一种基于关键词的文本信息精准匹配方法、系统、存储介质、终端与流程
本发明涉及信息处理的技术领域,特别是涉及一种基于关键词的文本信息精准匹配方法、系统、存储介质、终端。
背景技术:
现有技术中,在进行文本信息检索时,通常采用以下几种方案:
(1)采用纯文字匹配的方式,但该方式会导致检索到很多无关的文本内容,给用户带来很多困扰。例如,文本内容出现有用户指定的关键词,但该关键词并非文本的重点讲述内容。再例如,文本内容中出现有该关键词,但该关键词并不形成一个构词,导致语义不相关的文本内容被命中,如关键词是“和服”,命中的文本内容为“产品和服务”。
(2)采用文本关键词抽取的方式对用户设置的关键词进行赋分和排序,但计算得到的结果会因为文本长度不同、关键词设置数量不同等原因很难进行分值比较,同时很多完全命中且关键词分值高的文本信息并非用户所需。
(3)采用文本分类的方式,但该方式仅在海量数据的情况下能够自动捕捉文本特征,难以融合用户设置的关键词信息进行判断。特别地,对于用户反馈数据数量有限的应用场景,无法满足应用需求。
(4)采用基于文本的推荐系统,推荐用户在当前最感兴趣或者与最相似的内容,即收集用户收藏或点击的匹配内容,用文本相似的方法查找匹配文本信息。但该方式需要积累一定程度的用户反馈信息。
(5)采用融合关键词特征的协同过滤推荐。典型的推荐系统中,将点击率、阅读时间等可以量化的目标作为目标函数,采用用户历史行为、协同特征、环境特征等进行建模,但也需要积累一定量的用户反馈数据。
技术实现要素:
鉴于以上所述现有技术的缺点,本发明的目的在于提供一种基于关键词的文本信息精准匹配方法、系统、存储介质、终端,将关键词作为文本特征,结合有监督的文本分类,大大提升了文本信息匹配的可解释性和精确程度。
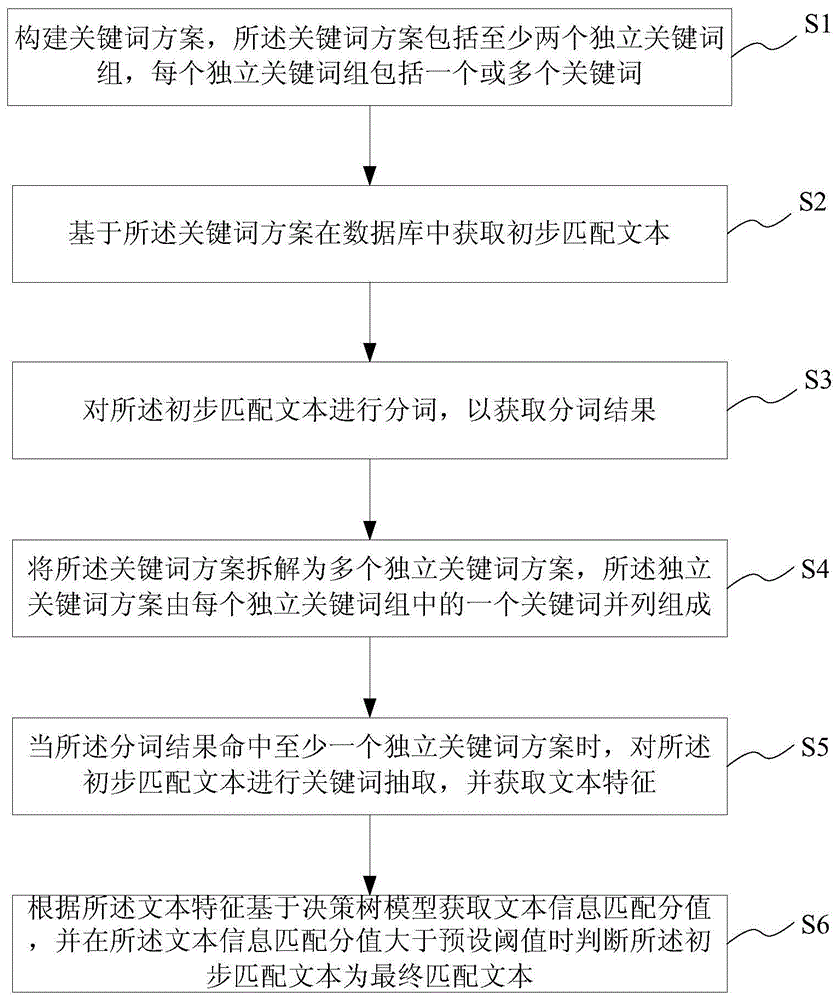
为实现上述目的及其他相关目的,本发明提供一种基于关键词的文本信息精准匹配方法,包括以下步骤:构建关键词方案,所述关键词方案包括至少两个独立关键词组,每个独立关键词组包括一个或多个关键词;基于所述关键词方案在数据库中获取初步匹配文本;对所述初步匹配文本进行分词,以获取分词结果;将所述关键词方案拆解为多个独立关键词方案,所述独立关键词方案由每个独立关键词组中的一个关键词并列组成;当所述分词结果命中至少一个独立关键词方案时,对所述初步匹配文本进行关键词抽取,并获取文本特征;根据所述文本特征基于决策树模型获取文本信息匹配分值,并在所述文本信息匹配分值大于预设阈值时判断所述初步匹配文本为最终匹配文本。
于本发明一实施例中,基于textrank算法对所述初步匹配文本进行关键词抽取。
于本发明一实施例中,所述文本特征包括文本排序特征、文本分数特征、文本排序分数融合特征、文本关键词匹配特征、文本方案特征、文本方案深度特征、标题排序特征、标题分数特征、标题排序分数融合特征、标题关键词匹配特征、标题方案特征和标题方案深度特征。
于本发明一实施例中,所述决策树模型基于带标注的数据进行有监督建模生成。
对应地,本发明提供一种基于关键词的文本信息精准匹配系统,包括构建模块、获取模块、分词模块、拆解模块、抽取模块和匹配模块;
所述构建模块用于构建关键词方案,所述关键词方案包括至少两个独立关键词组,每个独立关键词组包括一个或多个关键词;
所述获取模块用于基于所述关键词方案在数据库中获取初步匹配文本;
所述分词模块用于对所述初步匹配文本进行分词,以获取分词结果;
所述拆解模块用于将所述关键词方案拆解为多个独立关键词方案,所述独立关键词方案由每个独立关键词组中的一个关键词并列组成;
所述抽取模块用于当所述分词结果命中至少一个独立关键词方案时,对所述初步匹配文本进行关键词抽取,并获取文本特征;
所述匹配模块用于根据所述文本特征基于决策树模型获取文本信息匹配分值,并在所述文本信息匹配分值大于预设阈值时判断所述初步匹配文本为最终匹配文本。
于本发明一实施例中,所述抽取模块基于textrank算法对所述初步匹配文本进行关键词抽取。
于本发明一实施例中,所述文本特征包括文本排序特征、文本分数特征、文本排序分数融合特征、文本关键词匹配特征、文本方案特征、文本方案深度特征、标题排序特征、标题分数特征、标题排序分数融合特征、标题关键词匹配特征、标题方案特征和标题方案深度特征。
于本发明一实施例中,所述决策树模型基于带标注的数据进行有监督建模生成。
本发明提供一种存储介质,其上存储有计算机程序,该程序被处理器执行时实现上述的基于关键词的文本信息精准匹配方法。
最后,本发明提供一种终端,包括:处理器及存储器;
所述存储器用于存储计算机程序;
所述处理器用于执行所述存储器存储的计算机程序,以使所述终端执行上述的基于关键词的文本信息精准匹配方法。
如上所述,本发明的基于关键词的文本信息精准匹配方法、系统、存储介质、终端,具有以下有益效果:
(1)结合关键词和文本分类,融入了强业务解释性的特征,大大提升了文本信息匹配的精确程度;
(2)无需极大量数据,即可实现文本信息匹配;
(3)文本信息匹配所采用的特征融合了文本特征和业务特征,极具创新性;
(4)在实际应用场景中可行有效,实用性强。
附图说明
图1显示为本发明的基于关键词的文本信息精准匹配方法于一实施例中的流程图;
图2显示为本发明的基于关键词的文本信息精准匹配系统于一实施例中的结构示意图;
图3显示为本发明的终端于一实施例中的结构示意图。
元件标号说明
21构建模块
22获取模块
23分词模块
24拆解模块
25抽取模块
26匹配模块
31处理器
32存储器
具体实施方式
以下通过特定的具体实例说明本发明的实施方式,本领域技术人员可由本说明书所揭露的内容轻易地了解本发明的其他优点与功效。本发明还可以通过另外不同的具体实施方式加以实施或应用,本说明书中的各项细节也可以基于不同观点与应用,在没有背离本发明的精神下进行各种修饰或改变。
需要说明的是,本实施例中所提供的图示仅以示意方式说明本发明的基本构想,遂图式中仅显示与本发明中有关的组件而非按照实际实施时的组件数目、形状及尺寸绘制,其实际实施时各组件的型态、数量及比例可为一种随意的改变,且其组件布局型态也可能更为复杂。
本发明的基于关键词的文本信息精准匹配方法、系统、存储介质、终端将关键词作为文本特征,结合有监督的文本分类,无需极大量数据即可实现文本信息匹配,且文本信息匹配精确程度,实用性强。
如图1所示,于一实施例中,本发明的基于关键词的文本信息精准匹配方法包括以下步骤:
步骤s1、构建关键词方案,所述关键词方案包括至少两个独立关键词组,每个独立关键词组包括一个或多个关键词。
具体地,所述关键词方案由多个并列的独立关键词组组成。每个独立关键词组包括一个或多个关键词,且所述多个关键词为“或”的关系。例如,关键词方案为:(荆州)+(身边事|突发|出事|出大事|事故)+(车祸|起火|火灾|冲突),意为希望得到的预警事件是荆州发生的突发事件,包括火灾、车祸等重大事件。其中每个()代表一个独立关键词组,()内的各个关键词为可选的。也就是说,对于具体的关键词方案,可以是荆州、突发、起火三个词同时出现在文本中,也可是荆州、出事、出大事、车祸、起火五个字同时出现在文本中,但必须要有荆州,身边事、突发、出事、出大事、事故这五个词的至少一个,以及车祸、起火、火灾、冲突这四个词的至少一个,即三个()部分须同时出现。
步骤s2、基于所述关键词方案在数据库中获取初步匹配文本。
具体地,在本发明中基于关键词方案在数据库如全网文本中进行文本检索,从而得到初步匹配文本。
步骤s3、对所述初步匹配文本进行分词,以获取分词结果。
具体地,分词就是将连续的字序列按照一定的规范重新组合成词序列的过程。在本发明中,分词用的是字典动态更新的方式,即在一般的分词方法上,动态更新自定义的关键词,以保证关键词有分词出来的基础;同时也会根据分词逻辑判断文本中关键词是否成词。另外,在分词的时候会停用词过滤。
步骤s4、将所述关键词方案拆解为多个独立关键词方案,所述独立关键词方案由每个独立关键词组中的一个关键词并列组成。
具体地,所述关键词方案实质上是多个独立关键词方案的组合,故需要进行逐一拆解。例如,对于关键词方案:国产+(质量|衣服|鞋子|商品)+(印度|日本),可以拆解为如下八个独立关键词方案:
(1)国产+质量+印度
(2)国产+质量+日本
(3)国产+衣服+印度
(4)国产+衣服+日本
(5)国产+鞋子+印度
(6)国产+鞋子+日本
(7)国产+商品+印度
(8)国产+商品+日本
步骤s5、当所述分词结果命中至少一个独立关键词方案时,对所述初步匹配文本进行关键词抽取,并获取文本特征。
具体地,将所述分词结果逐一与所述独立关键词方案相匹配,判断是否命中。若未命中,则表示所述初步匹配文本不是匹配文本信息,当前文本信息匹配流程结束;若命中,则表示所述初步匹配文本可能是匹配文本信息,需对所述初步匹配文本进行关键词抽取,并获取文本特征。
于本发明一实施例中,基于textrank算法对所述初步匹配文本进行关键词抽取,以根据特定词性、停用词等筛选有效的词/词组。
textrank是一种文本排序算法,是由谷歌的网页重要性排序算法pagerank算法的文本应用。该算法能够从一个给定的文本中提取出该文本的关键词/关键词组。pagerank的核心思想有两点;(1)如果一个网页背很多其他网页链接到,说明这个网页的重要性(pagerank值,pr)比较高;(2)如果一个pr值很高的网页链接到一个其他网页,被链接到的网页pr值也会相对高。textrank基于这种思想,将网页的链接关系改为词之间的共线关系,且词之间没有指向关系。因此把pagerank的有向边改为无向边。其公式如下:
其中,vi表示词i的权重,vj是所有与i相关联的词。ωji表示词i和j的相关程度,用词i和词j之间以一定窗口为限制相连的边数计算。d是阻尼系数,一般为0.85。该公式迭代直至收敛可得textrank的词重要性。
通过textrank算法抽取关键词后,获取文本特征。于本发明一实施例中,所述文本特征包括文本内容特征和标题内容特征;所述文本内容特征包括文本排序特征、文本分数特征、文本排序分数融合特征、文本关键词匹配特征、文本方案特征和文本方案深度特征;所述标题内容特征包括标题排序特征、标题分数特征、标题排序分数融合特征、标题关键词匹配特征、标题方案特征和标题方案深度特征。
步骤s6、根据所述文本特征基于决策树模型获取文本信息匹配分值,并在所述文本信息匹配分值大于预设阈值时判断所述初步匹配文本为最终匹配文本。
具体地,将所述文本特征作为训练好的决策树模型的输入,所述决策树模型则输出文本信息匹配分值。若所述文本信息匹配分值大于预设阈值,则判断所述初步匹配文本为最终匹配文本;若所述文本信息匹配分值不大于所述预设阈值,则判断所述初步匹配文本不为最终匹配文本。
于本发明一实施例中,所述决策树模型基于带标注的数据进行有监督建模生成。所述带标注的数据是有行业经验和产品经验的专家人工标注产生的。
如图2所示,于一实施例中,本发明的基于关键词的文本信息精准匹配系统包括构建模块21、获取模块22、分词模块23、拆解模块24、抽取模块25和匹配模块26。
所述构建模块21用于构建关键词方案,所述关键词方案包括至少两个独立关键词组,每个独立关键词组包括一个或多个关键词。
所述获取模块22与所述构建模块21相连,用于基于所述关键词方案在数据库中获取初步匹配文本。
所述分词模块23与所述获取模块22相连,用于对所述初步匹配文本进行分词,以获取分词结果。
所述拆解模块24与所述构建模块21相连,用于将所述关键词方案拆解为多个独立关键词方案,所述独立关键词方案由每个独立关键词组中的一个关键词并列组成。
所述抽取模块25与所述分词模块23和所述拆解模块24相连,用于当所述分词结果命中至少一个独立关键词方案时,对所述初步匹配文本进行关键词抽取,并获取文本特征。
所述匹配模块26与所述抽取模块25相连,用于根据所述文本特征基于决策树模型获取文本信息匹配分值,并在所述文本信息匹配分值大于预设阈值时判断所述初步匹配文本为最终匹配文本。
其中,构建模块21、获取模块22、分词模块23、拆解模块24、抽取模块25和匹配模块26的结构和原理与上述基于关键词的文本信息精准匹配方法中的步骤一一对应,故在此不再赘述。
需要说明的是,应理解以上装置的各个模块的划分仅仅是一种逻辑功能的划分,实际实现时可以全部或部分集成到一个物理实体上,也可以物理上分开。且这些模块可以全部以软件通过处理元件调用的形式实现;也可以全部以硬件的形式实现;还可以部分模块通过处理元件调用软件的形式实现,部分模块通过硬件的形式实现。例如,x模块可以为单独设立的处理元件,也可以集成在上述装置的某一个芯片中实现,此外,也可以以程序代码的形式存储于上述装置的存储器中,由上述装置的某一个处理元件调用并执行以上x模块的功能。其它模块的实现与之类似。此外这些模块全部或部分可以集成在一起,也可以独立实现。这里所述的处理元件可以是一种集成电路,具有信号的处理能力。在实现过程中,上述方法的各步骤或以上各个模块可以通过处理器元件中的硬件的集成逻辑电路或者软件形式的指令完成。
例如,以上这些模块可以是被配置成实施以上方法的一个或多个集成电路,例如:一个或多个特定集成电路(applicationspecificintegratedcircuit,简称asic),或,一个或多个微处理器(digitalsignalprocessor,简称dsp),或,一个或者多个现场可编程门阵列(fieldprogrammablegatearray,简称fpga)等。再如,当以上某个模块通过处理元件调度程序代码的形式实现时,该处理元件可以是通用处理器,例如中央处理器(centralprocessingunit,简称cpu)或其它可以调用程序代码的处理器。再如,这些模块可以集成在一起,以片上系统(system-on-a-chip,简称soc)的形式实现。
本发明的存储介质上存储有计算机程序,其特征在于,该程序被处理器执行时实现上述的基于关键词的文本信息精准匹配方法。所述存储介质包括:rom、ram、磁碟、u盘、存储卡或者光盘等各种可以存储程序代码的介质。
如图3所示,于一实施例中,本发明的终端包括:处理器31及存储器32。
所述存储器32用于存储计算机程序。
所述存储器32包括:rom、ram、磁碟、u盘、存储卡或者光盘等各种可以存储程序代码的介质。
所述处理器31与所述存储器32相连,用于执行所述存储器32存储的计算机程序,以使所述终端执行上述的基于关键词的文本信息精准匹配方法。
优选地,所述处理器31可以是通用处理器,包括中央处理器(centralprocessingunit,简称cpu)、网络处理器(networkprocessor,简称np)等;还可以是数字信号处理器(digitalsignalprocessor,简称dsp)、专用集成电路(applicationspecificintegratedcircuit,简称asic)、现场可编程门阵列(fieldprogrammablegatearray,简称fpga)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件。
综上所述,本发明的基于关键词的文本信息精准匹配方法、系统、存储介质、终端结合关键词和文本分类,融入了强业务解释性的特征,大大提升了文本信息匹配的精确程度;无需极大量数据,即可实现文本信息匹配;文本信息匹配所采用的特征融合了文本特征和业务特征,极具创新性;在实际应用场景中可行有效,实用性强。所以,本发明有效克服了现有技术中的种种缺点而具高度产业利用价值。
上述实施例仅例示性说明本发明的原理及其功效,而非用于限制本发明。任何熟悉此技术的人士皆可在不违背本发明的精神及范畴下,对上述实施例进行修饰或改变。因此,举凡所属技术领域中具有通常知识者在未脱离本发明所揭示的精神与技术思想下所完成的一切等效修饰或改变,仍应由本发明的权利要求所涵盖。
- 文档格式推荐模型训练方法、装...
- 一种基于AC自动机的字符串多...
- 一种基于向量检索的对话应答方...
- 测试用例查找方法、装置、设备...
- 一种基于匹配算法的视觉问答方...
- 引导语的生成方法及装置、电子...
- 一种基于相似性的知识库问答实...
- 一种智能交互方法、装置及设备...
- 人机对话方法、装置、设备及存...
- 人机对话方法及系统、计算机设...
- 还没有人留言评论。精彩留言会获得点赞!
- 从文本中抽取关键词的方法和装置制造方法
- 一种单篇文本关键词的提取方法
- 一种文本的候选关键词的提取方法
- 一种海量文本数据关键词的快速查找方法
- 基于关键词的文本的标签提取方法及装置的制作方法
- 具有使得能够实现多维中的不同访问模式的配线结构的存储器架构的制作方法与工艺
- 一种甘蓝型油菜萝卜细胞质不育恢复系的选育方法及在甘蓝型油菜育种上的应用与流程
- 数据存储方法、数据库存储节点故障处理方法及装置与流程
- 用于访问服务的系统和方法与流程
- 排序集数据的存储方法及装置与流程
- 一种移动式小型地面控制基站的制作方法与工艺
- 电商订单提醒智能音箱的制作方法与工艺
- 一种智能无功补偿装置的制作方法
- 一种冷链运输远程监控系统的制作方法与工艺
- 一种737大气数据计算机测试台的制作方法与工艺
- 一种采集植绥螨的工具的制作方法
- 井场数据采集控制箱的制作方法
- Jzy-pad建筑云建筑工程质量安全现场检查终端的制作方法
- 一种数据采集装置和一种数据采集箱的制作方法
- 车辆网络访问控制方法及装置的制造方法
- 一种车辆网络诊断控制方法及装置的制造方法
- 车辆网络访问控制方法及装置的制造方法
- 一种车辆网络诊断控制方法及装置的制造方法
- 一种用于电动工具的数据采集控制器及数据采集方法
- Can总线的数据分析方法和装置的制造方法
- 一种透明文件加密技术的制作方法
- 基于场景帧指纹的视频认证方法
- 一种基于tpm的云存储数据加密方法
- 不同移动终端平台与后端服务器的数据交互方法及系统的制作方法
- 一种智能终端app应用程序与服务器数据通信加解密方法
- 一种增强的基于轨迹重构的隐私保护方法
- 一种基于数据分割的数据安全保护方法及装置的制造方法
- 一种基于立方体嵌套翻转的密钥生成方法
- 一种基于二维码的进站身份认证方法
- 数据传输方法和装置的制造方法