一种基于课程学习的强化学习知识图谱推理方法
本发明属于自然语言处理领域。
背景技术:
知识图谱推理算法的主流方法是从构造的知识图中推断出新的事实,基于强化学习的知识图谱推理已经成为图谱推理算法的重要研究方向之一,在emnlp2017中发布的deeppath首次在知识图谱推理中引入强化学习方法,其主要任务是从给定的实体对(head,tail)推理从head到tail的路径,其子任务包括关系预测和事实预测,具体地它对知识图谱进行简单采样以训练策略网络并通过手动设计的奖励函数对策略网络再次进行训练(如此设计的策略可能不是最优的且针对不同数据集可能需要不同设置)。在iclr2018中发布的minerva的任务定义与deeppath略有不同,该模型的输入是给定的查询(head,relation)(即实体关系对,包括头实体与关系)并且其子任务只包括事实预测。这种方法无需预训练以及精妙的人工奖励函数设置,但存在虚假路径问题,即没有切实的有依据的高质量路径用于训练,模型可能被虚假路径误导。multihop-kg提出动作丢弃方法通过在采用动作集合时掩盖掉一部分出边,避免智能体被最初找到的路径误导,强制智能体充分探索所有可能路径。
本专利提出的基于课程学习的强化学习知识图谱推理方法,在使用强化学习建模知识图谱查询问答的基础上融合课程学习方法:由于简单样本中虚假路径比例更低,本方法假定虚假路径比例更低的样本为高质量的,逐步深入到复杂样本时这些信息能帮助智能体决策,本方法提高模型准确率且额外时间开销和参数量可忽略不计。
技术实现要素:
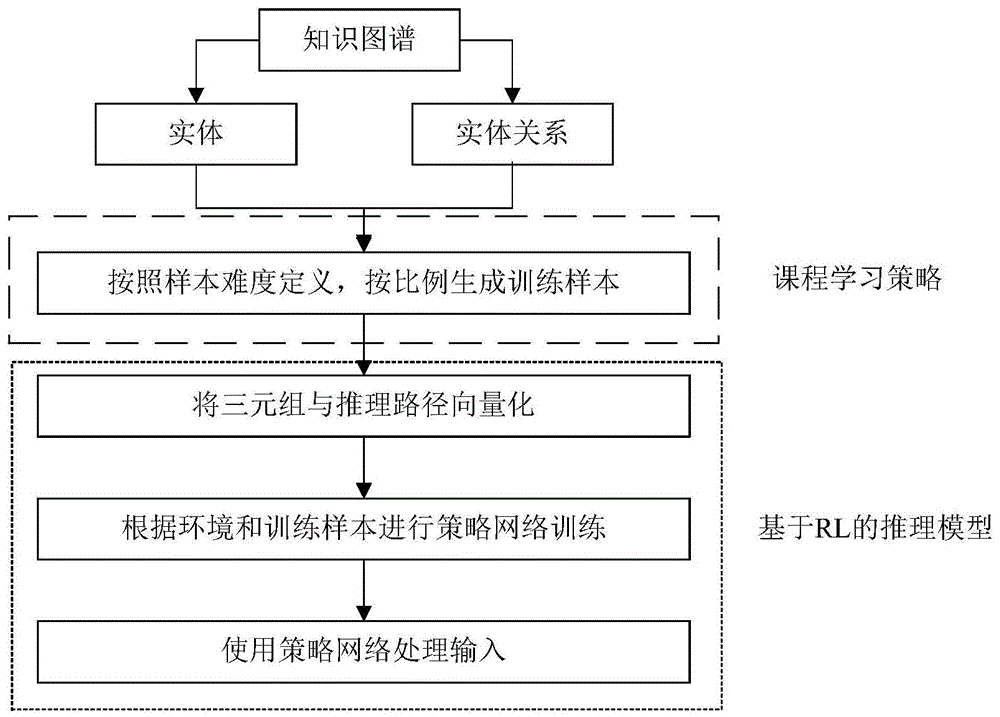
本发明提出一种基于rlkgr-cl的知识图谱推理算法。该算法步骤如下:
(1)步骤一:首先将用于训练的知识图谱中实体集和关系集取出并按照定义好的样本难度计算方式对训练集进行排序,将每个关系对应的排序在前(难度小)的事实定义为简单样本,排序在后(难度大)的事实定义为复杂样本。
(2)步骤二:再根据训练阶段按比例生成训练样本。
(3)步骤三:将事实三元组与推理路径向量化,在rl学习定义下根据环境和训练样本对策略网络进行训练迭代。
(4)步骤4使用训练好的策略网络得出输入查询对应的正确实体集
改进模型的指标hit@1,hit@10,mrr在数据集wn18rr上分别增长了1.7%,1.5%,1.3%,在数据集nell-995上分别增长了1.9%,4.8%,3.7%。
附图说明
附图1:本发明的算法整体框图。
附图2:rlkgr-cl算法的改进思路。
附图3:actiondropout策略示例。
附图4:改进前后模型及对比模型的收敛速度。
附图5:课程学习stages数量以及对应简单困难样本比。
附图6:minerva(rlkgr-cl)模型超参数。
附图7:multihopkg(complex-rlkgr-cl)和multihopkg(conve-rlkgr-cl)模型超参数。
附图8:minerva和multihopkg模型改进前后的查询问答结果。
附图9:本发明的模型改进前后每轮迭代时间。
具体实施方式
步骤一:课程学习训练样本生成。对不同难度的样本赋予不同的权重,即改变训练样本的分布。训练前期简单样本的权重最高,这意味着它们具有较高的概率被采样;随着训练轮次增大,较难的训练样本权重也增大;最后统一样本权重即直接在目标训练集上进行训练。
对训练集进行预处理,以三元组中头实体的度数来拟合问题的复杂程度并定义样本的难度。具体地对于关系r,训练样本中总共有n个事实,按照头实体的度对所有事实进行排序,具有较高度数n/2个事实被归入困难集合,具有较低度数n/2个事实被归入简单集合。最终训练集中来自简单集合的比例为α,来自困难集合的比例为β,且α+β=1。
步骤二:事实三元组与推理路径向量化。使用知识图谱embedding模型complex、conve来估计对目标实体的软奖励。评分函数定义为
智能体将es即查询中的头结点作为出发点,依次选择标记为rl的出边,沿出边到达并遍历新实体,直到智能体跳转多次即步长增至t时停止搜索。如果智能体已设法到达查询中的目标实体,那么它可以更早地获得正确答案并且使用名为“no_op”的特殊操作在剩余的几个步骤中停留在当前节点。决策过程的各部分分别如下:
1.状态查询由q=(eh,rq)∈q表示,其中eh和rq分别是头实体和查询中的关系。状态空间g是由所有合法且有效的组合构成的,具体为s=e×q×e。每一种状态可以表示为sc=(ec,q,et)=(ec,(eh,rq),et)∈s,其中et是目标答案,ec是智能体在第c步所处实体即当前位置。
2.动作第c步的动作空间ac包括智能体所处于实体(当前节点)的所有出边,即ac=(r′,e′)|(ec,r′,e′)∈g。为智能体提供继续留在当前节点的操作选项,添加一种特殊动作即“no_op”。
3.转移查询q=(eh,rq)和目标答案et在每一步中都保持不变。转移函数为δ:s×a→s,正式地定义为δ(sc,ac)=δ(ec,(eh,rq),ac)。
4.奖励在默认情况下,智能体只会在最终到达正确节点时获得值为+1的奖励,其他时候都不会获得任何奖励,奖励得分如公式(1)。
rb(st)=1(ehead,r,etail)∈g(1)
在使用基于知识的奖励塑造模型的情况下,通过已存在的为知识图谱补全设计的基于嵌入(翻译)的模型将图谱映射到密集向量空间,再使用实体和关系嵌入作为参数组成的打分函数f(eh,r,et)来估计每个三元组l=(eh,r,et)∈g的可能性。打分函数f以最大化g中所有三元组的可能性为目标进行训练。使用基于知识的奖励塑造模型的情况下的奖励得分公式如式(2)。
r(st)=rb(st)+(1-rb(st))f(eh,r,et)(2)
如果智能体最终到达实体et是最终答案,则智能体将获得奖励,其值为+1。否则,智能体将收到由预训练模型(基于知识的奖励塑造模型)估计出的分数。
步骤三:策略网络构建和训练。查询中二元的关系和实体分别被映射到密集嵌入向量e∈rd和r∈rd。策略网络决定从当前节点的所有出边ast中选择一个动作at,即at∈ast且at=[e;r]表示关系嵌入和尾节点嵌入的连接。
历史搜索序列ht=(eh,r1,e1,...,rc,ec)由智能体决定步骤c所执行的观察和动作组成。使用带有三个门限模块的lstm神经网络对历史搜索序列ht进行编码如式(3)、(4)所示。
h0=lstm(0,[r0;es])(3)
hc=lstm(hc-1,ac-1),t>0(4)
其中r0是特殊的起始关系,被引入与es组成起始动作。
动作空间是通过将所有可用动作的嵌入向量空间at:|ast|×2d堆叠来进行编码的。策略网络π定义为式(5)。
πθ(at|st)=σ(at×w2relu(w1[et;ht;rq]))(5)
其中σ是softmax运算符。
优化目标是找到参数θ,以最大程度地提高g中所有查询的预期奖励,如式(6)所示。
用reinforce算法解决此优化问题。该算法迭代g中的所有事实,并使用式(7)随机梯度更新θ。
动作丢弃策略在reinforce的采样步骤中随机丢弃智能体当前所在节点的一些出边,智能体根据调整后的动作分布执行采样如式(8)、(9)所示。
mi~bernouli(1-α),i=1,...,|at|(9)
其中
过程如附图3所示,在第一轮次中智能体从头结点head出发,经过路径上的实体{e1,e2}到达目标实体tail;但到第二轮次时,在reinforce采样步骤里fromheadtoe1这条出边被随机掩盖掉,由此得到动作集合{fromheadtoe3,fromheadtoe4}。在第二轮次中智能体无法偏向第一轮次中找到的路径fromheadtoe1,智能体只能在masking调整后的动作集合中选择出边,由此保证智能体探索图谱中路径的多样性。
使用三个公开标准数据集,具体为wn18rr、fb15k-237、nell-995,使用知识图谱表示学习研究常用的指标mrr、hits@1和hits@10来分析实验结果。mrr和hits@n等指标均为值越高表示预测效果越好。其中mrr表示对一系列查询q,正确实体得分排名取倒数的平均值,如式(10)所示。
hits@n表示测试集中正确实体在得分排名前n实体中所占的比率如式(11)所示。指标hits@1中统计得分排名第一,指标hits@10中统计得分排名前十。
需要确定的超参数主要包括阶段数量stages和每个阶段简单样本与困难样本的比例{stage1,stage2,…,stagen}且stagei∈(0,1)。设置参数stages的选取范围为{2,3,4,5},参数stagei的选取范围为{0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9}。
对于minerva(rlkgr-cl)来说,每一轮训练中简单样本集中样本数量与困难样本集中样本数量比在各个数据集上最佳参数如附图5所示,它们的阶段数量均为4,每个阶段按照轮次数来划分,四个阶段对应的epoch数范围分别为[1,4/m],(m/4,m/2],(m/2,3m/4],(3m/4,m]。
1.奖励在默认形式中,奖励函数设置较为简单,如果智能体到达的最后节点是正确答案,则智能体的最终奖励为+1,否则为0。
2.超参数lstm神经网络的层数为3。β表示熵正则化常数,值在0-0.1之间。在其他参数上,rlkgr-cl模型与基准模型的最佳参数保持一致如附图6所示,其中batch_size为每轮样本训练数量,hidden_size为lstm网络的隐藏大小,embedding_size为实体和关系的嵌入大小,learning_rate为学习率,total_iterations为迭代次数,max_num_actions为智能体每次跳转采样得到的动作集的最大动作数量,path_length为路径长度即最大步数t。
对于multihopkg(complex-rlkgr-cl)和multihopkg(conve-rlkgr-cl)模型,阶段数量为4,其他参数为stage1=0.8,stage2=0.7,stage3=0.5,stage4=0.5。
1.波束搜索解码从头实体开始的多条路径的端点可能是同一实体。最后一步中列出所有已到达的唯一实体集,将每个唯一实体的得分设置为端点所有路径中的最高得分,然后输出排名最高的唯一实体。
2.奖励在使用基于知识的奖励塑造模型的情况下,通过已存在的为知识图谱补全设计的基于嵌入(翻译)的模型将图谱映射到密集向量空间,再使用实体和关系嵌入作为参数组成的打分函数f(eh,r,et)来估计每个三元组l=(eh,r,et)∈g的可能性。如果智能体最终到达实体et是最终答案,则智能体将获得奖励其值为+1。否则智能体将收到由预训练模型(基于知识的奖励塑造模型)估计出的分数。
3.超参数模型使用的3层lstm神经网络的隐藏大小为200,同样使用adam优化器。在其他参数上,rlkgr-cl模型与基准模型的最佳参数保持一致如附图7所示,其中hidden_action_dropout_rate为动作丢弃策略调整时被掩盖动作百分比,beam_size为波束搜索解码时的分组大小。
步骤四:结果分析。运行算法并完成基准模型和改进后的rlkgr-cl模型的训练和测试,得到的查询问答结果如附图8所示。与最先进的基于嵌入的模型和基于逻辑规则的kg推理模型进行比较:该表的上半部分是基于嵌入的推理模型complex、conve和distmult的结果,下半部分是基于路径的模型neurallp、minerva、minerva(rlkgr-cl)。
指标hit@1,hit@10,mrr在wn18rr上分别增长了1.7%,1.5%,1.3%,在nell-995上分别增长了1.9%,4.8%,3.7%。multi-kg在fb15k-237和nell-995上均具有最佳评估指标,改进后的方法multihopkg(complex-rlkgr-cl)和multihopkg(conve-rlkgr-cl)在数据集nell-995上的hit@1指标分别增加了0.4%和0.2%。将complex作为预训练模型的方法multihopkg(conve-rlkgr-cl)在数据集fb15k-237和nell-995上的性能有了稍微的提高。
分别选取基于表示学习的模型complex、conve、distmult和基于强化学习的模型minerva、multihopkg作为对比模型。其中multihopkg对基于知识的奖励塑造模型(即基于表示学习的模型)进行预训练,后续训练迭代次数在20-40轮之间,与其余模型的迭代次数范围差距大,故将其收敛速度相关实验数据即放在附图4中第一列进行可视化。
附图4绘制了三种表示学习模型conve、dismult和complex,第一列绘制了三种表示学习模型conve、dismult和complex,基于强化学习的minerva模型和改进后的minerva(rlkgr-cl)模型在验证集上相对于训练时期数的mrr得分。可见在wn18rr和nell-995数据集上,基于强化学习的minerva模型和改进后的minerva(rlkgr-cl)模型最终收敛至的分数均高于表示学习模型,而在fb15k-237数据集上改进后的minerva(rlkgr-cl)模型最终收敛分数最小,minerva模型与表示学习模型dismult、complex的最终收敛分数接近,conve模型最终收敛分数较高。
观察附图4中第二列,使用表示学习模型作为知识的奖励塑造模型的multihopkg系列模型在数据集wn18rr的最终收敛分数与表示学习模型、minerva等相差不大;multihopkg系列模型在fb15k-237数据集上的最终收敛分数明显高于改进前的minerva模型、改进后的minerva(rlkgr-cl)模型、dismult和complex模型,但低于conve模型;在nell-995数据集上,multihopkg系列模型最终收敛分数均优于改进前后的minerva模型和三种表示学习模型。
在收敛速度方面,基于表示学习的模型的收敛速度均快于基于强化学习的模型。对于改进后的minerva(rlkgr-cl)模型:在nell-995上,使用早期停止策略,因为在该数据集上模型收敛速度更快,并且在迭代次数为2500-3000轮次之间时模型将过拟合数据集;模型在fb15k-237数据集上的收敛速度略有提高。
对比改进前和改进后的multihopkg模型:在选取的三个数据集上,模型收敛速度均无明显变化;在wn18rr数据集上改进后模型的最终分数均降低,而在fb15k-237和nell-995上,改进前和改进后模型收敛到的最终分数几乎无差距。
将训练集分为简单集和困难集在wn18rr、fb15k-237和nell-995数据集上预处理所花时间分别为0.317,1.258,0.270秒。在minerva模型中,样本生成本身就是随机的,原本的rl算法中生成一组长度为n的随机数,将这个步骤分为两步:生成长度为α*n的简单样本对应的一组随机数,再生成长度为(1-α)*n的困难样本对应的一组随机数,根据两组随机数分别取出对应样本进行训练,训练时间基本保持不变。
在multihopkg模型中,预训练嵌入模型的步骤保持不变。rl训练过程中样本生成本身是固定的,按照顺序依次循环读取样本进行训练。将这个过程改为随机生成,有以下两步:生成长度为α*n的简单样本对应的一组随机数,再生成长度为(1-α)*n的困难样本对应的一组随机数,根据两组随机数分别取出对应样本进行训练,训练时间略微增加,但rl训练过程不同于预训练过程,迭代次数少,范围在10-40次迭代,训练时间基本不变。
对每轮迭代开始时记录一次时间戳,结束时记录一次时间戳,取得每轮迭代时间平均值如附图9所示,前三行分别为三种表示学习模型在各个数据集上的每轮迭代时间,后面依次为改进前的minerva模型、改进后的minerva(rlkgr-cl)模型、改进前的multihopkg(complex)、改进后的multihopkg(complex-rlkgr-cl)模型、改进前的multihopkg(conve)模型和改进后的multihopkg(conve-rlkgr-cl)模型。其中,额外时间的行表示改进后模型的每轮迭代时间减去改进前模型的每轮迭代时间,该值为正数则表示改进后每轮迭代时间增加,反之改进后每轮迭代时间减少。
对于改进后的模型minerva(rlkgr-cl)、multihopkg(complex-rlkgr-cl)和multihopkg(conve-rlkgr-cl),它们基本上都在wn18rr和nell-995数据集上迭代时间略微减少,而在fb15k-237数据集上迭代时间增加。其中multihopkg(complex-rlkgr-cl)和multihopkg(conve-rlkgr-cl)在数据集fb15k-237上每轮迭代时间增加较多,分别为67.1135s和15.957s。而multihopkg(conve-rlkgr-cl)模型在数据集wn18rr上减少的每轮迭代时间较多,为11.880s。
总的来说,minerva的改进模型的指标hit@1,hit@10,mrr在数据集wn18rr上分别增长了1.7%,1.5%,1.3%,在数据集nell-995上分别增长了1.9%,4.8%,3.7%,且训练时间有所下降。
- 基于自动化补全知识图谱的水利...
- 基于RankNet-tran...
- 一种基于知识图谱的标注训练模...
- 一种基于文档数据分析的在线文...
- 一种裁判文书精准化数据归类分...
- 数据标注方法、装置、电子设备...
- 文本分类方法及装置、电子设备...
- 一种基于知识图谱的筛选方法及...
- 数据处理方法、装置、服务器及...
- 一种基于知识图谱的科技文献分...
- 还没有人留言评论。精彩留言会获得点赞!