芯片后端设计和版图设计方法、工具、芯片及存储介质与流程
本发明涉及集成电路设计技术领域,尤其涉及一种芯片后端设计和版图设计方法、工具、芯片及存储介质。
背景技术:
芯片后端设计时间在整个芯片设计周期中占据了很大的比重,因此,为了提高芯片的设计效率,如何缩短芯片后端设计的时间变的极为重要。
在集成电路布图设计的过程中,由于集成电路后端设计的流程长、环节多,因此设计流程非常复杂。随着芯片规模越来越大,竞争越来越激烈,对芯片后端设计的要求也越来越高。目前,在进行芯片的后端设计时,需要通过工程变更指令(engineerchangingorder,eco)流程的不断迭代来修复设计中所存在的问题。然而,布线工具和静态时序工具之间的不一致性会导致后端设计过程中的迭代次数的增多,严重影响了芯片的按时流片。
技术实现要素:
本申请实施例提供了一种芯片后端设计和版图设计方法、工具、芯片及存储介质,能够大大减少eco流程的迭代次数,进而缩短芯片后端设计的时间,有效提高芯片设计效率。
本申请实施例的技术方案是这样实现的:
第一方面,本申请实施例提供了一种芯片后端设计方法,所述方法包括:
导入库文件和设计数据;其中,所述设计数据包括芯片前端设计后获得的门级网表和时序约束;
布线pnr工具基于所述库文件和所述设计数据进行布线处理时,在执行完优化时序命令之后,执行第一写出命令,获得第一报告、第一网表以及第一文件;
基于所述第一网表和所述第一文件,静态时序分析sta工具执行第一分析命令,生成第二报告;
基于所述第一报告和所述第二报告,对所述pnr工具的信息进行修正,获得修正后信息;
基于所述库文件和所述设计数据,所述sta工具执行第二分析命令,获得时序报告;
若所述时序报告存在时序违规,则执行变更命令,对所述pnr工具的、所述修正后信息以外的其他信息进行eco处理;
所述sta工具继续执行下一个分析命令,直到获得的时序报告不存在时序违规,输出版图。
第二方面,本申请实施例提供了一种版图设计方法,所述版图设计方法应用于eda工具,所述方法包括:
接收第四启动命令,启动版图设计流程,并解析所述第四启动命令中携带的库文件和设计数据;其中,所述设计数据包括芯片前端设计后获得的门级网表和时序约束;
在基于所述库文件和所述设计数据,调用布线pnr工具进行所述版图设计流程中的布线处理时,若执行完优化时序命令,则生成第二停止命令和第二写出命令;
响应所述第二停止命令,中止所述布线处理,同时响应所述第二写出命令,获取第三报告、第二网表以及第二文件;
基于所述第二网表和所述第二文件,调用sta工具进行静态时序分析处理,生成第四报告;
接收第五启动命令,启动校正流程,并基于所述第三报告和所述第四报告对所述pnr工具的信息进行修正,获得修正后信息;
接收第六启动命令,基于所述修正后信息继续进行所述版图设计流程,输出版图。
第三方面,本申请实施例提供了一种后端设计工具,所述后端设计工具包括:导入单元,第一获取单元,第一生成单元,第一修正单元,变更单元,第一输出单元,
所述导入单元,用于导入库文件和设计数据;其中,所述设计数据包括芯片前端设计后获得的门级网表和时序约束;
所述第一获取单元,用于布线pnr工具基于所述库文件和所述设计数据进行布线处理时,在执行完优化时序命令之后,执行第一写出命令,获得第一报告、第一网表以及第一文件;
所述第一生成单元,用于基于所述第一网表和所述第一文件,静态时序分析sta工具执行第一分析命令,生成第二报告;
所述第一修正单元,用于基于所述第一报告和所述第二报告,对所述pnr工具的信息进行修正,获得修正后信息;
所述第一获取单元,还用于基于所述库文件和所述设计数据,所述sta工具执行第二分析命令,获得时序报告;
所述变更单元,用于若所述时序报告存在时序违规,则执行变更命令,对所述pnr工具的、所述修正后信息以外的其他信息进行eco处理;
所述第一获取单元,还用于所述sta工具继续执行下一个分析命令,直到获得的时序报告不存在时序违规;
所述第一输出单元,用于输出版图。
第四方面,本申请实施例提供了一种后端设计工具,所述后端设计工具包括第一处理器、存储有所述第一处理器可执行指令的第一存储器,当所述指令被所述第一处理器执行时,实现如上所述的芯片后端设计方法。
第五方面,本申请实施例提供了一种eda工具,所述eda工具包括:接收单元,解析单元,调用单元,第二生成单元,中止单元,第二获取单元,第二修正单元,第二输出单元,
所述接收单元,用于接收第四启动命令,启动版图设计流程;
所述解析单元,用于解析所述第四启动命令中携带的库文件和设计数据;其中,所述设计数据包括芯片前端设计后获得的门级网表和时序约束;
所述调用单元,用于在基于所述库文件和所述设计数据,调用布线pnr工具进行所述版图设计流程中的布线处理时;
所述第二生成单元,用于若执行完优化时序命令,则生成第二停止命令和第二写出命令;
所述中止单元,用于响应所述第二停止命令,中止所述布线处理;
所述第二获取单元,用于响应所述第二写出命令,获取第三报告、第二网表以及第二文件;
所述调用单元,还用于基于所述第二网表和所述第二文件,调用sta工具进行静态时序分析处理,生成第四报告;
所述接收单元,还用于接收第五启动命令,启动校正流程;
所述第二修正单元,用于基于所述第三报告和所述第四报告对所述pnr工具的信息进行修正,获得修正后信息;
所述接收单元,还用于接收第六启动命令;
所述第二输出单元,用于基于所述修正后信息继续进行所述版图设计流程,输出版图。
第六方面,本申请实施例提供了一种eda工具,所述eda工具包括第二处理器、存储有所述第二处理器可执行指令的第二存储器,当所述指令被所述第二处理器执行时,实现如上所述的版图设计方法。
第七方面,本申请实施例提供了一种芯片,所述芯片包括可编程逻辑电路和/或程序指令,当所述芯片运行时,实现如上所述的芯片后端设计方法和版图设计方法。
第八方面,本申请实施例提供了一种计算机可读存储介质,其上存储有程序,应用于后端设计工具和eda工具中,所述程序被第一处理器执行时,实现如上所述的芯片后端设计方法,所述程序被第一处理器执行时,实现如上所述的版图设计方法。
本申请实施例提供了一种芯片后端设计和版图设计方法、工具、芯片及存储介质,后端设计工具导入库文件和设计数据;其中,设计数据包括芯片前端设计后获得的门级网表和时序约束;布线pnr工具基于库文件和设计数据进行布线处理时,在执行完优化时序命令之后,执行第一写出命令,获得第一报告、第一网表以及第一文件;基于第一网表和第一文件,静态时序分析sta工具执行第一分析命令,生成第二报告;基于第一报告和第二报告,对pnr工具的信息进行修正,获得修正后信息;基于库文件和设计数据,sta工具执行第二分析命令,获得时序报告;若时序报告存在时序违规,则执行变更命令,对pnr工具的、修正后信息以外的其他信息进行eco处理;sta工具继续执行下一个分析命令,直到获得的时序报告不存在时序违规,输出版图。也就是说,在本申请中,在routing阶段,插入一个校正流程,根据pnr工具获得的第一报告和sta工具获得的第二报告进行精确的修正处理,以对pnr工具和sta工具的相关性进行校正,从而可以解决由于pnr工具和sta工具的不一致所造成的eco流程中迭代次数增多的问题,能够大大减少eco流程的迭代次数,进而缩短芯片后端设计的时间,有效提高芯片设计效率。
附图说明
图1为后端设计流程的示意图;
图2为eco流程的示意图;
图3为芯片后端设计方法的实现流程示意图一;
图4为芯片后端设计方法的实现流程示意图二;
图5为芯片后端设计方法的实现流程示意图三;
图6为本申请提出的芯片的后端设计流程的示意图;
图7为版图设计方法的实现流程示意图;
图8为后端设计工具的组成结构示意图一;
图9为后端设计工具的组成结构示意图二;
图10为eda工具的组成结构示意图一;
图11为eda工具的组成结构示意图二。
具体实施方式
下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述。可以理解的是,此处所描述的具体实施例仅用于解释相关申请,而非对该申请的限定。另外还需要说明的是,为了便于描述,附图中仅示出了与有关申请相关的部分。
对本发明实施例进行进一步详细说明之前,对本发明实施例中涉及的名词和术语进行说明,本发明实施例中涉及的名词和术语适用于如下的解释。
性能、功耗、面积(performence、power、area,ppa)。
布局布线(placeandroute,pnr)。其中,place为布局,route为布线。
电子设计自动化(electronicsdesignautomation,eda),是指利用计算机辅助设计(computeraideddesign,cad)软件,来完成超大规模集成电路(verylargescaleintegrationcircuit,vlsi)芯片的功能设计、综合、验证、物理设计(包括布局、布线、版图、设计规则检查等)等流程的设计方式。
几何数据标准(geometrydatastandard,gds),记录有芯片制作前的版图信息。
工程变更指令(engineerchangingorder,eco),通常使用于新产品开发完成后的工程变更,工程部门确认必要的变更后,发出文件交相关单位会签,以确保库存品、在制品被妥善处理,是立即变更、使用完毕后变更等,销售单位、制造单位、物料单位都要同意且采取必要行动,通常eco牵涉范围大,导入时程长,需要严谨之系统管理之。
时钟树综合(clocktreesynthesis,cts)就是对design的时钟树进行综合。主要的目的是让每个clock都能够在尽量短的时间内传达到它们驱动的所有d类型触发器(dff)。
静态时序分析(statictiminganalysis,sta),套用特定的时序模型(timingmodel),针对特定电路分析其是否违反设计者给定的时序限制(timingconstraint)。也就是说,sta经由完整的分析方式判断集成电路(integratedcircuit,ic)是否能够在使用者的时序环境下正常工作,对确保ic品质之课题,提供一个不错的解决方案。以分析的方式区分,sta可分为path-based及block-based两种。
gdsii流格式,常见的缩写gdsii,是一个数据库文件格式。它用于集成电路版图的数据转换,并成为事实上的工业标准。gdsii是一个二进制文件,其中含有集成电路版图中的平面的几何形状,文本或标签,以及其他有关信息并可以由层次结构组成。gdsii数据可用于重建所有或部分的版图信息。它可以用作制作光刻掩膜版。
eda工具软件(edatools)。
倒装芯片(flipchip),是一种无引脚结构,一般含有电路单元。设计用于通过适当数量的位于其面上的锡球(导电性粘合剂所覆盖),在电气上和机械上连接于电路。
门级网表(gate-levelnetlist),在电路设计中,网表(netlist)是用于描述电路元件相互之间连接关系的,一般来说是一个遵循某种比较简单的标记语法的文本文件。门级(gate-level)指的是网表描述的电路综合级别。顾名思义,门级网表中,描述的电路元件基本是门(gate)或与此同级别的元件。
深亚微米(deepsub-micron),通常把0.35-0.8μm及其以下称为亚微米级,0.25um及其以下称为深亚微米,0.05um及其以下称为纳米级。深亚微米制造的关键技术主要包括紫外光刻技术、等离子体刻蚀技术、离子注入技术、铜互连技术(不是同互连)等。国际上集成电路的主流生产工艺技术为0.010μm-0.028μm。
可测性设计(designfortest,dft),芯片内部往往都自带测试电路,dft的目的就是在设计的时候就考虑将来的测试。dft的常见方法就是,在设计中插入扫描链,将非扫描单元(如寄存器)变为扫描单元。
进一步地,本申请的实施例中还可能涉及到以下名词:分组(group)、分区(region)、时序约束(timingconstrain)、电源环(powerring)、时序分析(timinganalysis)、线,连线(net)、拥塞(congestion)、引脚(pin)、时序引擎(timingengine)、行通道(row)、单元(cell)、基座(pad)、时钟树(clocktree)、缓冲器(buffer)、缓冲器树(buffertree)、填充单元(fillcell)、时钟树延迟(clockinsertiondelay)、兆单元(megacell)、时钟扭曲(clockskew)、传递时间(transitiontime)、交付(tapout)、标准单元(standardcell)、建立/维持时序冲突(setup/holdtimeviolation)、金属(布线)层(layer)、脚本(script)。内建自测(built-inself-test,bist)。
芯片设计无疑是芯片制作过程中的重要一步,而芯片设计又可分为前端设计和后端设计。前端主要负责逻辑实现,通常是使用verilog、vhdl之类语言,进行行为级的描述。而后端,主要负责将前端的设计变成真正的原理图和布局(schematic&layout)、流片、量产。打个比喻来说,前端就像是做蓝图的,可以为功能性、结构性的东西。而后端则是将蓝图变成真正的高楼。
其中,芯片后端设计主要包括以下几部分:
1、可测性设计(designfortest,dft)
芯片内部往往都自带测试电路,dft的目的就是在设计的时候就考虑将来的测试。dft的常见方法就是,在设计中插入扫描链,将非扫描单元(如寄存器)变为扫描单元。
2、布局规划(floorplan)
3、cts
简单点说就是时钟的布线。由于时钟信号在数字芯片的全局指挥作用,它的分布应该是对称式的连到各个寄存器单元,从而使时钟从同一个时钟源到达各个寄存器时,时钟延迟差异最小。这也是为什么时钟信号需要单独布线的原因。
4、布线(pnr)
这里的布线就是普通信号布线,包括各种标准单元(基本逻辑门电路)之间的走线。比如平常听到的0.13um工艺,或者说90nm工艺,实际上就是这里金属布线可以达到的最小宽度,从微观上看就是mos管的沟道长度。
5、寄生参数提取
由于导线本身存在的电阻,相邻导线之间的互感,耦合电容在芯片内部会产生信号噪声,串扰和反射。这些效应会产生信号完整性问题,导致信号电压波动和变化,如果严重就会导致信号失真错误。提取寄生参数进行再次的分析验证,分析信号完整性问题是非常重要的。
6、版图物理验证
对完成布线的物理版图进行功能和时序上的验证,验证项目很多,如布局与示意图(layoutvsschematic,lvs)验证,简单说,就是版图与逻辑综合后的门级电路图的对比验证;设计规则检查(designrulechecking,drc),检查连线间距,连线宽度等是否满足工艺要求,电气规则检查(electricalrulechecking,erc),检查短路和开路等电气规则违例等等。
实际的后端流程还包括电路功耗分析,以及随着制造工艺不断进步产生的可制造性设计(dfm)问题。
物理版图验证完成也就是整个芯片设计阶段完成,下面的就是芯片制造了。物理版图以gdsii的文件格式交给芯片代工厂在晶圆硅片上做出实际的电路,再进行封装和测试,就得到了实际的芯片。
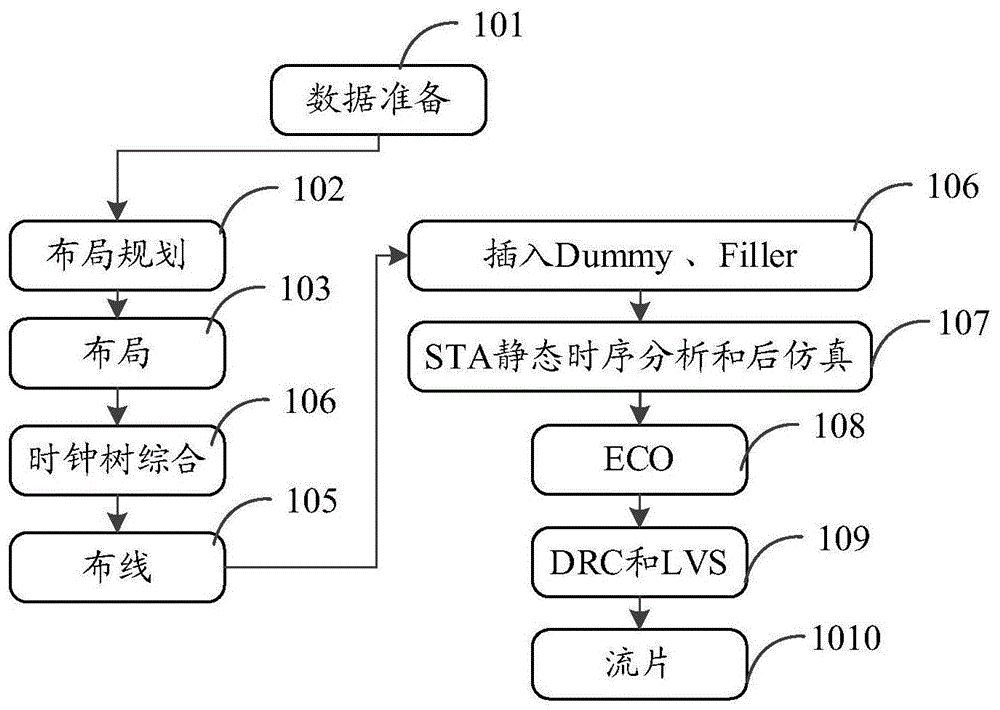
图1为后端设计流程的示意图,如图1所示,目前,芯片后端设计所设计所涉及到的流程主要可以包括以下步骤:
步骤101、数据准备。
对于cdn的siliconensemble而言后端设计所需的数据主要有是foundry厂提供的标准单元、宏单元和i/opad的库文件,它包括物理库、时序库及网表库,分别以.lef、.tlf和.v的形式给出。前端的芯片设计经过综合后生成的门级网表,具有时序约束和时钟定义的脚本文件和由此产生的.gcf约束文件以及定义电源pad的def(designexchangeformat)文件。(对synopsys的astro而言,经过综合后生成的门级网表,时序约束文件sdc是一样的,pad的定义文件--tdf,.tf文件--technologyfile,foundry厂提供的标准单元、宏单元和i/opad的库文件就与fram,cellview,lmview形式给出(milkway参考库anddb,libfile)。
步骤102、布局规划。
主要是标准单元、i/opad和宏单元的布局。i/opad预先给出了位置,而宏单元则根据时序要求进行摆放,标准单元则是给出了一定的区域由工具自动摆放。布局规划后,芯片的大小,core的面积,row的形式、电源及地线的ring和strip都确定下来了。如果必要在自动放置标准单元和宏单元之后,可以先做一次pna(powernetworkanalysis)--irdropandem.
步骤103、布局。
布局规划后,宏单元、i/opad的位置和放置标准单元的区域都已确定,这些信息se(siliconensemble)会通过def文件传递给pc(physicalcompiler),pc根据由综合给出的.db文件获得网表和时序约束信息进行自动放置标准单元,同时进行时序检查和单元放置优化。如果使用的是pc+astro,那可以用write_milkway,read_milkway传递数据。
步骤104、时钟树综合(ctsclocktreesynthesis)。
芯片中的时钟网络要驱动电路中所有的时序单元,所以时钟源端门单元带载很多,其负载延时很大并且不平衡,需要插入缓冲器减小负载和平衡延时。时钟网络及其上的缓冲器构成了时钟树。一般要反复几次才可以做出一个比较理想的时钟树。---clockskew.
步骤105、布线(routing)。globalroute--trackassign--detailrouting--routingoptimization布线是指在满足工艺规则和布线层数限制、线宽、线间距限制和各线网可靠绝缘的电性能约束的条件下,根据电路的连接关系将各单元和i/opad用互连线连接起来,这些是在时序驱动(timingdriven)的条件下进行的,保证关键时序路径上的连线长度能够最小。--timingreportclear。
步骤106、dummymetal的增加和filler的插入(padfliier,cellfiller)。
filler指的是标准单元库和i/opad库中定义的与逻辑无关的填充物,用来填充标准单元和标准单元之间,i/opad和i/opad之间的间隙,它主要是把扩散层连接起来,满足drc规则和设计需要。
foundry厂都有对金属密度的规定,使其金属密度不要低于一定的值,以防在芯片制造过程中的刻蚀阶段对连线的金属层过度刻蚀从而降低电路的性能。加入dummymetal是为了增加金属的密度。
步骤107、sta静态时序分析和后仿真。
时钟树插入后,每个单元的位置都确定下来了,工具可以提出globalroute形式的连线寄生参数,此时对延时参数的提取就比较准确了。se把.v和.sdf文件传递给primetime做静态时序分析。确认没有时序违规后,将这来两个文件传递给前端人员做后仿真。对astro而言,在detailrouting之后,用starrcxt参数提取,生成的e.v和.sdf文件传递给primetime做静态时序分析,那将会更准。
步骤108、eco(engineeringchangeorder)。
针对静态时序分析和后仿真中出现的问题,对电路和单元布局进行小范围的改动.
步骤109、drc和lvs。drc是对芯片版图中的各层物理图形进行设计规则检查(spacing,width),它也包括天线效应的检查,以确保芯片正常流片。lvs主要是将版图和电路网表进行比较,来保证流片出来的版图电路和实际需要的电路一致。drc和lvs的检查--eda工具synopsyhercules/mentorcalibre/cdndracula进行的.astroalsoincludelvs/drccheckcommands.
步骤1010、流片。在所有检查和验证都正确无误的情况下把最后的版图gdsⅱ文件传递给foundry厂进行掩膜制造。
在芯片的后端设计过程中,eco是不能忽略的关键路径,一个良好的eco流程、策略可以加速流片的时间。
图2为eco流程的示意图,如图2所示,目前,常规的eco流程主要可以包括以下步骤:
步骤108a、判断是否存在时序违规,如果存在,则执行步骤108b,否则执行步骤109。
步骤108b、进行eco修正处理,接着返回步骤106,继续进行下一次静态时序分析。
由于pnr工具与sta工具的相关性比较差,尤其当pnr跟sta工具来自于不同供应商时更为严重,例如pnr采用cadence的innovus工具,sta采用synopsis的primetime,两者之间的一致性较差,而这种不一致性会导致后端设计在进行timingeco时需要多轮迭代才能timingmeet,甚至存在不能fix的风险,使得芯片无法按时tapeout。
为了解决现有的问题,在本申请中,在routing阶段,插入一个校正流程,根据pnr工具获得的第一报告和sta工具获得的第二报告进行精确的修正处理,以对pnr工具和sta工具的相关性进行校正,从而可以解决由于pnr工具和sta工具的不一致所造成的eco流程中迭代次数增多的问题,能够大大减少eco流程的迭代次数,进而缩短芯片后端设计的时间,有效提高芯片设计效率。
下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述。
本申请一实施例提供了一种芯片后端设计方法,图3为芯片后端设计方法的实现流程示意图一,如图3所示,在本申请的实施例中,芯片后端设计方法可以包括以下步骤:
步骤201、导入库文件和设计数据;其中,设计数据包括芯片前端设计后获得的门级网表和时序约束。
在本申请的实施例中,前端设计已经完成之后,后端设计工具在进行芯片的后端设计时,可以先导入库文件和设计数据。其中,导入库文件和设计数据也可以理解为芯片的后端设计流程的开始。
需要说明的是,在本申请的实施例中,后端设计工具在进行后端设计时可以先导入需要的数据。具体地,这些数据具体可以包括库文件和设计数据,其中,库文件可以为芯片代工厂(foundry厂)提供的标准单元、宏单元和i/opad的库文件,它包括物理库、时序库及网表库,分别以.lef、.tlf和.v的形式给出。而设计数据可以为芯片前端设计经过综合后生成的门级网表,具有时序约束和时钟定义的脚本文件和由此产生的.gcf约束文件。
进一步地,在本申请的实施例中,后端设计工具即为eda工具,可以包括不同供应商提供的多种工具,具体地,在执行不同的命令、进行不同类型的处理时,可以使用不同的后端设计工具。例如,常用的布局pnr工具有synopsys公司的iccompiler、astro和candance公司的soc-enconter。其中,iccompiler是synopsys公司继astro之后推出的另一款pnr工具,astro常用于10nm工艺一下超深亚微米级的布局布线。
示例性的,在本申请中,在进行可测性设计dft时,选择使用的dft工具可以为synopsys的dftcompiler;在进行布局规划时,使用的工具可以为synopsys的astro;在进行时钟树综合cts时,使用的cts工具可以为synopsysphysicalcompiler;在进行布线时,使用的pnr工具可以为synopsys的astro;在进行寄生参数提取的提取时,使用的工具可以为synopsys的star-rcxt;在进行版图物理验证时,使用的工具可以为synopsys的hercules;在进行静态时序分析sta时,使用的sta工具可以为synopsys的primetime。
可以理解的是,在本申请中,芯片前端设计达到要求之后,可以输出相应的文件,如门级网表,sdc文件等,以便后续的时序分析和验证。通过静态时序分析和形式验证来验证综合的正确与否,其中静态时序分析可以更加准确地分析时序,从而检查综合的时序是否正确;而形式验证则用数学的方法验证综合出的电路与原电路的功能是否一致。在验证通过后才可以进行下一步的布局布线,否则还要重新综合。
接着,便可以进入物理设计阶段,即芯片后端设计。芯片后端设计中,其实是把前端涉及所生成的门级网表转化成foundry可用于掩膜的版图信息。
需要说明的是,在本申请中,芯片的后端设计流程中,后端设计工具需要的前端设计输出的设计数据至少包括门级网表(gatelevelnetlist),时序约束(timingconstraint)和时序分析报告(timinganalysisreport)。
可以理解的是,后端设计工具在导入设计数据(网表文件)之前,可以先对设计数据的质量进行检测,确认已消除其中存在的错误和瑕疵,例如,可以检查有无以下情况:文法错误,连接短路,无任何连接的net,无驱动的输入引脚(pin),assign语句,线(wire)类型以外的net,使用了由"\"开始的特别字符,数据总线的写法,名字的长度等,不同的厂家和软件对此都会有一些限制,因此建议定义一套比较严格的网表书写规则。
示例性的,在本申请中,网表书写规则可以包括不许有"无任何连接的net"和"无驱动的输入pin",无assign语句,只允许wire型net,所有名字只许使用大小写英文字母,数字和下划线,头一个文字是英文字母,长度小于1024,模块之间的调用一律使用explicit格式。
进一步地,在本申请的实施例中,如果需要进行可测试性dft、自动测试格式生成,后端设计工具还需要检查是否符合扫描链(scanchain)和存储器内建自测(memorybist)的设计要求。
接着,还需要检查时序约束(timingconstrain)文件中的时序设定是否完整、合理。最后需要流览时序分析报告,如果有setupviolation存在的话,一般不允许大于时钟周期的10%,而holdviolation暂时可以不解决,留到布线后再去除。
步骤202、pnr工具基于库文件和设计数据进行布线处理时,在执行完优化时序命令之后,执行第一写出命令,获得第一报告、第一网表以及第一文件。
在本申请的实施例中,在导入库文件和设计数据之后,pnr工具便可以基于库文件和设计数据进行布线处理,在布线处理的过程中,在执行完优化时序命令之后,pnr工具可以执行第一写出命令,获得第一报告、第一网表以及第一文件。
进一步地,在本申请的实施例中,pnr工具进行的布线处理即为普通信号布线,具体可以包括各种标准单元(基本逻辑门电路)之间的走线。其中,常见的0.13um工艺,或者90nm工艺,实际上就是在布线处理时金属布线可以达到的最小宽度,从微观上看就是mos管的沟道长度。
示例性的,在本申请中,pnr工具可以为synopsys的astro。
可以理解的是,在本申请的实施例中,在布线处理时,可以先留出模拟信号用的走线和隔离空间。然后考虑时钟树的布线,此时因为还没有数字信号走线,所以可以有很大的自由来选择用传输速度较快的金属层作时钟树布线。最后是数字信号布线。如果布线软件可以考虑时序要求,建议使用这一功能。如果没有这个功能,并且又有一些关键路径(criticalpath),则可以加权给这些net,让它们优先被布线。布好线的结果中,如果没有大面积或集中在一起的布线问题,可以暂时不去修正自动布线产生的小问题,而先作sta,这是由于在sta之后很可能会有布线工程变更(routingeco)需要进行。
需要说明的是,在本申请的实施例中,布线相关的route命令主要可以包括:route_auto、route_opt、route_eco、route_group、route_global、route_track、route_detail。
具体地,route_auto为绕线,主要指信号线。一般情况下,时钟树的net在cts阶段已经绕线好了,当然,如果时钟树没有绕线,route_auto可以把clocktree和signalnet一起做绕线。route_auto在pnr流程中只用一次。
route_auto,是由三个子命令组成,且是automatically完成的。其中,route_auto=route_global+route_track+route_detail,反之,如果不愿意自动(auto)执行者三个子命令,也可以手动跑route_global+route_track+route_detail,效果是相同的。
具体地,route_global为快速连线,但不创建真实的金属(只创建了via);route_track根据route_global的结果,加上真实的金属,但没有考虑drc;route_detail为修drc。
route_global,快速连线。在执行完route_global后,所有的net都连上了。但是,没有放真实的金属,仅仅是一根根没有宽度的细线。这些细线有layer信息,也有真实的孔。例如,对于一个net,它是从一个buffer_x的zpin输出到下一个buffer_y的ipin,从buffer_x的zpin出来,就有一个via12,然后连一段m2的细线,又通过via23走到m3,然后m3又通过via23,m2和via12连到了buffer_y的apin。如此,便是一条完整的globalroute。它有四个via和三段连线。
除了细线和孔,globalroute还有很多有用的信息,比如ndr。有些net有两倍的space需求,globalroute会遵守,有些net只能放在某一层,globalroute也能遵守。
可以说,对net的约束,基本全靠globalroute来完成。同时,globalroute的结果,很大程度上决定了最后的绕线质量。
route_global用处非常非常大,可以说在pnr里无处不有。比如initialdrc调用globalroute可以把buffertree长的更好;placer调用route_global来评估congestion;optimizer调用route_global做pre-route的rc评估;cts调用globalroute长时钟树,甚至route_eco也会调用globalroute来连断开的线。
route_track,根据globalroute的结果创建金属(shape),不考虑drc。route_track完成之后,细线消失了,变成了有宽度的金属。由于不考虑别的cost,因此route_track过程非常快,但是,也有timing_driven和crosstalk_driven。
route_detail(-incr),修drc。route_track后的shape肯定存在大量的drc,越复杂的工艺drc越多。修drc全靠route_detail这个engine。一般情况下默认是40轮,但也不一定要等40轮才结束,例如,如果发现drc数目修不下来,route_detail便会提前退出。
route_group,对指定的net进行绕线。可以将route_group理解为一个快速版本的route_auto,它对指定的net进行绕线,它也含有route_global、route_track以及route_detail这三步。因为只对指定的net绕线,所以速度很快。
比较常用的场景是,提前对一些timingcritical的net绕线,让这些net走直线。或者,给时钟树绕线。
route_eco,把做eco(timingorfunction)后断开的net(或新增加的net)做绕线并修drc。这个命令经常使用在修timing阶段,这是由于在进行eco后,绕线必然有断开,或有drc,或有新增加的net需要绕线。不管什么情况,统一用route_eco来处理。
route_eco实际上执行两个动作,分别为:连接新的/断开的net(调用route_global+route_track),和修drc(调用route_detail-incr),其中,在修drc时,可以只修econet的drc,也可以修全部net的drc。
一般情况下,虽然可以使用route_eco修drc,即route_eco的连接新的/断开的net没起作用,只是修drc起作用了,但是建议使用route_detail-incr修drc。
route_opt,优化时序(同时还优化面积,功耗,transition,hold等),并做ecorouting。具体地,route_opt可理解成三步:
1、postrouteoptimization,优化setup,面积,功耗,transition,hold等(size_cell和insert_buffer为主)
2、legalize_placement,经过第一步的折腾后,有很多的cell有overlap,或不在siterow上,需要legalizer把它们放在legallocation上。
3、route_eco,在完成postrouteoptimization和legalize_placement之后,绕线损失较大,需要调用route_eco。工具默认是5轮,也可以设成10或者更多,route_opt也可以跑多轮,以便得到更好的ppa。
进一步地,在本申请的实施例中,pnr工具基于库文件和设计数据进行布线处理时,在执行完优化时序命令之后,即完成route_opt之后,可以执行第一写出命令,然后写出pnr工具中当前的holdreport,netlist以及def,即获取第一报告、第一网表以及第一文件。
可以理解的是,在本申请的实施例中,后端设计工具在进入timingeco之前,可以在routing阶段加入校正流程,该校正流程用于对pnr工具与sta工具之间的不一致进行校正,以节省eco流程中的修正时间和迭代次数。
具体地,在本申请的实施例中,后端设计工具在routing阶段加入校正流程时,可以在完成route_opt之后,先写出当前的holdreport、netlist以及def,然后利用当前的holdreport、netlist以及def进行后续的校正处理。此时,原有的后端设计流程暂时中止但是不退出。
可以理解的是,在本申请中,def文件是关于设计(design)的描述,因此可以根据design需求从后端工具里写出def来。def文件里面的信息都是描述design的,具体可以包括pin脚信息,长度,高度,坐标定位,数字pr的面积大小等。
需要说明的是,在本申请的实施例中,pnr工具写出的第一报告中包括有holdslack。具体地,slack可以用来表示设计是否满足时序要求,可以分为setupslack和holdslack,如果slack的值为正,则表明设计可以满足setuptime或holdtime要求,反之则表明设计不满足setuptime或holdtime要求。
进一步地,在本申请的实施例中,若setupslack为正,表示datarequiredtime在dataarrivaltime之后,则一定满足setuptime。反之,则不满足setuptime;若holdslack为正,表示dataarrivaltime在datarequiredtime之后,则一定满足holdtime。反之,则不满足holdtime。
需要说明的是,在本申请的实施例中,pnr工具在执行校正流程时所写出的holdslack仅仅表征pnr工具在当前时刻的时序信息,并不完全是准确和真实的,因此在后续的处理流程中,需要对该第一报告中的holdslack进行修正。
步骤203、基于第一网表和第一文件,sta工具执行第一分析命令,生成第二报告。
在本申请的实施例中,pnr工具执行第一写出命令,获得第一报告、第一网表以及第一文件之后,基于第一网表和第一文件,sta工具可以执行第一分析命令,生成第二报告。
进一步地,在本申请的实施例中,pnr工具执行写出指令,将第一报告、第一网表以及第一文件写出之后,基于第一网表和第一文件,sta工具可以执行第一分析命令,然后生成第二报告。
需要说明的是,在本申请的实施例中,基于第一网表和第一文件,sta工具执行第一分析命令,生成第二报告的过程中,后端设计工具可以先基于第一网表和第一文件执行第一插入命令,对间隙进行插入处理;接着,后端设计工具可以执行第一抽取命令,提取第一寄生参数;最后,sta工具便可以执行第一分析命令,对第一寄生参数进行静态分析处理,进而生成第二报告。
也就说,在本申请中,基于第一网表和第一文件所得到的布局结果,sta工具可以按预估线长提取延迟数据作静态时序分析。
可以理解的是,在本申请中,后端设计工具在基于第一网表和第一文件执行第一插入命令时,主要是进行filler和dummy的插入处理。
具体地,在本申请中,filler是指stdcellfiller,是fill硅层,poly,以及底层电源轨道,主要目的是连通电源和阱区。进一步地,filler指的是标准单元库和i/opad库中定义的与逻辑无关的填充物,用来填充标准单元和标准单元之间,i/opad和i/opad之间的间隙,filler的插入(padfliier,cellfiller),主要是把扩散层连接起来,满足drc规则和设计需要。
具体地,在本申请中,dummy是指dummymetal,是fill上层金属的,主要目的是保证cmp的效果。进一步地,foundry厂都有对金属密度的规定,使其金属密度不要低于一定的值,以防在芯片制造过程中的刻蚀阶段对连线的金属层过度刻蚀从而降低电路的性能,而加入dummymetal就是为了增加金属的密度。
可以理解的是,在本申请中,后端设计工具在基于第一网表和第一文件执行第一抽取命令时,主要是为了提取寄生参数。其中,提取寄生参数的工具可以为synopsys的star-rcxt。
具体地,在本申请中,由于导线本身存在的电阻,相邻导线之间的互感,耦合电容在芯片内部会产生信号噪声,串扰和反射。这些效应会产生信号完整性问题,导致信号电压波动和变化,如果严重就会导致信号失真错误。为了解决这一问题,后端设计工具可以提取寄生参数进行再次的分析验证。
进一步地,在本申请的实施例中,sta工具执行第一分析命令,对提取到的第一寄生参数进行分析所生成第二报告中,也包括有holdslack。而于第一报告中的、pnr工具的holdslack相比,sta工具对应的该holdslack为准确且真实的,因此应该参照sta工具获得第二报告中的holdslack。
步骤204、基于第一报告和第二报告,对pnr工具的信息进行修正,获得修正后信息。
在本申请的实施例中,sta工具执行第一分析命令,生成第二报告之后,可以根据第一报告和第二报告,然后对pnr工具的信息进行修正,可以获得修正后信息。
需要说明的是,在本申请的实施例中,后端设计工具在基于第一报告和第二报告,对pnr工具的信息进行修正,获得修正后信息时,可以先根据第一报告中的holdslack和第二报告中的holdslack确定余量差值;然后,按照余量差值对pnr工具的信息进行修正处理。
进一步地,在本申请的实施例中,pnr工具写出的第一报告中的holdslack不完全是准确和真实的,相比之下,sta工具获得第二报告中的holdslack可以认为是准确且真实的,因此,可以先利用第一报告中的holdslack和第二报告中的holdslack进行余量差值的确定,即对两个holdslack进行差值运算,获得差值结果。
可以理解的是,在本申请的实施例中,在根据第一报告中的holdslack和第二报告中的holdslack确定余量差值之后,后端设计工具便可以按照余量差值对pnr工具的信息进行修正处理。
具体地,在本申请的实施例中,后端设计工具在,按照余量差值对pnr工具的信息进行修正处理时,可以将计算获得的余量差值反标至pnr工具,从而可以完成pnr工具的信息的修正处理。
需要说明的是,在本申请的实施例中,在校正流程的执行过程中,pnr工具写出获得第一报告,sta工具获得第二报告,虽然第二报告中的holdslack可以认为是正确且真实的,但是由于pnr工具无法之直接获得第二报告中的holdslack,因此pnr工具并不能直接利用第二报告中的holdslack对自身的时序信息进行修正。
进一步地,在本申请的实施例中,在完成对pnr工具的信息的修正之后,如上述步骤202至步骤204所提出的校正流程便执行结束,在该校正流程中,后端设计工具利用第一报告和第二报告直接完成了对pnr工具的信息的修正,从而可以在后续的eco流程中不再需要为了修正pnr工具的信息进行不断的迭代,进而节省了eco流程的时间和功耗。
步骤205、基于库文件和设计数据,sta工具执行第二分析命令,获得时序报告。
在本申请的实施例中,在根据第一报告和第二报告,然后对pnr工具的信息进行修正,获得修正后信息之后,sta工具可以基于库文件和设计数据,继续执行第二分析命令,获得时序报告。
可以理解的是,在本申请的实施例中,在校正流程便执行结束之后,后端设计工具可以继续执行被中止的后端设计流程,具体地,sta工具可以继续执行第二分析命令,进一步获得时序分析结果,即时序报告。
需要说明的是,在本申请的实施例中,由于布线已经完成,因此在此时提取出来的延迟数据真实性是比较高的,进而在此基础上进行的再优化应该能够有效地去除任何setup和hold冲突(violation)。
进一步地,在本申请的实施例中,基于库文件和设计数据获得了一个完整的布局结果,如果没有拥塞(congestion)问题,sta工具就可以按预估线长提取延迟数据作静态时序分析,以完成基于库文件和设计数据所设计的电路的时序路径的分析处理,输出时序报告。
可以理解的是,在本申请的实施例中,基于库文件和设计数据,sta工具执行第二分析命令的具体流程可以包括:后端设计工具首先基于库文件和设计数据执行第二插入命令,对间隙进行插入处理;接着,后端设计工具可以执行第二抽取命令,提取第二寄生参数;最后,sta工具执行第二分析命令,对第二寄生参数进行静态分析处理,便可以生成时序报告。
步骤206、若时序报告存在时序违规,则执行变更命令,对pnr工具的、修正后信息以外的其他信息进行eco处理。
在本申请的实施例中,基于库文件和设计数据,sta工具在执行第二分析命令,获得时序报告之后,如果时序报告中存在时序违规,那么便需要执行变更命令,对pnr工具的、修正后信息以外的其他信息进行工程变更。
进一步地,在本申请的实施例中,在sta工具完成时序分析获得时序报告之后,可以根据时序报告确定当前的设计结果是否存在时序违规,如果存在时序违规,那么后端设计工具便需要进行eco处理。
与常见的方案不同的是,本申请所提出的eco方法,不再需要对pnr工具的信息进行修正,获得修正后信息,只需要对其以外的其他信息进行修正,从而能够精确的fixhold,并且流程简单易于实现,对降低项目timing收敛,按时tapeout有非常重要的帮助。
可以理解的是,在本申请中,正是由于在芯片routing阶段,后端设计工具中止后端设计流程中的布线处理不退出,同时插入校正流程,并通过校正流程完成了pnr工具的信息的修正处理,从而可以在后续的eco流程时,不再需要对pnr工具的信息进行eco处理,大大减少了迭代的轮数。
一般情况下,后端设计工具在cts之后便可以开始修复hold,按照芯片后端设计流程的执行过程,各个阶段可能出现的hold违反的修正可以使用synopsys的pnr工具icc。
示例性的,在本申请中,对于cts之后且布线之前所出现的hold违反,可以使用>psynopt-only_hold_time来进行修复,其中,psynopt命令有两种功能,一个是执行增量时序驱动的逻辑优化;另一个是legalizesplacement。
示例性的,在本申请中,对于布线阶段所出现的hold违反,可以使用ccd来修复:
>set_concurrent_clock_and_data_strategy;
>route_opt-concurrent_clock_and_data;
还可以通过指定布线优化选项来修复:
>route_opt-incr-only_hold_time。
示例性的,在本申请中,对于chipfinish阶段出现的hold违反,可以使用ccd来修复:
>focal_opt-concurrent_clock_and_data\
-hold_endpointsall
还可以让软件自动对所有holdendpoints来修复:
>focal_opt-hold_endpointsall\
-efforthigh
也可以指定reg2reg路径进行修复,如果违规都集中在reg2reg的路径上,那么使用:
>focal_opt-hold_endpointsall\
-register_to_register
如果在某个具体阶段,用命令进行自动修复的方法无法将violation修复,且违反的值很大的话,就需要手动插入buffer或者delaycell来解决了,即采用eco的方法来手工解决。在插入之前要确保没有插入corefiller,或者有filler的话要remove。
其中,插入的buffer是随便放置的,可能和其他cell重合了,或者没有放置在row上面,因此需要将其摆放在合理的位置上。插入的buffer是没有连线的,需要用eco来对其连线。
如果不用手工eco的方法,也可以将整个设计的网表、spef导入pt,让pt自己修复,然后导出eco的脚本,然后将脚本导入icc进行修复。
需要说明的是,hold的修复不用做到每一个阶段都是clean的,比如说,对于比较老的0.18um工艺,cts之后有0.1ns左右的wns违反还是允许的,毕竟后边还有布线的操作,线延迟也是有益于hold的;布线之后存在非常少量,且量级在0.01左右的违反也是允许的,可以通过focal_opt来解决。
具体地,在本申请中,eco是指所变更(包括增加和删除)单元(cell)的总数少于10%的情况,太大的变更建议从头再来一遍。如果不想变更时钟树,则要求eco没有触发器的增减和位置的挪动,但是可以允许变更现有触发器的大小(sizeup/down),如果时钟树尚未布线。而一般的逻辑组合单元(cell)则可以作任何的修改。布局变更(placementeco)和静态时序分析和再优化(sta&opt)可以多次循环,直到没有大的冲突(violation)为止。
相比之下,布线变更(routingeco)所受到的限制比布局变更(placementeco)更多,不能有任何触发器的修改,只能变更逻辑组合单元(cell)。任何与时钟树相连单元(cell)的变更都会导致时钟树连线的变化,为了尽可能地减少对时序的影响,建议用手工做时钟树的修改。布线变更(routingeco)可以循环多次,直到所有setup和holdviolation去除为止。
步骤207、sta工具继续执行下一个分析命令,直到获得的时序报告不存在时序违规,输出版图。
在本申请的实施例中,在完成对pnr工具的、修正后信息以外的其他信息进行工程变更之后,sta工具可以继续执行下一个分析命令,直到获得的时序报告不存在时序违规为止,从而可以结束芯片的后端设计流程,输出版图。
也就是说,在本申请的实施例中,在完成一次eco修复之后,后端设计工具便可以迭代至下一轮继续进行时序分析。具体地,sta工具继续执行下一个分析命令,并获得下一个时序报告,如果下一个时序报告仍然存在时序违反,那么便继续进行eco处理,直到获得的时序报告不存在时序违规为止,此时便可以输出版图。
需要说明的是,在本申请的实施例中,后端设计工具是按照gdsii格式输出版图的。也就是说,版图以gdsii的文件格式交给foundry厂(在晶圆硅片上做出实际的电路,再进行封装和测试,就得到了实际的芯片。
由此可见,对于芯片后端设计流程而言,输入的数据包括门级网表、库文件、时序约束,经过后端设计工具的设计和eco修复,最终输出的是gdsii格式的版图。
综上所述,通过上述步骤201至步骤207所提出的芯片后端设计方法,后端设计工具在routing阶段通过校正pnr工具跟sta工具之间的相关性,基本可以达到在pnr阶段holdviolationclean,大大减少timingfix的迭代次数,降低了timingfix的风险。另外由于pnr工具跟sta工具之间的相关性的较正,避免了fixhold误插入大量的delaycell,从而有效降低动了态功耗。也就是说,在本申请中,后端设计工具在芯片routing阶段中止后端设计流程中的布线处理不退出,同时插入校正流程,以对pnr工具跟sta工具之间的相关性进行校正,能够精确的fixhold,并且流程简单易于实现,对降低项目timing收敛,按时tapeout有非常重要的帮助。
本申请实施例提供了一种芯片后端设计方法,后端设计工具导入库文件和设计数据;其中,设计数据包括芯片前端设计后获得的门级网表和时序约束;布线pnr工具基于库文件和设计数据进行布线处理时,在执行完优化时序命令之后,执行第一写出命令,获得第一报告、第一网表以及第一文件;基于第一网表和第一文件,静态时序分析sta工具执行第一分析命令,生成第二报告;基于第一报告和第二报告,对pnr工具的信息进行修正,获得修正后信息;基于库文件和设计数据,sta工具执行第二分析命令,获得时序报告;若时序报告存在时序违规,则执行变更命令,对pnr工具的、修正后信息以外的其他信息进行eco处理;sta工具继续执行下一个分析命令,直到获得的时序报告不存在时序违规,输出版图。也就是说,在本申请中,在routing阶段,插入一个校正流程,根据pnr工具获得的第一报告和sta工具获得的第二报告进行精确的修正处理,以对pnr工具和sta工具的相关性进行校正,从而可以解决由于pnr工具和sta工具的不一致所造成的eco流程中迭代次数增多的问题,能够大大减少eco流程的迭代次数,进而缩短芯片后端设计的时间,有效提高芯片设计效率。
基于上述实施例,在本申请的再一实施例中,图4为芯片后端设计方法的实现流程示意图二,如图4所示,在本申请的实施例中,基于库文件和设计数据,sta工具执行第二分析命令,获得时序报告之后,即步骤205之后,芯片后端设计方法还可以包括以下步骤:
步骤208、若时序报告不存在时序违规,则输出版图。
在本申请的实施例中,基于库文件和设计数据,sta工具在执行第二分析命令,获得时序报告之后,如果时序报告中不存在时序违规,那么便不需要执行变更命令,可以直接输出版图。
进一步地,在本申请的实施例中,图5为芯片后端设计方法的实现流程示意图三,如图5所示,在本申请的实施例中,pnr工具基于库文件和设计数据进行布线处理时,在执行完优化时序命令之后,执行第一写出命令,获得第一报告、第一网表以及第一文件之前,即步骤202之前,芯片后端设计方法还可以包括以下步骤:
步骤209、基于库文件和设计数据,pnr工具执行布局命令,进行布局处理。
步骤2010、基于库文件和设计数据,pnr工具执行生成命令,生成时钟树。
在本申请的实施例中,在导入库文件和设计数据之后,可以先执行布局命令,基于库文件和设计数据进行布局处理,接着可以执行生成命令,基于库文件和设计数据生成时钟树。
需要说明的是,在本申请的实施例中,布局主要指的是如何合理地放置标准单元(standardcell),一般情况下,并不希望软件过多地移动已经放好的兆单元(megacell)。布局可以简单地根据cell的连接进行,也可以根据时序要求来做,还可以以拥塞程度(congestion)为主进行。
示例性的,在本申请中,布局工具可以选择synopsys的astro。
随着芯片速度的提高,越来越多的方案首先选择按时序要求来布局,这时便需要用到时序约束(timingconstrain)。在布局开始之前,有可以先做一些分组(group)或分区(region),其好处是可以告诉布局软件一个大致的摆放范围,但是这种作法会同所给的时序要求发生矛盾,特别是对边界的连接单元(cell)。所以建议在定义分组(group)或分区(region)时,尽量宽松一些,并允许一定百分比的单元(cell)放在分组(group)或分区(region)之外,这样做的结果同所谓的变形虫(amoeba)布局有同样的效果。
如果使用有时序要求的布局,而布局用的时序引擎(timingengine)与布线或计算延迟用的引擎(engine)不一样,则要注意引擎(engine)之间的计算误差,它们有时会有10倍之差。
需要说明的是,在本申请的实施例中,时钟树综合cts就是时钟的布线。由于时钟信号在数字芯片的全局指挥作用,它的分布应该是对称式的连到各个寄存器单元,从而使时钟从同一个时钟源到达各个寄存器时,时钟延迟差异最小,因此,时钟信号需要单独布线。
示例性的,在本申请中,cts工具可以选择synopsysphysicalcompiler。
进一步地,在本申请的实施例中,在大规模集成电路中,大部分时序元件的数据传输是由时钟同步控制的时钟频率决定了数据处理和传输的速度,时钟频率是电路性能的最主要的标志。在集成电路进入深亚微米阶段,决定时钟频率的主要因素有两个,一是组合逻辑部分的最长电路延时,二是同步元件内的时钟偏斜(clockskew),随着晶体管尺寸的减小,组合逻辑电路的开关速度不断提高,时钟偏斜成为影响电路性能的制约因素。时钟树综合的主要目的是减小时钟偏斜。
以一个时钟域为例,一个时钟源点(source)最终要扇出到很多寄存器的时钟端(sink),从时钟源扇出很大,负载很大,时钟源是无法驱动后面如此之多的负载的。这样就需要一个时钟树结构,通过一级一级的buffer去驱动最终的叶子结点(寄存器)。
具体地,时钟树(clocktree)和缓冲器树(buffertree)相比,二者的区别是缓冲器树(buffertree)一般只考虑驱动能力而不在乎树的延迟和扭曲(skew)等问题,它主要用于复位(reset),扫描使能(scanenable)等无时序要求的连线。
需要说明的是,在本申请中,树的根结点、时钟周期、树的最大延迟、树的最小延迟、扭曲(skew)、传递时间(transitiontime)和缓冲器的种类等几项是做时钟树时常见的必要指标。还有一些可选项:特别要作叶子的结点(leafpin)、特别不要作叶子的结点(excludedpin)和特别需要保留在时钟树里的单元(cell)保护单元(preservedcell)等。
在本申请的实施例中,进一步地,在导入库文件和设计数据之后,还可以进行i/o单元布置(i/oplace)、兆单元布置(megacellplace)、行通道生成(rowgeneration)以及电源布线(powerrouting)。
具体地,在本申请中,后端设计工具在进行进行i/o单元布置时,需要考虑内部各模块的位置、电源pad的个数和种类。不同种类的信号pad需要不同种类的电源,有些相同电压的电源也是不能共用的,特别是模拟信号及其电源本身都需要与其它信号隔离,电源pad的个数计算要兼顾芯片封装的最低要求和芯片内部的功耗。
具体地,在本申请中,adc、dac、pll、memory这类部件属于兆单元或称巨集(megacell),所有的后端eda布局软件都有自动放置兆单元(megacell)的功能。一般情况下,在有五个以上兆单元(megacell)的设计中都选择手工放置兆单元(megacell)。排放前需要先了解运算数据的流向、各大模块间的关系和位置,依此来决定兆单元(megacell)的大体位置。
进一步地,在本申请中,在逐一放置各个兆单元(megacell)时,要考虑其引脚(pin)的位置、方向、数量及相互间的对应关系,因为兆单元(megacell)常常会禁止几层金属布线层的使用,所以要注意给穿过它的信号线留有足够的空间,特别是兆单元(megacell)之间的距离。
如果兆单元(megacell)本身没有电源环(powerring),则要在它四周留下更大的空间以备加环。环的宽度由厂商提供的公式,依速度、数据变化率求得。有些软件可以将相邻的几个兆单元(megacell)合在一起做个环以节省空间,此时公共环的宽度应该是各个单独环宽度中最大者。常见的布局规划(floorplan)方法是兆单元(megacell)放在四周,标准单元(standardcell)放在中间。留给标准单元(standardcell)的空间形状以方形最佳。
具体地,在本申请中,行通道(row)是用于放置标准单元(standardcell)的,其整体形状已经被兆单元(megacell)的位置大致决定,行通道(row)和兆单元(megacell)之间要留有一定的空间,以利于兆单元(megacell)的信号连线。可以在兆单元(megacell)之间做少许行通道(row),以备连线过长,加缓冲器接力,或生成时钟树时使用。
具体地,在本申请中,电源布线时依各个模块的功耗不同,布线密度也不相同。在完成电源布线之后,可以检验整体的供电情况。在传统的通过四周管脚供电、标准单元(standardcell)放在中央的设计中,标准单元(standardcell)集中的row的四周可以加一圈电源环。
本申请实施例提供了一种芯片后端设计方法,后端设计工具导入库文件和设计数据;其中,设计数据包括芯片前端设计后获得的门级网表和时序约束;布线pnr工具基于库文件和设计数据进行布线处理时,在执行完优化时序命令之后,执行第一写出命令,获得第一报告、第一网表以及第一文件;基于第一网表和第一文件,静态时序分析sta工具执行第一分析命令,生成第二报告;基于第一报告和第二报告,对pnr工具的信息进行修正,获得修正后信息;基于库文件和设计数据,sta工具执行第二分析命令,获得时序报告;若时序报告存在时序违规,则执行变更命令,对pnr工具的、修正后信息以外的其他信息进行eco处理;sta工具继续执行下一个分析命令,直到获得的时序报告不存在时序违规,输出版图。也就是说,在本申请中,在routing阶段,插入一个校正流程,根据pnr工具获得的第一报告和sta工具获得的第二报告进行精确的修正处理,以对pnr工具和sta工具的相关性进行校正,从而可以解决由于pnr工具和sta工具的不一致所造成的eco流程中迭代次数增多的问题,能够大大减少eco流程的迭代次数,进而缩短芯片后端设计的时间,有效提高芯片设计效率。
基于上述实施例,在本申请的又一实施例中,在本申请的实施例中,导入库文件和设计数据之前,即步骤201之前,芯片后端设计方法还可以包括以下步骤:
步骤2011、执行第一启动命令,启动后端设计流程。
在本申请的实施例中,后端设计工具在进行芯片后端设计开始之前,可以执行第一启动命令,启动后端设计流程。在芯片后端设计开始之后,后端设计工具先库文件和设计数据到入至本地存储空间中。
需要说明的是,在本申请的实施例中,步骤202可以包括:
步骤202a、pnr工具基于库文件和设计数据进行布线处理时,执行优化时序命令。
以及在步骤202a之后,即执行完优化时序命令之后,
步骤202b、pnr工具执行第一写出命令,获得第一报告、第一网表以及第一文件。
进一步地,在本申请的实施例中,pnr工具基于库文件和设计数据进行布线处理时,在执行完优化时序命令之后,即步骤202a之后,芯片后端设计方法还可以包括以下步骤:
步骤2012、执行第一停止命令,中止后端设计流程中的布线处理。
步骤2013、执行第二启动命令,启动校正流程,以通过校正流程对pnr工具的信息进行修正,获得修正后信息。
在本申请的实施例中,在routing阶段,即在后端设计流程中的布线处理中,后端设计工具可以执行第一停止命令,暂时中止后端设计流程中的布线处理,即暂停routing,此时并不退出芯片的后端设计流程。
进一步地,在本申请的实施例中,后端设计工具还可以执行第二启动命令,启动校正流程,从而可以通过校正流程对pnr工具的信息进行修正,获得修正后信息。
需要说明的是,在本申请中,校正流程可以用于对pnr工具和sta工具之间的相关性进行校正,以提高两者之间的一致性。
可以理解的是,在本申请的实施例中,后端设计工具既可以依次执行步骤2012和步骤2013的方法,也可以通知执行步骤2012和步骤2013的方法。
进一步地,在本申请的实施例中,基于第一报告和第二报告,对pnr工具的信息进行修正,获得修正后信息之后,即步骤204之后,芯片后端设计方法还可以包括以下步骤:
步骤2014、执行第三启动命令,继续进行后端设计流程,以完成芯片的后端设计,输出版图。
在本申请的实施例中,后端设计工具在根据第一报告和第二报告完成对pnr工具的信息的修正之后,便可以执行第三启动命令,继续进行后端设计流程,并经过多次迭代之后,完成芯片的后端设计,输出版图。
需要说明的是,在本申请的实施例中,在完成校正流程的执行之后,pnr工具的信息已经被修正,因此,后端设计工具在继续进行后端设计流程时,只需要对pnr工具的、修正后信息以外的其他信息进行修复,而不需要在针对pnr工具的信息进行迭代修复,从而大大减少了迭代次数,加速了tapeout,节省了功耗。
进一步地,在本申请的实施例中,图6为本申请提出的芯片的后端设计流程的示意图,如图6所示,与上述图2中的目前eco流程相比,本申请的后端设计工具在项目进入timingeco之前,在routing阶段加入校正流程。具体做法为:route_opt后,执行写出指令,写出当前的holdreport、netlist以及def(步骤108c)。此时,eco流程停住但是不退出,后台调用insertdummyfiller(步骤108d)、starrc(步骤108e)、sta流程(步骤108f),然后产生相应的staholdreport,并与pnr工具产生的holdreport进行对比,确定出holdslack的差值,接着,后端设计工具可以将holdslack的差值反标到当前pnr中,实现fixhold(步骤108g),完成校正流程后,继续执行步骤106。
由此可见,在本申请中,后端设计工具在routing阶段通过校正pnr工具跟sta工具之间的相关性,基本可以达到在pnr阶段holdviolationclean,大大减少timingfix的迭代次数,降低了timingfix的风险。另外由于pnr工具跟sta工具之间的相关性的较正,避免了fixhold误插入大量的delaycell,从而有效降低动了态功耗。也就是说,在本申请中,后端设计工具在芯片routing阶段中止后端设计流程中的布线处理不退出,同时插入校正流程,以对pnr工具跟sta工具之间的相关性进行校正,能够精确的fixhold,并且流程简单易于实现,对降低项目timing收敛,按时tapeout有非常重要的帮助。
本申请实施例提供了一种芯片后端设计方法,后端设计工具导入库文件和设计数据;其中,设计数据包括芯片前端设计后获得的门级网表和时序约束;布线pnr工具基于库文件和设计数据进行布线处理时,在执行完优化时序命令之后,执行第一写出命令,获得第一报告、第一网表以及第一文件;基于第一网表和第一文件,静态时序分析sta工具执行第一分析命令,生成第二报告;基于第一报告和第二报告,对pnr工具的信息进行修正,获得修正后信息;基于库文件和设计数据,sta工具执行第二分析命令,获得时序报告;若时序报告存在时序违规,则执行变更命令,对pnr工具的、修正后信息以外的其他信息进行eco处理;sta工具继续执行下一个分析命令,直到获得的时序报告不存在时序违规,输出版图。也就是说,在本申请中,在routing阶段,插入一个校正流程,根据pnr工具获得的第一报告和sta工具获得的第二报告进行精确的修正处理,以对pnr工具和sta工具的相关性进行校正,从而可以解决由于pnr工具和sta工具的不一致所造成的eco流程中迭代次数增多的问题,能够大大减少eco流程的迭代次数,进而缩短芯片后端设计的时间,有效提高芯片设计效率。
本申请一实施例提供了一种版图设计方法,图7为版图设计方法的实现流程示意图,如图7所示,在本申请的实施例中,版图设计方法可以包括以下步骤:
步骤301、接收第四启动命令,启动版图设计流程,并解析第四启动命令中携带的库文件和设计数据;其中,设计数据包括芯片前端设计后获得的门级网表和时序约束。
步骤302、在基于库文件和设计数据,调用布线pnr工具进行版图设计流程中的布线处理时,若执行完优化时序命令,则生成第二停止命令和第二写出命令。
步骤303、响应第二停止命令,中止布线处理,同时响应第二写出命令,获取第三报告、第二网表以及第二文件。
步骤304、基于第二网表和第二文件,调用sta工具进行静态时序分析处理,生成第四报告。
步骤305、接收第五启动命令,启动校正流程,并基于第三报告和第四报告对pnr工具的信息进行修正,获得修正后信息。
步骤306、接收第六启动命令,基于修正后信息继续进行版图设计流程,输出版图。
在本申请的实施例中,前端设计已经完成之后,eda工具在进行版图设计时,可以先接收第四启动命令,启动版图设计流程,并解析第四启动命令中携带的库文件和设计数据。其中,导入库文件和设计数据也可以理解为版图设计流程的开始。
需要说明的是,在本申请的实施例中,eda工具在进行版图设计时可以先导入需要的数据。具体地,这些数据具体可以包括库文件和设计数据,其中,库文件可以为芯片代工厂(foundry厂)提供的标准单元、宏单元和i/opad的库文件,它包括物理库、时序库及网表库,分别以.lef、.tlf和.v的形式给出。而设计数据可以为芯片前端设计经过综合后生成的门级网表,具有时序约束和时钟定义的脚本文件和由此产生的.gcf约束文件。
进一步地,在本申请的实施例中,eda工具即为eda工具,可以包括不同供应商提供的多种工具,具体地,在执行不同的命令、进行不同类型的处理时,可以使用不同的eda工具。例如,常用的布局pnr工具有synopsys公司的iccompiler、astro和candance公司的soc-enconter。其中,iccompiler是synopsys公司继astro之后推出的另一款pnr工具,astro常用于10nm工艺一下超深亚微米级的布局布线。
在本申请的实施例中,在导入库文件和设计数据之后,eda工具调用pnr工具便可以基于库文件和设计数据进行布线处理,在布线处理的过程中,在执行完优化时序命令之后,eda工具可以生成第二停止命令和第二写出命令,进而可以响应第二停止命令,中止布线处理,同时可以响应第二写出命令,获得第三报告、第二网表以及第二文件。
示例性的,在本申请中,pnr工具可以为synopsys的astro。
需要说明的是,在本申请的实施例中,布线相关的route命令主要可以包括:route_auto、route_opt、route_eco、route_group、route_global、route_track、route_detail。
进一步地,在本申请的实施例中,pnr工具基于库文件和设计数据进行布线处理时,在执行完优化时序命令之后,即完成route_opt之后,可以执行第二写出命令,然后写出pnr工具中当前的holdreport,netlist以及def,即获取第三报告、第二网表以及第二文件。
具体地,在本申请的实施例中,eda工具在routing阶段加入校正流程时,可以在完成route_opt之后,先写出当前的holdreport、netlist以及def,然后利用当前的holdreport、netlist以及def进行后续的校正处理。此时,原有的版图设计流程暂时中止但是不退出。
进一步地,在本申请的实施例中,eda工具将第三报告、第二网表以及第二文件写出之后,可以基于第二网表和第二文件,调用sta工具进行静态时序分析处理,生成第四报告。
需要说明的是,在本申请的实施例中,eda工具可以接收第五启动命令,启动校正流程,然后可以基于第三报告和第四报告,对pnr工具的信息进行修正,获得修正后信息,具体地,eda工具可以先根据第三报告中的holdslack和第四报告中的holdslack确定余量差值;然后,按照余量差值对pnr工具的信息进行修正处理。
可以理解的是,在本申请的实施例中,在根据第三报告中的holdslack和第四报告中的holdslack确定余量差值之后,eda工具便可以按照余量差值对pnr工具的信息进行修正处理。
具体地,在本申请的实施例中,eda工具在,按照余量差值对pnr工具的信息进行修正处理时,可以将计算获得的余量差值反标至pnr工具,从而可以完成pnr工具的信息的修正处理。
进一步地,在本申请的实施例中,在完成对pnr工具的信息的修正之后,校正流程便执行结束,在该校正流程中,eda工具成了对pnr工具的信息的修正,从而可以在后续的eco流程中不再需要为了修正pnr工具的信息进行不断的迭代,进而节省了eco流程的时间和功耗。
可以理解的是,在本申请的实施例中,在校正流程便执行结束之后,eda工具可以接收第六启动命令,基于修正后信息继续进行版图设计流程,输出版图。
需要说明的是,在本申请的实施例中,eda工具是按照gdsii格式输出版图的。也就是说,版图以gdsii的文件格式交给foundry厂(在晶圆硅片上做出实际的电路,再进行封装和测试,就得到了实际的芯片。
由此可见,对于芯片版图设计流程而言,输入的数据包括门级网表、库文件、时序约束,经过eda工具的设计和eco修复,最终输出的是gdsii格式的版图。
具体地,在本申请中,在基于修正后信息继续进行版图设计流程,输出版图时,eda工具可以先基于库文件和设计数据,调用sta工具进行静态时序分析处理,获得时序报告;若时序报告存在时序违规,则执行变更命令,对pnr工具的、修正后信息以外的其他信息进行eco处理;接着,eda工具可以继续调用sta工具进行静态时序分析处理,直到获得的时序报告不存在时序违规,输出版图。
综上所述,通过上述步骤301至步骤306所提出的版图设计方法,eda工具在routing阶段通过校正pnr工具跟sta工具之间的相关性,基本可以达到在pnr阶段holdviolationclean,大大减少timingfix的迭代次数,降低了timingfix的风险。另外由于pnr工具跟sta工具之间的相关性的较正,避免了fixhold误插入大量的delaycell,从而有效降低动了态功耗。也就是说,在本申请中,eda工具在芯片routing阶段中止版图设计流程中的布线处理不退出,同时插入校正流程,以对pnr工具跟sta工具之间的相关性进行校正,能够精确的fixhold,并且流程简单易于实现,对降低项目timing收敛,按时tapeout有非常重要的帮助。
本申请实施例提供了一种版图设计方法,eda工具接收第四启动命令,启动版图设计流程,并解析第四启动命令中携带的库文件和设计数据;其中,设计数据包括芯片前端设计后获得的门级网表和时序约束;在基于库文件和设计数据,调用布线pnr工具进行版图设计流程中的布线处理时,若执行完优化时序命令,则生成第二停止命令和第二写出命令;响应第二停止命令,中止布线处理,同时响应第二写出命令,获取第三报告、第二网表以及第二文件;基于第二网表和第二文件,调用sta工具进行静态时序分析处理,生成第四报告;接收第五启动命令,启动校正流程,并基于第三报告和第四报告对pnr工具的信息进行修正,获得修正后信息;接收第六启动命令,基于修正后信息继续进行版图设计流程,输出版图。也就是说,在本申请中,在routing阶段,插入一个校正流程,根据pnr工具获得的第一报告和sta工具获得的第二报告进行精确的修正处理,以对pnr工具和sta工具的相关性进行校正,从而可以解决由于pnr工具和sta工具的不一致所造成的eco流程中迭代次数增多的问题,能够大大减少eco流程的迭代次数,进而缩短版图设计的时间,有效提高版图设计效率。
基于上述实施例,在本申请的另一实施例中,图8为后端设计工具的组成结构示意图一,如图8所示,本申请实施例提出的后端设计工具10可以包括:导入单元11,第一获取单元12,第一生成单元13,第一修正单元14,变更单元15,第一输出单元16,
所述导入单元11,用于导入库文件和设计数据;其中,所述设计数据包括芯片前端设计后获得的门级网表和时序约束;
所述第一获取单元12,用于布线pnr工具基于所述库文件和所述设计数据进行布线处理时,在执行完优化时序命令之后,执行第一写出命令,获得第一报告、第一网表以及第一文件;
所述第一生成单元13,用于基于所述第一网表和所述第一文件,静态时序分析sta工具执行第一分析命令,生成第二报告;
所述第一修正单元14,用于基于所述第一报告和所述第二报告,对所述pnr工具的信息进行修正,获得修正后信息;
所述第一获取单元12,还用于基于所述库文件和所述设计数据,所述sta工具执行第二分析命令,获得时序报告;
所述变更单元15,用于若所述时序报告存在时序违规,则执行变更命令,对所述pnr工具的、所述修正后信息以外的其他信息进行eco处理;
所述第一获取单元12,还用于所述sta工具继续执行下一个分析命令,直到获得的时序报告不存在时序违规;
所述第一输出单元16,用于输出版图。
在本申请的实施例中,进一步地,图9为后端设计工具的组成结构示意图二,如图9示,本申请实施例提出的后端设计工具10还可以包括第一处理器17、存储有第一处理器17可执行指令的第一存储器18,进一步地,后端设计工具10还可以包括第一通信接口19,和用于连接第一处理器17、第一存储器18以及第一通信接口19的第一总线110。
在本申请的实施例中,上述第一处理器17可以为特定用途集成电路(applicationspecificintegratedcircuit,asic)、数字信号处理器(digitalsignalprocessor,dsp)、数字信号处理装置(digitalsignalprocessingdevice,dspd)、可编程逻辑装置(programmablelogicdevice,pld)、现场可编程门阵列(fieldprogrammablegatearray,fpga)、中央处理器(centralprocessingunit,cpu)、控制器、微控制器、微处理器中的至少一种。可以理解地,对于不同的设备,用于实现上述处理器功能的电子器件还可以为其它,本申请实施例不作具体限定。后端设计工具10还可以包括第一存储器18,该第一存储器18可以与第一处理器17连接,其中,第一存储器18用于存储可执行程序代码,该程序代码包括计算机操作指令,第一存储器18可能包含高速ram存储器,也可能还包括非易失性存储器,例如,至少两个磁盘存储器。
在本申请的实施例中,第一总线110用于连接第一通信接口19、第一处理器17以及第一存储器18以及这些器件之间的相互通信。
在本申请的实施例中,第一存储器18,用于存储指令和数据。
进一步地,在本申请的实施例中,上述第一处理器17,用于导入库文件和设计数据;其中,所述设计数据包括芯片前端设计后获得的门级网表和时序约束;布线pnr工具基于所述库文件和所述设计数据进行布线处理时,在执行完优化时序命令之后,执行第一写出命令,获得第一报告、第一网表以及第一文件;基于所述第一网表和所述第一文件,静态时序分析sta工具执行第一分析命令,生成第二报告;基于所述第一报告和所述第二报告,对所述pnr工具的信息进行修正,获得修正后信息;基于所述库文件和所述设计数据,所述sta工具执行第二分析命令,获得时序报告;若所述时序报告存在时序违规,则执行变更命令,对所述pnr工具的、所述修正后信息以外的其他信息进行eco处理;所述sta工具继续执行下一个分析命令,直到获得的时序报告不存在时序违规,输出版图。
在实际应用中,上述第一存储器18可以是易失性存储器(volatilememory),例如随机存取存储器(random-accessmemory,ram);或者非易失性存储器(non-volatilememory),例如只读存储器(read-onlymemory,rom),快闪存储器(flashmemory),硬盘(harddiskdrive,hdd)或固态硬盘(solid-statedrive,ssd);或者上述种类的存储器的组合,并向第一处理器17提供指令和数据。
另外,在本实施例中的各功能模块可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用软件功能模块的形式实现。
集成的单元如果以软件功能模块的形式实现并非作为独立的产品进行销售或使用时,可以存储在一个计算机可读取存储介质中,基于这样的理解,本实施例的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的全部或部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)或processor(处理器)执行本实施例方法的全部或部分步骤。而前述的存储介质包括:u盘、移动硬盘、只读存储器(readonlymemory,rom)、随机存取存储器(randomaccessmemory,ram)、磁碟或者光盘等各种可以存储程序代码的介质。
本申请实施例提供了一种后端设计工具,该后端设计工具在routing阶段,插入一个校正流程,根据pnr工具获得的第一报告和sta工具获得的第二报告进行精确的修正处理,以对pnr工具和sta工具的相关性进行校正,从而可以解决由于pnr工具和sta工具的不一致所造成的eco流程中迭代次数增多的问题,能够大大减少eco流程的迭代次数,进而缩短芯片后端设计的时间,有效提高芯片设计效率。
基于上述实施例,在本申请的另一实施例中,图10为eda工具的组成结构示意图一,如图10所示,本申请实施例提出的eda工具20可以包括:接收单元21,解析单元22,调用单元23,第二生成单元24,中止单元25,第二获取单元26,第二修正单元27,第二输出单元28,
所述接收单元21,用于接收第四启动命令,启动版图设计流程;
所述解析单元22,用于解析所述第四启动命令中携带的库文件和设计数据;其中,所述设计数据包括芯片前端设计后获得的门级网表和时序约束;
所述调用单元23,用于在基于所述库文件和所述设计数据,调用布线pnr工具进行所述版图设计流程中的布线处理时;
所述第二生成单元24,用于若执行完优化时序命令,则生成第二停止命令和第二写出命令;
所述中止单元25,用于响应所述第二停止命令,中止所述布线处理;
所述第二获取单元26,用于响应所述第二写出命令,获取第三报告、第二网表以及第二文件;
所述调用单元23,还用于基于所述第二网表和所述第二文件,调用sta工具进行静态时序分析处理,生成第四报告;
所述接收单元21,还用于接收第五启动命令,启动校正流程;
所述第二修正单元27,用于基于所述第三报告和所述第四报告对所述pnr工具的信息进行修正,获得修正后信息;
所述接收单元21,还用于接收第六启动命令;
所述第二输出单元28,用于基于所述修正后信息继续进行所述版图设计流程,输出版图。
进一步地,在本申请的实施例中,所述第二输出单元28,具体用于基于所述库文件和所述设计数据,调用所述sta工具进行静态时序分析处理,获得时序报告;若所述时序报告存在时序违规,则执行变更命令,对所述pnr工具的、所述修正后信息以外的其他信息进行eco处理;继续调用所述sta工具进行静态时序分析处理,直到获得的时序报告不存在时序违规,输出所述版图。
进一步地,在本申请的实施例中,所述第二修正单元27,具体用于根据所述第三报告中的holdslack和第四报告中的holdslack确定余量差值;按照所述余量差值对所述pnr工具的信息进行修正处理。
在本申请的实施例中,进一步地,图11为eda工具的组成结构示意图二,如图11示,本申请实施例提出的版图设计工具20还可以包括第二处理器29、存储有第二处理器29可执行指令的第二存储器210,进一步地,eda工具20还可以包括第二通信接口211,和用于连接第二处理器29、第二存储器210以及第二通信接口211的第二总线212。
本申请实施例提供了一种后端设计工具,该eda工具在routing阶段,插入一个校正流程,根据pnr工具获得的第一报告和sta工具获得的第二报告进行精确的修正处理,以对pnr工具和sta工具的相关性进行校正,从而可以解决由于pnr工具和sta工具的不一致所造成的eco流程中迭代次数增多的问题,能够大大减少eco流程的迭代次数,进而缩短版图设计的时间,有效提高版图设计效率。
本申请实施例提供一种计算机可读存储介质,其上存储有程序,该程序被处理器执行时实现如上所述的芯片后端设计方法。
具体来讲,本实施例中的一种芯片后端设计方法对应的程序指令可以被存储在光盘,硬盘,u盘等存储介质上,当存储介质中的与一种芯片后端设计方法对应的程序指令被一电子设备读取或被执行时,包括如下步骤:
导入库文件和设计数据;其中,所述设计数据包括芯片前端设计后获得的门级网表和时序约束;
布线pnr工具基于所述库文件和所述设计数据进行布线处理时,在执行完优化时序命令之后,执行第一写出命令,获得第一报告、第一网表以及第一文件;
基于所述第一网表和所述第一文件,静态时序分析sta工具执行第一分析命令,生成第二报告;
基于所述第一报告和所述第二报告,对所述pnr工具的信息进行修正,获得修正后信息;
基于所述库文件和所述设计数据,所述sta工具执行第二分析命令,获得时序报告;
若所述时序报告存在时序违规,则执行变更命令,对所述pnr工具的、所述修正后信息以外的其他信息进行eco处理;
所述sta工具继续执行下一个分析命令,直到获得的时序报告不存在时序违规,输出版图。
具体来讲,本实施例中的一种版图设计方法对应的程序指令可以被存储在光盘,硬盘,u盘等存储介质上,当存储介质中的与一种版图设计方法对应的程序指令被一电子设备读取或被执行时,包括如下步骤:
接收第四启动命令,启动版图设计流程,并解析所述第四启动命令中携带的库文件和设计数据;其中,所述设计数据包括芯片前端设计后获得的门级网表和时序约束;
在基于所述库文件和所述设计数据,调用布线pnr工具进行所述版图设计流程中的布线处理时,若执行完优化时序命令,则生成第二停止命令和第二写出命令;
响应所述第二停止命令,中止所述布线处理,同时响应所述第二写出命令,获取第三报告、第二网表以及第二文件;
基于所述第二网表和所述第二文件,调用sta工具进行静态时序分析处理,生成第四报告;
接收第五启动命令,启动校正流程,并基于所述第三报告和所述第四报告对所述pnr工具的信息进行修正,获得修正后信息;
接收第六启动命令,基于所述修正后信息继续进行所述版图设计流程,输出版图。
本申请实施例提供一种芯片,芯片包括可编程逻辑电路和/或程序指令,当芯片运行时实现如上所述的芯片后端设计方法,具体包括如下步骤:
导入库文件和设计数据;其中,所述设计数据包括芯片前端设计后获得的门级网表和时序约束;
布线pnr工具基于所述库文件和所述设计数据进行布线处理时,在执行完优化时序命令之后,执行第一写出命令,获得第一报告、第一网表以及第一文件;
基于所述第一网表和所述第一文件,静态时序分析sta工具执行第一分析命令,生成第二报告;
基于所述第一报告和所述第二报告,对所述pnr工具的信息进行修正,获得修正后信息;
基于所述库文件和所述设计数据,所述sta工具执行第二分析命令,获得时序报告;
若所述时序报告存在时序违规,则执行变更命令,对所述pnr工具的、所述修正后信息以外的其他信息进行eco处理;
所述sta工具继续执行下一个分析命令,直到获得的时序报告不存在时序违规,输出版图。
本申请实施例提供一种芯片,芯片包括可编程逻辑电路和/或程序指令,当芯片运行时实现如上所述的版图设计方法,具体包括如下步骤:
接收第四启动命令,启动版图设计流程,并解析所述第四启动命令中携带的库文件和设计数据;其中,所述设计数据包括芯片前端设计后获得的门级网表和时序约束;
在基于所述库文件和所述设计数据,调用布线pnr工具进行所述版图设计流程中的布线处理时,若执行完优化时序命令,则生成第二停止命令和第二写出命令;
响应所述第二停止命令,中止所述布线处理,同时响应所述第二写出命令,获取第三报告、第二网表以及第二文件;
基于所述第二网表和所述第二文件,调用sta工具进行静态时序分析处理,生成第四报告;
接收第五启动命令,启动校正流程,并基于所述第三报告和所述第四报告对所述pnr工具的信息进行修正,获得修正后信息;
接收第六启动命令,基于所述修正后信息继续进行所述版图设计流程,输出版图。
本领域内的技术人员应明白,本申请的实施例可提供为方法、系统、或计算机程序产品。因此,本申请可采用硬件实施例、软件实施例、或结合软件和硬件方面的实施例的形式。而且,本申请可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器和光学存储器等)上实施的计算机程序产品的形式。
本申请是参照根据本申请实施例的方法、设备(系统)、和计算机程序产品的实现流程示意图和/或方框图来描述的。应理解可由计算机程序指令实现流程示意图和/或方框图中的每一流程和/或方框、以及实现流程示意图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在实现流程示意图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在实现流程示意图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在实现流程示意图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
以上所述,仅为本申请的较佳实施例而已,并非用于限定本申请的保护范围。
- 一种芯片布局方法、装置、存储...
- 形成边界单元的方法、集成电路...
- 一种汽车线束模块化的电路拆分...
- 使用模拟软件产生电路布局的方...
- 基于遗传算法的模拟电路故障参...
- 一种电热耦合模型建立方法与流...
- 用于实现模拟器的方法、装置、...
- 基于FPGA实现目标跟踪算法...
- SRAM型FPGA故障检测中...
- 一种生成面向超导RSFQ电路...
- 还没有人留言评论。精彩留言会获得点赞!
- 机器视觉装置及其嵌入式系统和测量方法与流程
- 一种移植嵌入式系统并在SD卡启动的方法与流程
- 一种嵌入式播报系统壳体的制作方法与工艺
- 一种嵌入式系统的文件存储方法和装置与流程
- 一种嵌入式系统自动升级方法与流程
- 一种嵌入式的高度测量系统的制作方法与工艺
- 引导程序升级方法、嵌入式设备、控制设备及嵌入式系统与流程
- 具有自恢复功能的嵌入式系统以及自恢复方法与流程
- 一种嵌入式系统切换启动设备的制作方法与工艺
- 铂金嵌入式双循环净化系统的制作方法与工艺
- 一种亚微米多层金属电极的制作方法
- 一种高效高压垂直通孔键合式led芯片的制作方法
- 一种高效高压电极侧壁化键合式led芯片的制作方法
- 一种高效高压电极侧壁化键合式led芯片及其制作方法
- 一种高效高压垂直通孔键合式led芯片及其制作方法
- 包含应力调节覆盖层的互连结构及其制造方法
- 一种钨栓塞的制备方法
- 具有增强的接点可靠性的半导体封装及其制造方法
- 适用于纳米级工艺的抗辐射sram芯片后端物理设计方法
- 一种跨电压域数据传输方法、电压域子系统和电子设备的制作方法
- 集成电路的设计方法及装置与制造工艺
- 一种高速差分驱动电路的版图结构的制作方法
- 一种集成电路版图图形的修改方法
- 版图设计方法以及版图设计单元集合的制作方法
- 一种用于校准模拟集成电路的装置的制造方法
- 减小集成电路的版图面积的方法
- 减小集成电路的版图面积的方法
- 高效率模拟电路版图设计流程方法
- 基于边表示短路关键面积网络的集成电路版图优化方法
- 一种平板显示版图设计规则检查结果自动筛选方法
- 患者接口系统的制作方法
- 一种通用的信息系统接口测试方法及装置的制造方法
- 一种支持swp接口大容量usim的应用系统及其使用方法
- 接口防护装置及其系统的制作方法
- 信息接口和具有信息接口的驱动系统的制作方法
- 患者接口系统的制作方法
- 用于换能器接口的系统和方法
- 一种大气压接口的离子源系统以及质谱仪的制作方法
- 一种节能型路灯智能控制系统的制作方法
- 业务指令的传输方法及装置的制作方法