相加等于目标值 才写入的判断
out.append(jiedian) #并且还要加一个剪枝,相加大于目标值就返回,当然,等于目标值也是要返回的
for i in range(start,len(list1)):
if i>start and list1[i] == list1[i-1]: #剪枝条件,避免实际意义的重复,i>start这样取数才有意义,和之前i>0一样
continue
dfs(list1, jiedian+[list1[i]],i+1)
dfs(list1, [],0)
return out
'''
开始修改
'''
def permute2(list1,target):
out = []
list1.sort() #排序对于剪枝的意义很重要,之前说过的
def dfs(list1, jiedian,start):
if sum(jiedian) > target: #新加的剪枝,相加大于目标值就剪枝返回
return
if len(jiedian) <= len(list1) and sum(jiedian) == target: #新加了相加等于目标值才能写入的判断
out.append(jiedian)
return #别忘了,相加等于目标值后也可以剪枝了,所以加return
for i in range(start,len(list1)):
if i>start and list1[i] == list1[i-1]: #之前的剪枝条件
continue
dfs(list1, jiedian+[list1[i]],i+1)
dfs(list1, [],0)
return outLeetCode第40题:组合总和 II 问的也是同样的问题,我们看看这样写的效果


顺利了完成了176个长度1~100的测试案例,答案正确,并且在较高长度下没有爆内存!
这足以应对我们对结转凭证对方科目的查找,至此,我们的问题就解决了,当然这种写法和标准答案就一点差距,不过都看到这里了,怎么优化对于读者来说也不是难事了


14. 后记——学习的意义
文中一些案例我都用了LeetCode上的经典例题,包括最后的解决方案也是
那有人就会想,遇到这种问题直接去抄别人的答案不就行了,自己学一遍好麻烦
那问题又来了,如果没学过算法并且我不说的话,在遇到这些问题时能知道这是LeetCode的第40题吗?
只有学过以后,面对难以解决的问题才会知道去哪找到答案,以及别人答案和自己的问题有什么区别,知道区别和用法才能改过来实现自己的目的,用通俗的话来说——抄,也得知道从哪抄,怎么抄
如果什么都不知道就想抄的话,那注定会被自己看不懂的地方困住

就与数据相关的算法而言,算法是一套包含参数的固定流程,主要有两个作用,一个是记忆数据中的固有规律,以期待预测与之分布相似的其他数据的结果。二是通过某种流程计算不同数据间的相似性和差异性,以便对数据进行分类和泛化。

没意义,别学了,能问出这种问题你学也没用哈哈哈

从一个需求谈起
在我之前的项目中,曾经遇到过这样一个需求,编写一个级联选择器,大概是这样:

图中的示例使用的是Ant-Design的Cascader组件。
要实现这一功能,我需要类似这样的数据结构:
var data = [{
"value": "浙江",
"children": [{
"value": "杭州",
"children": [{
"value": "西湖"
}]
}]
}, {
"value": "四川",
"children": [{
"value": "成都",
"children": [{
"value": "锦里"
}, {
"value": "方所"
}]
}, {
"value": "阿坝",
"children": [{
"value": "九寨沟"
}]
}]
}]一个具有层级结构的数据,实现这个功能非常容易,因为这个结构和组件的结构是一致的,递归遍历就可以了。
但是,由于后端通常采用的是关系型数据库,所以返回的数据通常会是这个样子:
var data = [{
"province": "浙江",
"city": "杭州",
"name": "西湖"
}, {
"province": "四川",
"city": "成都",
"name": "锦里"
}, {
"province": "四川",
"city": "成都",
"name": "方所"
}, {
"province": "四川",
"city": "阿坝",
"name": "九寨沟"
}]前端这边想要将数据转换一下其实也不难,因为要合并重复项,可以参考数据去重的方法来做,于是我写了这样一个版本。
'use strict'
/**
* 将一个没有层级的扁平对象,转换为树形结构({value, children})结构的对象
* @param {array} tableData - 一个由对象构成的数组,里面的对象都是扁平的
* @param {array} route - 一个由字符串构成的数组,字符串为前一数组中对象的key,最终
* 输出的对象层级顺序为keys中字符串key的顺序
* @return {array} 保存具有树形结构的对象
*/
var transObject = function(tableData, keys) {
let hashTable = {}, res = []
for( let i = 0; i < tableData.length; i++ ) {
if(!hashTable[tableData[i][keys[0]]]) {
let len = res.push({
value: tableData[i][keys[0]],
children: []
})
// 在这里要保存key对应的数组序号,不然还要涉及到查找
hashTable[tableData[i][keys[0]]] = { $$pos: len - 1 }
}
if(!hashTable[tableData[i][keys[0]]][tableData[i][keys[1]]]) {
let len = res[hashTable[tableData[i][keys[0]]].$$pos].children.push({
value: tableData[i][keys[1]],
children: []
})
hashTable[tableData[i][keys[0]]][tableData[i][keys[1]]] = { $$pos: len - 1 }
}
res[hashTable[tableData[i][keys[0]]].$$pos].children[hashTable[tableData[i][keys[0]]][tableData[i][keys[1]]].$$pos].children.push({
value: tableData[i][keys[2]]
})
}
return res
}
var data = [{
"province": "浙江",
"city": "杭州",
"name": "西湖"
}, {
"province": "四川",
"city": "成都",
"name": "锦里"
}, {
"province": "四川",
"city": "成都",
"name": "方所"
}, {
"province": "四川",
"city": "阿坝",
"name": "九寨沟"
}]
var keys = ['province', 'city', 'name']
console.log(transObject(data, keys))还好keys的长度只有3,这种东西长了根本没办法写,很明显可以看出来这里面有重复的部分,可以通过循环搞定,但是想了很久都没有思路,就搁置了。
后来,有一天晚饭后不是很忙,就跟旁边做数据的同事聊了一下这个需求,请教一下该怎么用循环来处理。他看了一下,就问我:“你知道trie树吗?”。我头一次听到这个概念,他简单的给我讲了一下,然后说感觉处理的问题有些类似,让我可以研究一下trie树的原理并试着优化一下。
讲道理,trie树这个数据结构网上确实有很多资料,但很少有使用JavaScript实现的,不过原理倒是不难。尝试之后,我就将transObject的代码优化成了这样。(关于trie树,还请读者自己阅读相关材料)
var transObject = function(tableData, keys) {
let hashTable = {}, res = []
for (let i = 0; i < tableData.length; i++) {
let arr = res, cur = hashTable
for (let j = 0; j < keys.length; j++) {
let key = keys[j], filed = tableData[i][key]
if (!cur[filed]) {
let pusher = {
value: filed
}, tmp
if (j !== (keys.length - 1)) {
tmp = []
pusher.children = tmp
}
cur[filed] = { $$pos: arr.push(pusher) - 1 }
cur = cur[filed]
arr = tmp
} else {
cur = cur[filed]
arr = arr[cur.$$pos].children
}
}
}
return res
}这样,解决方案就和keys的长短无关了。
原地址: https://github.com/LeuisKen/leuisken.github.io/issues/2
关注公众号 五分钟学算法 获取更多通过动画的形式了解数据结构与算法的文章
回复 1024 获取算法从入门到进阶的 1G 电子书。

学过算法呢
第一 会选用库
第二 潜移默化影响你的判断 决策等能力
第三 偶尔遇到需要算法的逻辑 可以用
就像学游泳 学会了仰泳这个姿势不你锻炼了呼吸 你也锻炼了肌肉
学他对做高级程序影响不大 但一旦影响 就是救命稻草
比如曾经一个需求是等待一个订单的其他单据收集齐 最后在一个字段上用加法表示了出来 不需要查数据库 并且避免并发问题
有些算法是库没提供的 业务需要的 没觉得需要是因为量小 而且你不知道有个算法可以用

我不知道提问者所指的意义是针对前端开发者还是后端开发者或是其他XX领域开发者...
下面这篇文章阐述了前端开发者学习算法的重要性
为什么我认为数据结构与算法对前端开发很重要?
目前为止我参加过几次前端开发方面的面试,确实有不少面试官会问道一些算法。通常会涉及的,是链表、树、字符串、数组相关的知识。前端面试对算法要求不高,似乎已经是业内的一种共识了。虽说算法好的前端面试肯定会加分,但是仅凭常见的面试题,而不去联系需求,很难让人觉得,算法对于前端真的很重要。

进大厂

计算机科学的本质是当面对一个问题的时候,能够理解并抽象出解决这个问题的方法,并且用适当的工具来解决这个问题。算法就像是你用大白话解释下怎么解决这个问题,而编程语言所对应的只是解决这个问题的工具。
就像你是木匠,要做一张桌子,你要明白怎么做桌子这个过程,按部就班的来执行做桌子。一开始你可能需要学习,试做几次。 你选锤子,刀子,剪子还是锯子,要看你熟练不熟练,能不能满足做桌子这个任务。

想想学英语的时候为什么学习语法,想想学习数学物理的时候为什么学习定理公式,想想学习篮球游泳的时候为什么学习那些姿势


算法是计算机的基石。
研究生有大把的时间,可以静心来研究计算机的基础东西,不要过于功利。
并且,校招的笔试题大部分是算法编程题,算法工程师的工资在 IT 算最前列的,你还不满意。
没有发明计算机的话光研究算法没有什么用,而没有算法,计算机的一些底层也无法实现或者实现的效率很低。所以计算机有什么用,算法就有什么用。
应用层次上自然科学可以利用算法模拟实验,数学可以利用计算机配合算法证明定理,语言学可以用算法研究研究NLP,例子太多了。

谢谢邀请,简单的发表一下我的看法吧。
个人觉得,目前大家对算法的理解可能主要有两类,一类是传统的数据结构与算法,另一类是现在很热门的机器学习算法,我就这两种发表一下我个人的感觉。
对于数据结构和算法,套用计算机里面一句说烂了的话:程序=数据结构+算法。数据结构是数据组织的一种方式,算法的话可以举个很简单的例子:计算1到100之间所有数的和,传统的最笨的方法就是逐个累加,即1+2=3,3+3=6,6+4=10,……,算到100就需要计算99次;但后来有人发现了规律:1+100=2+99=3+98=……=50+51,那不就是100/2=50个101相加嘛,所以直接等于(1+100)*100/2,即首末相加除以2就可以,是不是省了很多计算量,这在数量量更大时优势就更明显了,后面这种处理方式就是采用了某种算法。怎么样,发现算法的好处了吧?
还有一个例子,好像是以前网上看到有人说的:写程序就像开一辆车,当你不懂太多数据结构跟算法的时候,凭借丰富的实践经验你也可以将这辆车开好;但是,当有一天这辆车出问题跑不起来的时候呢?你不懂它内部的运行机制,你要怎么排除和解决问题?
对于机器学习算法,准确的说是应该称作模型而不能直接称为算法的。机器学习的作用相信很多人都有了解一些,比如你经常用的淘宝购物猜你喜欢,网易云音乐推荐你感兴趣的歌曲,今日头条推送你感兴趣的新闻,人脸识别,语音识别,阿尔法狗与人下棋等等。其实这些各种各样强大的模型背后基本都有一个共同点,那就是优化算法;说白了,机器学习模型大部分时候就是定义一个损失函数,将其转化为求解损失函数极小值的问题,你采用梯度下降法,牛顿法等各种优化方法,会直接决定模型的优化求解速度和准确度。
【大概就说这么多吧,总之就是一句废话总结:算法真的很神奇,也很有用的,千万不要排斥它!】

很神秘要回答这问题……
要是抖包袱说:
算法工程师的收入普遍高于其他人员的话,你会不会觉得有意义?
高中数学新课标都在教算法,你说算法有什么用

首先泻药。其次算法是什么?(黑人问号脸)我完全不懂啊,为什么邀请我呢?难道因为我被暗恋了?!(๑˙ー˙๑)

算法就像(也可以说是)数学。
数学有什么用?大概只有用到的那一天才知道有什么用。
当然不排除因为需要用而发展新的数学。