一种基于深度学习模型和KNN实时校正的洪水预测方法与流程
本发明属于信息处理技术领域,特别涉及一种基于深度学习模型和knn实时校正的洪水预测方法。
背景技术:
我国国土辽阔,河流水资源众多,洪涝灾害频发,对我国经济发展、社会的进步带来了阻碍,因此开展水文预报研究十分重要。传统上大多使用基于物理过程的概念性水文模型描述水文过程,这类方法较为成熟,能够达到较好的预测效果。但是这些模型复杂,针对不同地区模型适应性较差,模型参数率定难度较大。因此基于数据驱动的水文过程预测方法日益得到发展。近年来,我国已经建立了较为完善的水文信息监测网络,采集了大量的水文数据,这些数据中蕴含了水文过程的内在规律,如何利用数据挖掘技术建立的基于数据驱动的预测模型,提高水文过程预测的准确率,是一种重要的研究方向。
技术实现要素:
发明目的:为了克服现有技术中存在的不足,本发明提供一种通过卷积神经网络自动提取数据特征的特点对训练数据进行建模,并通过加权k近邻误差校正模型进行校正以提高模型预测的准确率的基于深度学习模型和knn实时校正的洪水预测方法。
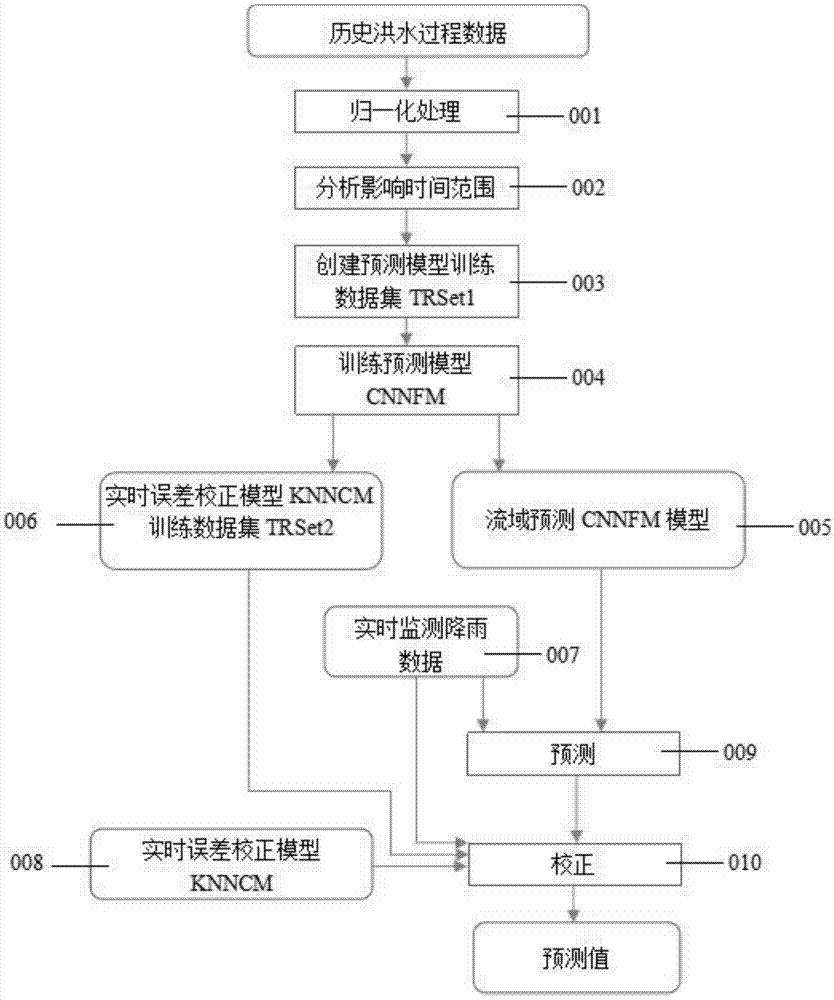
技术方案:为实现上述目的,本发明提供一种基于深度学习模型和knn实时校正的洪水预测方法,包括如下步骤:
(1)对历史洪水过程数据进行归一化处理;
(2)对归一化后的历史洪水过程数据序列进行分析,分析降雨量和蒸发量影响因素对流域出口流量的影响时间范围;
(3)利用滑动窗口从历史场次洪水数据中建立预测模型的输入和输出值,建立预测模型数据集trset1;
(4)建立基于深度学习的预测模型cnnfm,利用训练数据trset1训练预测模型获得模型参数;
(5)建立实时误差校正模型训练数据集trset2,输入与trset1相同,cnnfm模型的预测误差作为输出;
(6)建立基于加权k近邻的实时误差校正模型knncm;
(7)进行预测,利用模型cnnfm对实时数据进行预测,利用实时误差校正模型knncm结合训练数据trset2进行校正,获得最终的预测值。
进一步的,所述步骤(1)中对历史洪水过程数据进行归一化处理的具体步骤如下:
采用离差标准化即min-max标准化将洪水过程预测涉及到的降雨量、蒸发量、流量和水位数据进行线性变化,通过转化公式将原始值映射到[0,1]之间;转化公式如下:
其中x*为转换后的值,x为原始值,xmin=min(x),xmax=max(x);经过min-max标准化后,原始值被规约到[0,1]之间;其中,max(x)取x对应指标的历史最大值,min(x)取x对应指标的历史最小值。
进一步的,所述步骤(2)中分析降雨量和蒸发量影响因素对流域出口流量的影响时间范围;的具体步骤如下:
对归一化后的历史洪水过程数据序列采用皮尔逊相关系数分析输出量即流域出口流量与不同时间范围的各输入量即流域内各雨量站的降雨量和蒸发站的蒸发量的相关性,确定输入量对输出量影响的时间范围,各输入量的影响范围的最大值作为整体输入量对输出量影响的时间范围。
进一步的,所述步骤(3)中建立预测模型数据集trset1的具体步骤如下:
利用步骤(2)中得到的时间范围作为滑动窗口的宽度,按照步长为1提取历史洪水过程数据作为输入,对应输出为预见期的流量值;具体的输入量对流量影响的最大时间范围为w,即表示某个输入量的tk时刻监测值,从tk+1到tk+w时间内,逐渐影响输出量,并最终影响消失;
上式表示预测模型的输入为i的矩阵,p表示降雨量,q表示流量,有m+1个输入量,包括预测量自身,输出为o,预见期为n。
进一步的,所述步骤(4)中建立的基于深度学习的预测模型cnnfm,采用卷积神经网络构建,其中预测模型cnnfm包括卷积层、池化层和激活函数。
进一步的,所述步骤(5)中建立误差校正模型训练数据集trset2的具体步骤如下:
输入与步骤(3)中的预测模型数据集trset1输入相同,输出为预测模型cnnfm的预测误差,其中对输入为
其中,i表示输入,o表示输出。
进一步的,所述步骤(6)中建立基于加权k近邻的实时误差校正模型,具体步骤如下:
在训练数据集trset2中搜索预测输入的k近邻,采用距离加权对k近邻的误差求均值,将k近邻按照与预测输入i的欧式距离从小到大排序,第i近邻的权重如下:
最终的预测输出的校正误差
有益效果:本发明与现有技术相比具有以下优点:
本发明提出的基于深度学习模型和k近邻实时校正的洪水过程预测方法,从监测的降雨数据、流量数据等中利用数据挖掘发现数据之间的关系,相对传统的基于物理过程的预测过程来说,参数较少,同时更加容易设置相关参数。同时,在预测模型的基础上,通过校正模型,对预测值进行实时调整,提高了预测的准确率,提高了峰现时间和峰值预报准确率。
附图说明
图1是本发明的流程图;
图2是实施例中不同的时间差中di与q之间的关系图;
图3为具体实施例中屯溪流域报汛站网分布图;
图4为具体实施例中1997060608号洪水不同预见期预报情况图;
图5为具体实施例中2002051308号洪水1h预见期预报校正对比情况图;
图6为具体实施例中2002051308号洪水2h预见期预报校正对比情况图;
图7为具体实施例中20020513号洪水4h预见期预报校正对比情况图。
具体实施方式
下面结合附图对本发明作更进一步的说明。
本发明包括如下步骤:
(1)对历史洪水过程数据进行规格化。历史洪水过程数据中可能会存在缺失值,缺失的数据可能会存在偏差估计,导致样本数据不能很好的代表总体,因此需要对缺失值进行处理,针对洪水过程中缺失值的处理参考《水文资料整编规范》(sl247-2012)。实际的洪水过程预测往往涉及到降雨量、蒸发量、流量、水位等多种数据,,为了消除这些不同的属性和指标间存在的数量级和量纲的差异,采用min-max标准化,也称为离差标准化,它将原始数据进行线性变化,通过转化公式将原始值映射到[0,1]之间。转化公式如(1):
其中x*为转换后的值,x为原始值,xmin=min(x),xmax=max(x)。经过min-max标准化后,原始值被规约到[0,1]之间。其中,max(x)取x对应指标的历史最大值,min(x)取x对应指标的历史最小值。
(2)分析流量信息与降雨量、蒸发量之间的相关性,获取预测输入数据的时间窗口宽度。对各场历史洪水过程数据序列采用皮尔逊相关系数分析因变量(流域出口流量)与各自变量(流域内各雨量站的降雨量、蒸发站的蒸发量等)的相关性,确定各自变量对因变量影响的时间范围,各自变量的影响范围的并集作为整体输入量对输出量影响的时间范围,获取预测输入数据的长度。
若某场洪水过程有流域出口流量q序列qt0,qt1,qt2,…,qtn,某雨量站/蒸发站监测的雨量/蒸发量di序列为dit0,dit1,dit2,…,ditn,分析di对q的影响时间范围,
逐步将di前移1个时间单位,并分别分析与q之间的相关性,相关系数一般逐渐增加,到最高值,然后逐渐减小,如图2所示。
若当时间差=w时,相关系数任然大于等于50%,当时间差=w+1时,相关系数小于50%,则该di对q影响的时间宽度为w,即认为dt(n-k)至dtn的降雨数据都对qtn有影响。分析所有自变量对因变量的影响时间宽度,取最大值作为步骤(3)中的建立训练数据的滑动窗口宽度。
(3)建立预测模型训练数据集。利用步骤(1)中分析得到的时间范围w作为滑动窗口的宽度,按照步长为1提取历史洪水过程数据以及同步的降雨、蒸发等作为输入,对应输出为指定预测预见期的流量。如下为一个输入输出对,所有输入量对输出量影响的最大时间范围为w。
表示预测模型的输入为i的矩阵,输出为o,有m+1个输入量,其中,di表示某个测站监测的降雨量或蒸发量序列等,q表示流量序列,预见期为n。
(4)建立基于卷积神经网络的预测模型cnnfm,并利用训练数据进行训练。模型主要包括卷积层、池化层、激活函数。卷积层采用google深度学习框架tensorflow来实现,使用以下程序来进行卷积神经网络前向计算过程中卷积层的模块设计。
filter_weight=tf.get_varialble('weight',[patch,insize,outsize],initializer)(2)
biases=tf.get_varialble('biases',[outsize],initializer)(3)
式(3-1),(3-2)中filter_weight与biases分别为通过tf.get_varialble方法创建的卷积层中滤波器的权重向量和阈值向量。filter_weight中包含一个4维矩阵的参数,前二个维度为滤波器的尺寸(长宽),后两个维度为当前层的深度和滤波器的深度;biases中包含的参数为与权重向量个数相匹配的阈值向量,initializer为权重阈值的初始化策略。tensorflow提供conv2d函数来实现卷积层的核心算法:
tf.nn.conv2d(input,filter_weight,strides,padding)(4)
其中input为接收上一层的输出,即本层的输入,filter_weight提供了当前卷积层的权重参数,strides为滤波器在卷积过程中的步长参数,padding为tensorflow提供的卷积步长策略。
为了减少模型中的参数,并降低计算量,在卷积层后添加池化层,对卷积层输出得到的特征映射做抽样或聚合,减少计算量,避免过拟合。tensorflow提供以下两种池化策略函数tf.nn.max_pool和tf.nn.avg_pool:
tf.nn.max_pool(input,ksize,strides,padding)(5)
tf.nn.avg_pool(input,ksize,strides,padding)(6)
input为上层的输出,即为池化层的输入,ksize为池化窗口大小参数,strides为池化窗口移动步长,padding为池化操作后大小保留的策略。
激活函数的选择的对于整个卷积神经网络的预测结果有着很大的影响,选择合适的激活函数可以提高网络模型的收敛速度。本发明使用矫正的线性激活函数relu函数,当神经元输出的值小于0时恒为0,否则保持原来的值不变。这样,激活函数导数大于0时恒为1,可以将梯度很好的传递到上一层,避免了梯度消散的问题,加快了误差反向传播,极大的提高了训练的速度。
(5)建立误差校正模型bpcm训练数据集。其输入与步骤(3)中的模型训练数据集输入相同,输出为预测模型cnnm的预测误差。假设对输入i=
(6)基于加权knn的误差校正模型进行误差校正。针对加权knn的误差校正模型校正时,在训练数据集搜索预测输入的k近邻,采用距离加权对k近邻的误差求均值,将近邻按照于预测输入的欧式距离从小到大排序,第i近邻的权重如下:
最终的基于knn的预测输出的校正误差
(7)利用预测模型和校正模型对真实数据进行预测。将校正误差作用于cnnffm预测模型的结果prevalue,则最终预测结果为prevalue-e。采用纳什效率系数(nash-sutcliffeefficiencycoefficient,nse)来评定预测结果的质量。
(8)洪水预测的评价。
纳什效率系数
对水文过程模拟的效果检验使用纳什效率系数(nash-sutcliffeefficiencycoefficient,nse)[55]来评定,nse一般用来验证水文过程模拟结果的好坏。nse的取值范围为负无穷到1,nse的值越接近1是模型预测的质量越好,模型可信度越高;nse的值越接近0,表示模型预测的结果接近平均值水平,预测结果总体可信,但存在较大误差;nse的值远远小于0,预测结果是不可信的。nse计算方法如式(7)。
2)均方根误差(rmse)
实施例:
实施例:
为了验证本发明的效果,选取安徽省屯溪流域,建立模型预测该流域内的洪水过程,流域集水面积2696.76平方公里,地处亚热带季风气候,气候适宜,年平均温度17℃,雨量充沛。选取从1982年到2002年间发生的33场洪水数据作为实验的研究资料。所有数据都经过水文数据整编处理,不存在缺失数据。
下面从预见期、实时校正结果两个方面,进行对比实验,分析实验结果并检测模型的可用性。
1)从实验模型的预见期出发。以预见期为出发点设计对比实验,进行流量预报,设置预见期分别为1小时、2小时、4小时的卷积神经网络流量预测实验,使用nse、rmse、mae三个评价指标对模型的预测结果进行分析。
2)从对预测结果的实时校正方面出发。将预测结果结合基于得分加权的组合校正模型来进行实时校正,结合预测结果与nse、rmse、mae评价指标,测试未经过实时校正的预报模型的性能,与未经过实时校正的预报模型的测试结果进行对比。
1.数据准备
本节以屯溪流域(包括11个报讯雨量站、1个蒸发站,如图3)降雨量及流量数据作为实验数据,选取从1982年到2002年间发生的33场洪水数据作为实验的研究资料。
表3.1水雨情报汛站网
屯溪流域位于我国东南沿海[56],流域集水面积2696.76平方公里,地处亚热带季风气候,气候适宜,年平均温度17℃,雨量充沛,年降水量1600毫米,年
内降水分配不均,其中4-6月降水较为充沛,易发生洪涝灾害;7-9月降水较少,旱灾频繁。如图3为屯溪流域报汛站网分布图,部分降雨及流量数据如表1。
表11989年部分降雨流量表
实验数据为屯溪流域流量雨量数据,其中1982年~1994年间23场洪水数据作为训练集,1995年~2002年间10场洪水数据作为测试集。
历史洪水数据在水文数据整编过程进行了异常和缺失处理,因此本实验无需要处理。我们首先对历史水文数据进行皮尔逊相关系数分析得到预测输入时间段,设当前时刻为t,选取t-14时刻到t时刻屯溪流量与11个雨量站的的数据进行皮尔逊相关性分析。
由上表可以看出,t时刻屯溪流量与t-8时刻流量之间,随着时间越来越接近t时刻,变量之间的相关性越高;其余11个雨量站与屯溪流量之间的相关性随着时间越来越接近t时刻呈现出变量相关性先单调递增再单调递减的趋势,综合来看,选取当前时刻t时前8个时刻的历史信息作为输入数据。
(3)采用min-max标准化,也称为离差标准化,它将原始数据进行线性变化原始值被规约到[0,1]之间。
以下文中预见期为1小时为例,使用滑动窗口技术对训练和测试数据进行滑动切分,将预见期前8小时流量及雨量数据作为输入数据,后1小时流量数据作为输出数据建立预测模型。训练样本数据和测试样本数据(归一化前)如表2。
表2屯溪雨量流量1h预见期数据集
以上训练数据为预见期为1小时时实验数据,hisdata表示预见期前8小时的流量雨量数据,predliuliang1为预见期预测的流量值。当预见期为2小时、4小时时,上述训练集格式需作相应改动。
2.cnnfm模型建立
cnnfm模型输入层-输出层参数确定:由以上分析,输入层为预见期前8h流量雨量数据,总计共12×8个神经元节点,输出层为预见期大小(假设为4h,共4个神经元)。
cnnfm模型卷积层参数确定:其中滤波器中初始权重向量初始化策略采取tensorflow中提供的tf.truncated_normal,它从截断的正太分布中获取随机值;阈值向量采取tf.constant(0.1),将阈值向量初始化为0.1。共设置3个卷积层,节点个数分别为128、256、512,设置卷积层参数为式(9),其中filter_weight卷积核大小为3×3,strides滑动步长为1。
tf.nn.conv2d(x_input,filter_weight,strides=[1,1,1,1])(9)
cnnfm模型池化层参数确定:考虑到屯溪流域降雨充沛,但年内降水分配不均的特点,且数据中多存在降雨为0mm的时刻数据,为保留数据的纹理信息,在减少参数的同时,保留更多的特征,采用maxpooling最大值池化策略来设计池化层,在每一个卷积层后添加一个池化层,池化函数为式(10),其中池化窗口大小为2*2,滑动步长为2。
tf.nn.max_pool(x_input,ksize=[1,2,2,1],strides=[1,2,2,1])(10)
cnnfm模型激活函数及其他参数确定:使用relu激活函数对卷积池化输出结果进行保留映射,在其后添加1024个神经元节点的全连接层,使其连接到相应数目的输出节点。设置学习率时使用tf.train.adamoptimizer自适应学习率优化算法,不需要人为调整学习率,使用默认参数就可能获得最优值。训练总轮数设置为100000。
3.实验分析
1)不带实时校正的模型在不同预见期内准确率对比
对预见期为1h、2h、4h进行基于卷积神经网络的洪峰预测,选择预报的最后一小时预报结果作为表格统计结果,测试结果如表3。
表31h、2h、4h预见期洪水模拟特征值
以测试数据中1997060608号洪水预报为例,流量过程预测如图4。
对预见期为1h、2h、4h进行基于卷积神经网络流量过程预测,计算得到nse、rmse、mae这三个指标,结果如表2。
表2不同预见期洪水过程预测实验结果评价指标表
根据实验结果所示,对于测试数据中10场洪水过程而言,卷积神经网络模型预测洪峰在三种预见期下平均相对误差分别为6.5%、10.2%与14.14%;纳什效率系数均值分别为97.71%、94.57%与89.17%;在1998050108号和1999062215号洪水峰现时间上存在较大误差,总体预报结果良好。由应用结果可以看出,rmse与mae均随预见期延长而提高,总体看来积神经网络模型能够很好的模拟屯溪流域的洪水过程,并且显示出随预见期延长,预报误差逐渐增大的趋势。按照《水文情报预报规范》(gb/t22482-2008),卷积神经网络模型在1h、2h、4h预见期下水文过程模拟结果分别达到了甲级、甲级、乙级标准。
2)卷积神经网络预报结合实时校正的分析
本节针对预测结果从带有实时校正以及不带实时校正的结果来分别展示预测结果,以预见期中最后一小时预测结果进行实验分析。
(1)实验结果
1.使用加权knn校正模型knncm来对屯溪流域预测数据进行实时校正,已知测试数据集为1995年~2002年间共计10场洪水数据。
以2001050108号洪水数据为例,预见期为1h时,预测结果以及校正结果如图5。
预见期为2h时,预测结果及校正结果如图6。
预见期为4h时,预测结果及校正结果如图7。
2.对预见期为1h、2h、4h进行基于卷积神经网络流量预测,计算得到nse、rmse、mae这三个指标,结果如表3.7。
表3.7结合实时校正的洪水过程预测实验结果评价指标表
(2)实验分析
根据实验结果所示,随着预见期延长,洪水预报结果精度逐渐下降,并且在对预测结果进行组合模型校正之后,与不带校正的预测结果相比,预见期为1h、2h、4h时,rmse、mae有小幅度缩减,nse有提高。经组合校正后三种预见期下纳什效率系数均超过0.9,按照《水文情报预报规范》(gb/t22482-2008),卷积神经网络模型在1h、2h、4h预见期下水文过程模拟结果均达到了甲级标准。
以上所述仅是本发明的优选实施方式,应当指出:对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 一种基于复杂网络的欺诈团伙识...
- 一种货运车辆配载方法与流程
- 用于纺纱生产的优化排包方法与...
- 基于群体劝说力建模的网民观点...
- 一种二手车定价优化方法及系统...
- 植物根系水平分布模型构建方法...
- 一种基于人工智能的在线教育课...
- 具有医生搜索功能的医疗预约挂...
- 企业会议管理系统的制作方法
- 一种电子服务券的发放与使用方...
- 还没有人留言评论。精彩留言会获得点赞!