一种基于深度学习的实体关系抽取方法与流程
本发明涉及实体对关系抽取,特别是涉及一种基于深度学习的实体关系抽取方法。
背景技术:
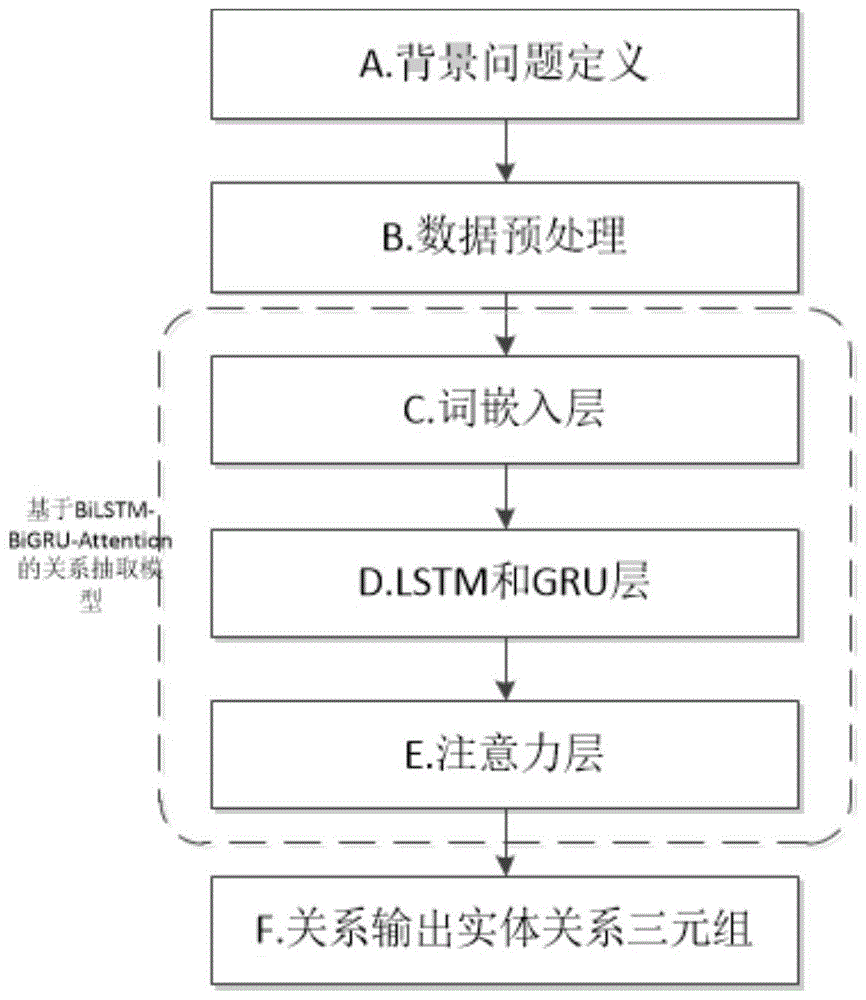
:现有平台内数据和信息不够丰富,无法很好地对企业进行综合监管与服务,因此亟需互联网大数据及相关技术来支持和加强对企业的综合监管与服务。随着互联网的快速发展,互联网上与企业相关的数据规模不断扩大,因此从海量的企业大数据中抽取关键信息有助于监管部门更好的对企业动态进行掌握。技术实现要素:本发明的目的是:。为了达到上述目的,本发明的技术方案是提供了一种基于深度学习的实体关系抽取方法,其特征在于,包括以下步骤:步骤1、问题背景定义,包括以下步骤:步骤101、获取企业的公开信息数据;步骤102、对关系抽取问题进行定义,准备相应词典,对于企业与企业及人与企业的关系描述,定义n种关系;步骤2、数据预处理,包括以下步骤:对通过步骤101获得的非结构化的公开信息数据进行分句,并根据步骤102预定义的n种关系使用word2vec中的skip-gram模型对分句后的数据进行预训练;步骤3、将通过步骤2得到的词表示成向量,转化为数值型便于后续步骤中模型的处理;步骤4、利用双向lstm模型和gru模型训练步骤3处理后得到的数值型词向量数据,以获取更多的上下文信息,提高关系抽取的准确性;步骤5、引入字节别和句级别的注意力机制,对重要特征添加更多的关注,降低不重要特征对关系抽取的影响;步骤6、利用步骤3、4、5得到(实体,实体,关系)三元组。优选地,所述步骤101中,使用爬虫获取企业在网络上公开的公开信息数据。由于采用了上述的技术方案,本发明与现有技术相比,具有以下的优点和积极效果:本发明利用基于lstm模型、gru模型和注意力机制提出了上市公司公告的关系抽取模型。双向lstm和gru模型结构更简单,能减少相关参数的训练,提高模型训练的效率。注意力机制的引入提高了句子整体特征的关系抽取准确率,使模型更注重句子中某些关键字特征。可在企业中进行推广和应用,具有较强的社会及商业价值。附图说明图1是本发明的整体流程图;图2是word2vec的skip-gram模型结构;图3是基于深度学习的实体关系抽取模型与方法结构图。具体实施方式下面结合具体实施例,进一步阐述本发明。应理解,这些实施例仅用于说明本发明而不用于限制本发明的范围。此外应理解,在阅读了本发明讲授的内容之后,本领域技术人员可以对本发明作各种改动或修改,这些等价形式同样落于本申请所附权利要求书所限定的范围。本发明的实施方式涉及一种基于深度学习的实体关系抽取方法,如图1所示,包括以下步骤:a.问题背景定义;b.数据预处理;c.词嵌入层;d.lstm和gru层;e.注意力层;f.关系输出实体关系三元组。本发明所涉及的模型如图3所示,其中,步骤a具体包括:图3是本发明所使用的的关系抽取模型图,从下到上分为词嵌入层(输入层),双向lstm和双向gru层,注意力层,最上面是输出层。词嵌入层给定一个句子s,假设该句子由t个词组成,s={w1,w2,w3,…,wt},每个词wi都对应着一个词向量。lstm是一种特殊的rnn结构,为了解决其梯度消失问题,引用gru结构。gru模型使用门控机制(分别是更新门和重置门),通过向量决定什么样的信息可以更新和通过。ht表示当前时刻下最终需要保存的记忆信息。hi表示第i个词对应的bigru和bilstm的输出。a1.通过使用爬虫获取上市公司公告信息;a2.对关系抽取问题进行定义,准备相应词典,对于企业与企业及人与企业的关系描述,定义12种关系,包括未知关系“unknown”,如下表1所示:关系id关系类型可出现此关系的实体对类型0unknown<企业,企业>、<人,企业>1合作<企业,企业>2收购<企业,企业>3变更<企业,企业>4子公司<企业,企业>5参股<企业,企业>、<人,企业>6退股<企业,企业>、<人,企业>7增持<企业,企业>、<人,企业>8减持<企业,企业>、<人,企业>9董事<人,企业>10总经理<人,企业>11其他高管<人,企业>表1:预定义的12种关系步骤b具体包括:对非结构化的公告数据进行分句、根据步骤(a2)预定义的关系使用word2vec中的skip-gram模型对数据进行预训练。skip-gram模型通过当前词来预测上下文词。模型的输入是由one-bot编码的词向量组成,隐藏层是由线性单元组成,没有激活函数,输出层使用了softmax函数。在训练过程中,需要选取滑窗大小,也就是上下文词的个数。假设在一个窗口中当前词是wt,需要预测的上下文词是wt-k,wt-k+1,……,wt-1+k,wt+k,这些上下文词属于语境cw。skip-gram模型基于当前词来计算上下文词ci的条件概率p(wt+i|wt),条件概率最后由softmax函数得到,计算公式如下:对于句子s,假设句子s由词语w1,w2,w3,…,wt组成,通过模型计算当前句子s成句概率,公式如下:最后skip-gram训练目标就是最大化成句概率p(s)。步骤c具体包括:将词表示成向量,转化为数值型便于模型处理。步骤d具体包括:利用双向lstm和gru模型训练步骤c处理的数据,以获取更多的上下文信息,提高关系抽取的准确性。步骤e具体包括:引入字节别和句级别的注意力机制,针对数据语料面向的特定情境,设立特定的重要程度。对重要特征添加更多的关注,降低不重要特征对关系抽取的影响。步骤f具体报告:执行步骤c、d、e从输入的数据中得到关系实体三元组(实体,实体,关系)。不难发现,本发明利用基于lstm模型、gru模型和注意力机制提出了上市公司公告的关系抽取模型。双向lstm和gru模型结构更简单,能减少相关参数的训练,提高模型训练的效率。注意力机制的引入提高了句子整体特征的关系抽取准确率,使模型更注重句子中某些关键字特征。可在企业中进行推广和应用,具有较强的社会及商业价值。当前第1页12
完整全部详细技术资料下载
当前第1页 1 2
相关技术
- 一种基于全局和局部注意力交互...
- 一种案例存储方法、装置、设备...
- 城市地铁站域的认知场所特征识...
- 一种消费数据地图呈现方法与流...
- 基于人工智能的兴趣点处理方法...
- 一种基于用户定位的快递配送方...
- 一种地图显示方法与系统与流程
- 基于微信的自然资源外业核查方...
- 一种以电子名片地图应用于营销...
- 一种电子名片地图筛选的方法、...
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1