一种融合触发词识别特征的实体关系抽取方法与流程
本发明涉及一种融合触发词识别特征的实体关系抽取方法,属于自然语言处理中的信息抽取技术领域。
背景技术:
实体关系抽取任务是给定标注了两个实体的句子,返回两个实体之间的语义关系。例如“姚明在父亲姚志源的影响下,他也十分热爱篮球运动”,句子中两个实体分别是“姚明”和“姚志源”,两个实体之间的关系是“父子”。
实体关系抽取是信息检索和问答系统等信息系统的重要支撑技术。实体关系抽取使信息系统的输出结果由粗粒度的文档级转变为细粒度的实体级。比如在传统的信息检索技术中,输入“姚明的父亲是谁?”,会输出结果是带有“姚明”和“父亲”词条的所有文档;将实体关系抽取技术应用到信息检索后,会直接输出结果是“姚志源”。
现有的实体关系抽取方法,对输入的标注了两个实体的句子直接建模提取用于实体关系分类的特征并将提取的特征输入到实体关系分类器中;但是这些方法对句子中的所有词一视同仁,因此,句子中对实体关系分类贡献小的词会引入噪声,比如上面例句中“他也十分热爱篮球”对实体关系分类贡献就小,但是将其建模并提取其特征输入到实体关系分类器中,就会对实体关系分类产生负面影响;为了解决现有实体关系抽取方法对句子中所有词一视同仁带来的噪声问题,我们启发式的假设句子中对实体关系抽取贡献大的词为“触发词”,即触发词是句子中能够直接或间接表达两个实体间关系的词或词组,比如上面例句中“父亲”就是触发词。提出了一种识别句子中触发词的方法。
将识别句子中触发词的方法与实体关系抽取方法融合,即我们提出一种融合触发词识别特征的实体关系抽取方法。先对数据集中句子标注触发词,用于训练一个能识别句子中触发词的模型。然后将识别触发词的模型与实体关系抽取模型融合用于实体关系抽取;我们的方法显著的提高了实体关系抽取的性能。
技术实现要素:
本发明的目的在于针对现有的实体关系抽取方法对句子中的所有词一视同仁而带来的噪声问题,提出了一种融合触发词识别特征的实体关系抽取方法。
所述融合触发词识别特征的实体关系抽取方法,包括识别句子中触发词和实体关系抽取,具体包括以下步骤:
1.一种融合触发词识别特征的实体关系抽取方法,包括识别句子中触发词和实体关系抽取,具体包括以下步骤:
步骤1:提取句子中触发词的特征;
步骤1.1:对数据集中的句子标注触发词,输出标注触发词后的数据集;
其中,数据集包括训练集和测试集;
步骤1.1具体包括以下子步骤:
步骤1.1.1:对数据集中含有触发词的句子,使用大括号标注触发词,用于记录触发词在句子中的位置;
步骤1.1.2:对于数据集中不含有触发词的句子,打上<omit>标记;
步骤1.2:从步骤1.1输出的数据集的训练集中选取一个训练样本(sh,lh),对句子sh进行分类再计算该句子的标签向量v;
其中,sh和lh分别表示训练集中第h个样本中的句子和句子对应的实体关系类型标签,h的取值范围是1到h,h是训练集中样本的总数;
步骤1.2具有包括以下子步骤:
步骤1.2.1:对句子sh进行分类;根据句子sh中两个实体之间的相对位置,通过公式(1)得到句子类型t:
其中,
步骤1.2.2:通过公式(2)得到句子sh的标签向量v:
其中,用x是句子sh去掉标注触发词的大括号和<omit>标签后的句子,形式上为文字的序列,即x=[x1,x2,...,xm],xi表示x中第i个文字,i的取值范围为1到m,m是句子x的长度;one_hot(·)是嵌入函数,实体xi对应的vi为1,其他字xj对应的vj为0,触发词在句子x中的位置i对应的vi为1;t是经步骤2.1计算输出的句子类型;符号
步骤1.3:计算带有实体位置信息的字向量,具体为:将句子x中的字转化为字向量,计算实体在句子x中的相对位置,将实体相对位置转换为位置向量,最后计算带有实体位置信息的字向量,具体包括以下子步骤:
步骤1.3.1:对句子x中的每个字通过公式(3)的嵌入函数转化为其字向量:
ei=embed(xi)(3)
其中,embed(·)是嵌入函数,对于输入的每一个字xi,查找得到对应的字向量ei;
步骤1.3.2:通过公式(4)计算实体k相对于句子x中第i个字的相对位置
其中,
步骤1.3.3:并通过公式(5)的嵌入函数将实体k相对于句子x中第i个字的相对位置
其中,
步骤1.3.4:通过公式(6)将经步骤1.3.1转化输出的句子x中第i个字的字向量ei与经步骤1.3.3转化输出的实体k相对于句子x第i个字的位置向量
步骤1.4:将经步骤1.3.4拼接得到的字向量
步骤1.5:计算实体的向量表示并根据该向量表示计算句子x的句子类型的向量表示;
步骤1.5具体包括以下子步骤:
步骤1.5.1:通过公式(7)从经步骤1.4输出的高阶特征向量e*中计算实体k的向量表示entity_embk:
其中,k取值为1和2,分别代表一个句子x中的实体1和实体2,
步骤1.5.2:通过公式(8)计算句子x的句子类型的向量表示te:
te=relu(wt(concat(entityembk))+b)(8)
其中,
步骤1.6:通过公式(9),拼接经步骤1.4输出的高阶特征向量e*和经步骤1.5.2输出的句子类型向量表示te得到特征向量
其中,concat(·)函数表示两个向量的拼接,
步骤1.7:使用注意力机制捕捉句子中触发词的特征;通过公式(10)对经步骤1.6输出的向量e#使用注意力机制计算得到其权重向量α:
α=softmax(wttanh(e#))(10)
其中,tanh(·)是双曲正切函数,
步骤2:提取句子中用于实体关系抽取的特征;
步骤2的具体子步骤如下:
步骤2.1:通过公式(11)将经步骤1.6输出的字级别向量e#与经步骤1.7输出的权重向量α的转置做运算,输出句子级别的向量e∷:
e∷=e#αt(11)
其中,
步骤2.2:对经步骤2.1输出的句子级别的向量e∷通过公式(12)映射到实体关系空间并得到用于实体关系分类的向量o;
o=we∷+b(12)
其中,
步骤3:融合识别句子中触发词的模型与实体关系抽取的模型;
步骤3.1:采用相对熵衡量经步骤1.2.2输出的句子标签向量v与经步骤1.7输出的权重向量α之间的分布差异性;具体为:计算句子标签向量的概率分布,计算该概率分布与经步骤1.7输出的权重向量之间的相对熵;
步骤3.1的具体子步骤如下:
步骤3.1.1:通过公式(13)计算句子标签向量v的概率分布αv:
αv=softmax(v)(13)
其中,v经过softmax(·)函数将值映射到(0,1)区间;
步骤3.1.2:通过公式(14)计算经步骤3.1.1输出的概率分布αv与经步骤1.7输出的权重向量α之间的相对熵作为识别句子中触发词的模型的目标函数;
其中,h表示总的训练样本数,h表示第h个训练样本,其中θ是模型中可被训练的参数;
步骤3.2:采用交叉熵衡量真实概率与实体关系类型预测概率的之间分布的差异性;具体为:计算实体关系类型的预测概率,计算该概率与真实概率概率之间的相对熵;
其中,真实概率是指句子对应实体关系标签lh的概率为1;
步骤3.2.1:通过公式(15)对经步骤2.2输出的用于实体关系分类的向量o计算得到实体关系类型的预测概率p(lh|sh):
p(lh|sh)=softmax(o)(15)
其中,sh和lh分别表示训练集中第h个样本中的句子和句子对应的实体关系类型标签;
步骤3.2.2:通过公式(16)计算真实概率与经步骤3.2.1输出的每种实体关系类型的预测概率p(lh|sh)之间的交叉熵作为实体关系抽取模型的目标函数:
其中,h表示训练样本的总数,h表示第h个训练样本,θ是模型中可被训练的参数;
步骤3.3:将经步骤3.1.2计算的交叉熵j(θ)与经步骤3.2.2计算的相对熵d(αv||α,θ)相加得到融合识别句子中触发词的模型与实体关系抽取的模型的目标函数j*(θ),如下公式(17)所示:
j*(θ)=j(θ)+d(αv||α,θ)(17)
步骤3.4:使用随机梯度下降方法对步骤3.3的目标函数进行优化,对训练集中的所有训练样本进行n次迭代训练,输出被训练好的融合触发词识别特征的实体关系抽取模型;
步骤4:使用步骤3.4输出的实体关系抽取模型识别句子中两个实体之间的关系;任意输入一句标注好两个实体的句子到被训练好的关系抽取模型,输出两个实体间的语义关系。
有益效果
本发明是一种融合触发词识别特征的实体关系抽取方法,与现有实体关系抽取方法相比,具有如下有益效果:
1.所述方法解决了现有实体关系抽取方法对句子中的所有词一视同仁的缺点,提出一种识别句子中触发词的方法,用于帮助实体关系抽取模型能提取对实体关系分类更有用的特征;
2.所述方法将识别句子中触发词的方法与实体关系抽取的方法相融合,因此,将句子中触发词的特征用于实体关系抽取,提高了实体关系抽取任务的性能;在标准的中文实体关系抽取数据集ace2005上,所述方法的f1得分比之前模型最高的f1得分提升了2.5个百分点;
附图说明
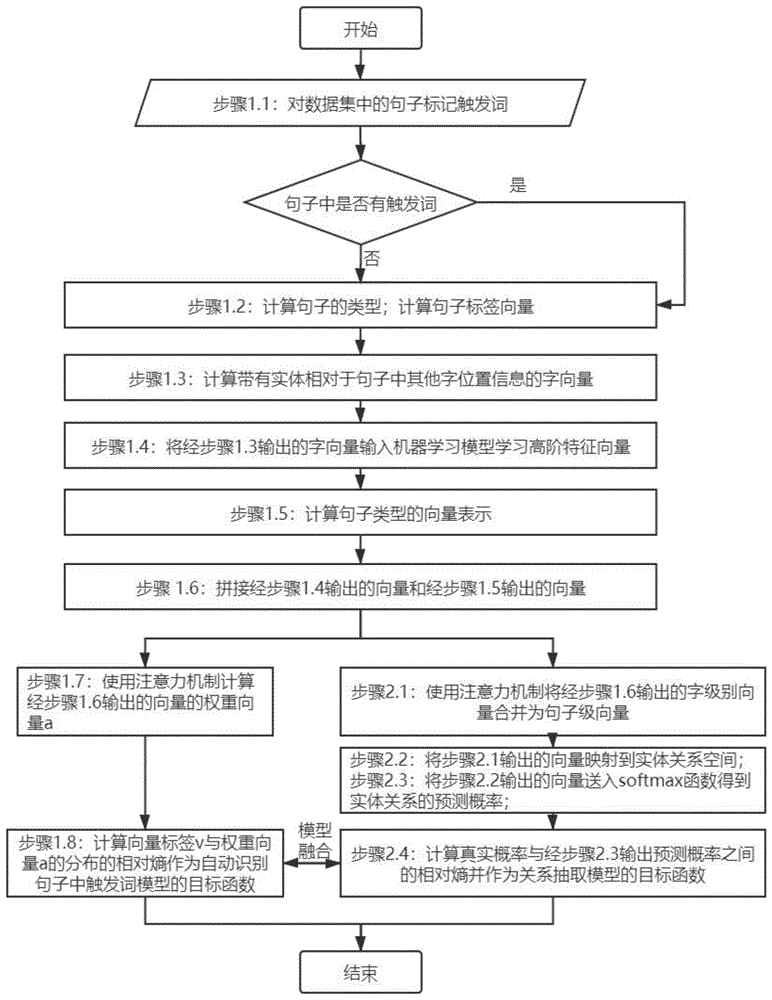
图1是本发明一种融合触发词识别特征的实体关系抽取方法的流程图。
具体实施方式
下面结合具体实施例1以及附图1对本发明一种融合触发词识别特征的实体关系抽取方法进行细致阐述。
实施例1
本实施例阐述了本发明所述的一种融合触发词识别特征的实体关系抽取方法中的具体实施。
图1所示,是所述方法的流程图。
步骤1.设计识别句子中触发词的模型;
步骤1.1对数据集中的句子标记触发词,对有触发词的句子,例如“在中国科学院自动化研究所里,有一个中法自动化与应用数学联合实验室”;这个句子的两个实体是“中国科学院自动化研究所”和“中法自动化与应用数学联合实验室”,表达的实体关系是“art/user-owner-inventor-manufacturer”。句子中的词“有”能够直接的表达实体关系,使用大括号将这个词标记为触发词,用于记录触发词在句子中的位置;对于不含有触发词的句子,在句子的结尾标记<omit>标签;
步骤1.2计算经过步骤1.1的数据集中句子的标签向量v;
步骤1.2具体包括以下子步骤:
步骤1.2.1先计算句子的类型;根据句子中两个实体的相对位置计算句子的类型t,计算句子的类型是为了考虑不含触发词的句子在哪些位置相对两个实体省略触发词;例如“在中国科学院自动化研究所里,有一个中法自动化与应用数学联合实验室”的句子类型为t=2;
步骤1.2.2计算句子标签向量v;对于不含有触发词的句子,句子的标签向量v由句子的类型和两个实体决定,例如“中国基督教协会会长”中,两个实体是“中国基督教协会会长”和“中国基督教协会”,表达的实体关系是“org-aff/employment”,句子的类型为t=1,句子的长度为m=9,假设数据集中句子的类型总数为n=3,则其标签向量v=[1,1,1,1,1,1,1,1,1,1,0,0]并且长度为m+n;对含有触发词的句子,句子的标签向量v由触发词、句子类型和两个实体决定,例如“在中国科学院自动化研究所里,有一个中法自动化与应用数学联合实验室”中,触发词是“有”,句子类型为t=2,句子长度m=32,触发词在句子中的位置为15,其标签向量v=[0,1,1,1,1,1,1,1,1,1,1,1,0,0,1,0,0,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,0,1,0]并且长度为m+n;
步骤1.3使用嵌入技术,将初始输入的自然语言句子中的每个字转化为其嵌入向量;计算实体相对于句子中其他字的相对位置信息并使用嵌入技术将位置信息转化为其嵌入向量;将字嵌入向量与位置嵌入向量拼接得到模型的输入向量e;例如初始输入的自然语言句子句子“姚明出生于上海”,两个实体分别是“姚明”和“上海”,触发词是“出生于”,实体关系是“出生地”,实体“姚明”相对于句子中其他字的位置信息是[0,0,1,2,3,4,5],通过实体相对于句子中其他字的位置信息指明是抽取句子中两个实体的位置;
步骤1.4将经步骤1.3输出的向量e输入到机器学习模型中,比如bilstm深度神经网络,学习得到高阶特征向量e*;
步骤1.5.计算句子类型的向量表示;
步骤1.5具体包括以下子步骤:
步骤1.5.1从经步骤1.4输出的高阶特征向量e*中得到实体k的向量
步骤1.5.2拼接步骤1.5.1输出的实体1的向量entity_emb1和实体2的向量entity_emb2得到向量
步骤1.6拼接经步骤1.4输出的高阶特征向量e*和经步骤1.5.2输出的向量te得到向量
步骤1.7采用注意力机制计算经步骤1.6输出的向量e#对应的权重向量α,用于捕捉句子中关于触发词的特征;
步骤1.8使用相对熵衡量经步骤1.2输出的向量标签与经步骤1.7输出的权重向量之间分布的差异性并作为识别触发词模型的目标函数;
步骤2.设计实体关系抽取模型;
步骤2.1使用注意力机制将将字级别的向量e#合并为句子级别的向量e∷;
步骤2.2将经步骤2.1输出的句子级别的向量e∷经过非线性变换映射到实体关系空间得到向量o;
步骤2.3将经步骤2.2输出的向量o输入softmax(·)函数得关系的预测概率p;
步骤2.4使用交叉熵衡量句子的真实概率与经步骤2.3计算得到的预测概率p之间分布差异性并作为实体关系抽取模型的目标函数;
步骤3.融合识别触发词模型和实体关系抽取模型;
步骤3.1将步骤2.3交叉熵和步骤1.7.2相对熵一起定义为优化目标函数,交叉熵越小表示关系预测的越准确。相对熵越小表示注意力机制学习到的触发词特征越准确;
步骤3.2使用随机梯度下降算法优化步骤3.1的目标函数,对训练集中的所有训练样本进行n次迭代训练;最终得到一个被训练好的融合触发词识别特征的实体关系抽取模型;
步骤4任意输入标注好两个实体的句子到经步骤3.2得到的被训练好的融合触发词识别特征的实体关系抽取模型中,将会输出这个句子中两个实体对应的实体关系;例如,输入句子“姚明在父亲姚志源的影响下,他也十分热爱篮球运动”,其中两个实体为“姚明”和“姚志源”,被训练好的实体关系抽取模型输出的实体关系是“父子”,将两个实体和实体关系构成三元组(“姚明”,“姚志源”,“父子”),在信息检索时,在搜索框内输入“姚明的爸爸是谁?”,查找对应的三元组直接输出“姚志源”的词条;与之前传统的信息检索的方法在所有文档中搜索“姚明”和“爸爸”词条相比,复杂性更低且速度更快;
以上所述为本发明的较佳实施例而已,本发明不应该局限于该实施例和附图所公开的内容。凡是不脱离本发明所公开的精神下完成的等效或修改,都落入本发明保护的范围。
- 一种事件抽取方法和装置与流程
- 同名人物的识别处理方法及处理...
- 一种面向军事语料的命名实体标...
- 命名实体的识别方法、识别系统...
- 命名实体识别方法及装置与流程
- 一种融合近义词信息用于自动问...
- 专名词典的词条过滤方法及装置...
- 一种自动抽取出资信息的方法、...
- 文本分词模型的训练方法、分词...
- 工作流审批处理方法、系统和计...
- 还没有人留言评论。精彩留言会获得点赞!
- 一种人物关系抽取方法和装置制造方法
- 藏语实体知识信息抽取方法
- 一种面向在线百科的实体属性抽取方法及系统的制作方法
- 一种基于在线百科链接实体的知识抽取方法
- 基于无监督的实体关系抽取的主题元搜索系统及方法
- 一种基于依存树的中文实体关系挖掘的控制装置的制作方法
- 一种中文实体间语义关系抽取方法
- 舆情事件的实体关系抽取方法和装置的制作方法
- 抽取关系型表格的方法和装置的制作方法
- 用于动力工具的碎屑抽取器的制作方法