一种基于关键词抽取和词移距离的知识产权匹配技术的制作方法
本发明涉及文本处理技术领域,具体为一种基于关键词抽取和词移距离的知识产权匹配技术。
背景技术:
专利文献作为知识的载体,为知识的分享、传播做出了巨大的贡献,个人、高校、企业不仅可以申请专利为知识产权收到法律的保护,避免剽窃或抄袭带来的损失,还可以通过搜索专利为个人或企业提供技术解决方案,或者专利可以为企业分析合作伙伴或竞争对手的技术发展提供参考,所以当企业或个人在互联网上搜索相关专利时,推荐相似度高的结果给用户至关重要;
目前对于专利文本的相似度计算主要包括人工文本分类,并人工标注关键词,用关键词来做集合操作或关键词向量化后计算文本的相似度,在关键词做集合操作时,无法人工标记权重,最终也无法对集合操作的结果进行排序,也可以通过多关键词向量化后,大多采用拼接向量的方式来表达文本的向量,最后通过计算相似度方法如:余弦相似度来计算向量之间的相似度,然后根据相似度计算的结果对专利文本进行排序,以上方法存在的问题包括:人工标注关键词不仅耗费资源,且搜索结果的权重无法给出,多关键词向量化没有考虑关键词在文本中的权重,以及可能存在的语义最相近的词之间的距离,基于以上缺点,专利文本加标题之间的相似度往往效果不是很好。
技术实现要素:
本发明提供一种基于关键词抽取和词移距离的知识产权匹配技术,可以有效解决上述背景技术中提出人工标注关键词不仅耗费资源,且搜索结果的权重无法给出,多关键词向量化没有考虑关键词在文本中的权重,以及可能存在的语义最相近的词之间的距离的问题。
为实现上述目的,本发明提供如下技术方案:一种基于关键词抽取和词移距离的知识产权匹配技术,包括专利文本中标记部分文本、专利标题和内容的关键词特征工程、lightgbm训练模型、通过关键词lightgbm模型抽取关键词和关键词权重,用wmd计算两个专利文本之间关键词和权重结合在一起的距离值,将距离值转化为相似度排序与推荐;
具体包含以下步骤:
s1、首先在专利文本中标记部分文本,标记专利文本的二元组可以表示为<t+c,k>;
s2、专利标题和内容的关键词特征工程:对文本分词,然后通过tf-idf值选取topk的词作为候选关键词,然后针对关键词做特征工程;
s3、lightgbm训练模型,提取训练数据的特征,然后根据前top-k的关键词是否在训练集中,打上标签0或1,最后用lightgbm训练候选关键词的特征,得到抽取关键词以及权重的lightgbm模型;
s4、用wmd计算文本相似度:用训练好的lightgbm抽取要比对的专利文本的标题加内容的关键词和权重,然后关键词用bert模型转化为词向量,用wmd将两篇专利的关键词向量和权重做计算,得到两篇文章的距离值;
s5、距离值转化为相似度排序与推荐:距离值越短表示文本越相似,所以距离值从小到大排序,取固定数量的结果做推荐。
优选的,所述步骤s1中t表示标题,c表示文本内容,k表示关键词,t+c表示标题插入到文本的第一句,标记数据作为训练集,标记数量越多,训练模型越精确。
优选的,所述步骤s2中分词主要用到结巴分词库,tf-idf用来做词频和文档逆词频统计,通过tf-idf值的排序得到前k的关键词。
优选的,所述步骤s3中lightgbm为一种传统机器学习的决策树算法;
其中特征工程中的特征包括:词性、是否出现在标题、是否在文章第一句话、是否在文章最后一句话、tf值、最早出现位置、textrank值,关机词所在位置,ske共现矩阵偏度。
优选的,所述步骤s1中中文bert模型为bert-as-service模型,无需训练,直接加载,bert已经在多个中文库做过预训练,较其它模型的优势是可以做句子级向量。
优选的,所述步骤s4中wmd是一种计算句子之间距离的方法,距离越小,相似度越高,通过计算词之间的移动距离来得到文档的距离。
与现有技术相比,本发明的有益效果:本发明结构科学合理,使用安全方便,目的在于企业园区内企业通过特定高校来检索企业所需的潜在专利,为企业的发展寻找技术支持,基于专利标题和内容的匹配方法首先提取专利和标题拼接成文本之后,用训练好的模型抽取关键词并得到关键词在文本中的权重,当计算专利的文本相似度时,将抽取的关键词和权重和另一篇专利的关键词和权重放在wmd(wordmover’sdistance)中计算两篇文章的相似度,相似度以两篇文章的距离值作为参考,距离值越近表示越相似,最后设定阈值将小于阈值的值排序,最后将排序的距离对应的专利推荐给搜索用户。
附图说明
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。
在附图中:
图1是专利文本标题加摘要的相似度计算流程图;
图2是wmd计算不同文本之间的权重的关键词和权重;
图3是lightgbm模型训练流程图;
图4是结合用户使用的专利相似度计算实施流程图。
具体实施方式
以下结合附图对本发明的优选实施例进行说明,应当理解,此处所描述的优选实施例仅用于说明和解释本发明,并不用于限定本发明。
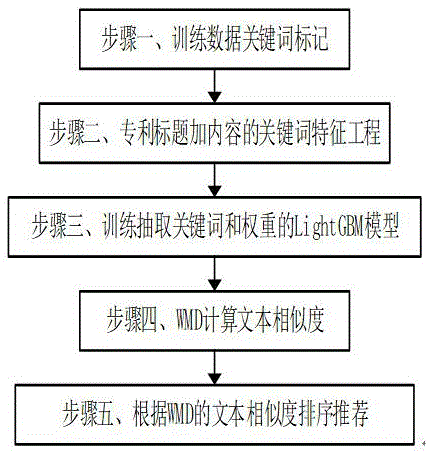
实施例:如图1所示,本发明提供技术方案,一种基于关键词抽取和词移距离的知识产权匹配技术,
步骤一、关键词训练数据标记:准备训练集,即人工标注专利的关键词数据;
人工标注数据三元组表示<t,c,k>,其中t表示专利的标题,c表示专利文本的内容,k表示专利的关键词。
步骤二、对文本做分词处理和提取候选关键词:将结巴分词将标题和文本作为整体文本分词,然后用tf计算每个词的词频,然后选取tf值较大的前m个作为专利文本的候选关键词,其中对于在某一文档dj里的词语ti来说,ti的词频可表示为:
其中ni,j是词语ti在文档dj中的出现次数,分母则是在文件dj中所有词语的出现次数之和;
步骤三、专利标题加内容的关键词特征工程:特征工程主要从数据分析和经验得到,研究主题是候选关键词在文档中的属性;
判定候选关键词是否是文档真实关键词的特征包括:是否出现在标题,tf值,是否出现在标题,是否出现在正文第一句,是否出现在正文最后一句,是否包含数字,是否包含英文,共现矩阵偏度,词性等。
步骤四、训练抽取关键词的lightgbm模型:从训练样本的候选关键词中统计步骤三中每一个关键词的特征信息,判断该候选关键词是否在训练集标注的关键词组里面,若在词组内,该关键词标记为1,若不在则标记为0;
将每条关键词的特征和标签输入lightgbm模型训练,最终得到抽取关键词的lightgbm模型。
lightgbm是基于xgboost上改进而来,xgboost是基于gbdt即梯度提升树的,其基本思想是运用分类回归树(cart)进行集成学习。xgboost是基于预排序的方法,即所有特征按照特征的数值进行排序,消耗了内存,在遍历分割点时,分裂增益计算花费时间;
lightgbm采用基于梯度的单边采样来减少样本的维度,并采用直方图(histogram)算法将互斥特征合并降低特征的维度,降低寻找决策树最佳分割点的时间。
步骤五、在用户输入专利时,从数据库中读取该专利的标题和内容,然后用结巴和tf值来提取候选关键词,最后通过特征工程抽取关键词特征,用训练好的lightgbm模型对关键词特征进行预测,最后得到预测特征值的分数,通过分数排序,得到前n的关键词为预测关键词,该关键词的预测分数作为关键词的权重。
步骤六、wmd计算文本相似度:wmd加载专利关键词和权重(k1,w1),(k2,w2)来计算两篇文章的距离值,距离越近表示越相似,wmd的描述如下:
权重w的计算公式:
其中ci表示词i在文本中出现的次数,j表示文档中第j个词,n表示词典的大小。
第i个词和第j个词的距离表示为:
m(i,j)=||xi-xj||2;
假设有一个预训练的bert模型的词向量矩阵为x∈rd×n,n表示词典大小,d表示词向量维度,xi表示单词向量化。
最终可累计求和得到两个文档之间的表达式:
约束:
其中wi,wj分别表示各个词在两个文档的权重向量,即文档特征。
步骤七、在测试集上统计相似度值在不同数据标签上的分布,在相似与不相似的分布的交点设置为阀值d,最终将大于阀值d的专利呈现给用户。
如图3-4所示的本发明的方法流程图:
步骤一、获取用户输入的标题和文本;
步骤二、建立专利标题、内容、关键词和权重库,首先查询专利和文本库,用关键词抽取的lightgbm抽取关键词,并将关键词关联到专利文本;
步骤三、对文本做分词处理和提取关键词,在一对多遍历计算专利文本相似度时,首先从数据库查询要匹配的专利标题和文本;
步骤四、将抽取得到的专利关键词和权重加载到wmd做计算,每一对计算的关键词和权重可以表示为(k1,w1),(k2,w2);
步骤五、通过一对n个专利的模式,计算n次wmd((k1,w1),(k2,w2))得到距离值得到距离值列表(d1,d2,d3...dn;
步骤六、在测试集上统计相似度值在不同数据标签上的分布,在相似与不相似的分布的交点设置为阀值d,最终将大于阀值d的前每个专利呈现给用户。
最后应说明的是:以上所述仅为本发明的优选实例而已,并不用于限制本发明,尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 基于文本匹配的智能面试方法、...
- 文字块排序方法、装置、存储介...
- 个人电子名片生成方法、装置、...
- 一种基于结算模型的售电合同生...
- 信息处理方法、装置、终端设备...
- 一种自定义生成报表的方法及装...
- 一种表单生成方法和系统与流程
- 消息发送方法、系统、计算机设...
- 一种对图像型PDF财务数据关...
- 基于知识库的报表生成方法及系...
- 还没有人留言评论。精彩留言会获得点赞!