基于连续动作学习自动机的全局优化系统及方法与流程
本发明涉及的是一种学习自动机优化领域的技术,具体是一种基于连续动作学习自动机的全局优化系统及方法。
背景技术:
随机函数优化方法,一般利用概率机制描述其求解的迭代过程,区别于确定性函数化方法中的确定性点列,由此显现算法的重要基础便是随机性。此类算法适用范围广,往往可用于解决大规模的连续和离散函数的最优化、组合优化等问题。算法理论上可以保证以概率1收敛到全局最优值,但相对花费的时间也很多。由于学习自动机具有极强的抗干扰能力和全局优化能力等优点,在函数优化方面得到了应用并展示出良好的应用前景。
学习自动机(la)是模拟生物从出生开始具备很少的先天知识,而不断与随机环境交互的学习过程而建立的。la通过与环境的不断交互,调整自身决策概率向量,自适应地学习到一个最优的行为,这里的最优行为指的是有着最大奖励概率的行为。学习自动机的功能也就能简单的描述为与环境进行的一系列有反馈的重复的循环交互。
根据动作集的种类,学习自动机分为有限动作学习自动机(fala)和连续动作学习自动机(cala)。fala的动作集是有限的数,而cala的动作集是无限的,一般从实数轴中选取一段代表动作。在实际的函数优化过程中,现实的环境往往是多变而且复杂的,因此有限动作的学习自动机在随机环境中的应用远远不如连续动作。
在全局优化问题中,最常见的问题是在找到一个局部最小解后而陷入困境,无法找到全局最优解。因此,全局优化问题的一个重要的问题就是如何能够跳出局部最优解。经典的连续动作集学习自动机算法虽然也可以收敛到最佳的行为,但是存在比较严重的容易陷入局部极小值和抗噪能力比较弱的问题。
技术实现要素:
本发明针对现有技术存在的上述不足,提出一种基于连续动作学习自动机(cala)的全局优化系统及方法,在cala算法中引入平滑函数,并对平滑函数进行改进,有利于跳出全局优化函数中的局部最优值,并使得之后的搜索更具有方向性。
本发明是通过以下技术方案实现的:
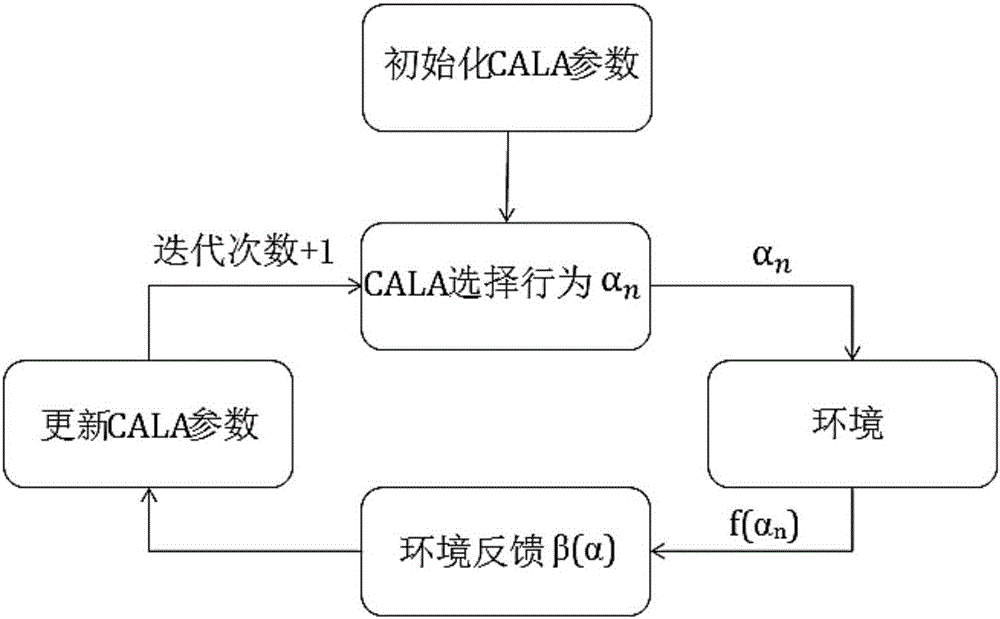
本发明涉及一种基于连续动作学习自动机的全局优化系统,包括:初始化模块、行为选择模块、环境反馈模块、更新模块和输出模块,其中:初始化模块初始化cala算法的参数,输入行为选择模块进行行为选择,行为通过路径环境的应用得到反馈然后进入环境反馈模块,得到行为对应的环境反馈;更新模块根据环境反馈更新cala算法的参数,将更新的参数输入行为选择模块完成一次迭代;当迭代次数达到设定值时,将当前的环境反馈输入输出模块,输出最优的路径信息。
本发明涉及一种基于连续动作学习自动机(cala)的全局优化方法,首先通过现有的cala算法得到局部最优解,根据该局部最优解得到改进的平滑函数;将改进的平滑函数引入现有的cala算法得到优化的cala算法,通过优化的cala算法进行多次迭代,最终得到极值点,作为全局极小值输出。
所述的迭代是指:在cala算法中引入改进的平滑函数进行一轮迭代得到局部最优解,当本轮局部最优解小于上一轮迭代得到的局部最优解时,将本轮迭代得到的局部最优解设置为局部最优解的点,再进行下一轮迭代,直至当前一轮迭代的局部最优解大于或等于上一轮迭代得到的局部最优解,即上一轮迭代得到的局部最优解为极值点。
所述的迭代在每一轮中的次数相同。
所述的改进的平滑函数的定义为:
所述的优化的cala算法包括以下步骤:
步骤1、初始化cala算法的参数,并设定迭代次数和各常量参数的值。
步骤2、根据当前的分布随机产生一个值并将该值作为行为输入环境,得到观测值。
步骤3、从环境中获得相应的反馈,即引入改进的平滑函数。
步骤4、根据步骤3中的反馈更新分布的均值和标准差。
步骤5、对迭代次数进行计数,如果迭代次数小于设定的每轮迭代的次数,则回到步骤2;否则观测值作为本轮得到的局部最优解进行步骤6。
步骤6、当本轮迭代得到的局部最优解小于上一轮迭代得到的局部最优解时,将本轮的局部最优解赋值给上一轮得到的局部最优解的点并记录,返回步骤2进行下一轮迭代;否则将上一轮迭代得到的局部最优解的点(即极值点)作为全局极小值输出,结束本算法。
所述的标准差的迭代次数在每轮迭代中不清零。
技术效果
与现有技术相比,本发明首先通过引入平滑函数来跳出全局优化函数中的局部最优值,然后再针对现有平滑函数遇到的在平稳区域搜索无方向性通过加入斜率分量进行改进,改进后的平滑函数依然保有原平滑函数的优点:能够忽略掉所有不优于当前点的解,并且容易从当前局部最优点中跳出,此时全局优化函数存在一定的斜率,使得接下去的搜索方向远离局部极小值,而不会在当前点做来回移动的无用功;并且可提高算法的收敛速度。
附图说明
图1为全局优化方法流程示意图。
具体实施方式
在最优路径选择、最佳治疗效果领域(如:信息传播最大化、最优计量药物选择等)中,本方法可以首先通过现有的cala算法得到现在路径的局部最优解,由于该路径可能只是局部最优路径,而不是全局最优路径,然后根据该局部最优解得到改进的平滑函数;将改进的平滑函数引入现有的cala算法得到优化的cala算法,通过优化的cala算法进行多次迭代,最终得到极值点,作为路径选择后的全局极小值输出,从而得到最优路径选择方案。
所述的迭代是指:在cala算法中引入改进的平滑函数进行一轮迭代得到局部最优解,当本轮局部最优解小于上一轮迭代得到的局部最优解时,将本轮迭代得到的局部最优解设置为局部最优解的点,再进行下一轮迭代,直至当前一轮迭代的局部最优解大于或等于上一轮迭代得到的局部最优解,即上一轮迭代得到的局部最优解为极值点。
所述的迭代在每一轮中的次数相同,具体次数根据实验的实际情况得到,且不能过低,否则易找不到极值点。
如图1所示,本实施例具体包括以下步骤:
步骤1、初始化连续动作学习自动机(cala)算法的参数,设定各参数的值。
所述的参数包括:迭代次数t、常量a、b、λ1和λ2(其中参数设置t为20000,迭代轮数m=4,每一轮迭代开始已迭代次数n设为0。)。
设fmin=inf,t=inf,t为实验设置的最优迭代次数,以保证第一次搜索不利用平滑函数。
步骤2、根据环境行为的情况可确定行为属于正态分布,然后由当前的分布n(μ,σ)(μ为均值,σ为标准差,这两个向量的初始值由具体的环境行为确定,根据一般cala算法可以得到)随机产生一个值αn(n为已迭代次数)并把αn行为输入环境。
步骤3、从环境中获得相应的反馈β(αn),即引入改进的平滑函数。
所述的改进的平滑函数是指在平滑函数末尾加入一项以从当前的局部最优解跳出,并作为cala中环境的反馈来完成对选择动作的影响。
所述的平滑函数可定义为:当原函数在某点的值大于目前获得的最优解的值时,将这点的值重新赋值为目前获得的最优解;当原函数在某点的值小于目前获取的最优解的值时,该点的值保持不变,即:f(x,x*)=min(f(x),f(x*)),其中:x为当前选择的值,x*为已获得的局部最优解的值,f(.)为求取函数。
所述的改进的平滑函数f′(x,x*)=min(f(x),
所述的反馈β(αn)=(min(fmin,f(αn))-λ1)/λ2,其中:f(αn)为shubert函数(优化的基准函数)在αn点的观测值。
步骤4、根据环境的反馈β(αn)更新分布的均值μ和标准差σ。
所述的更新是指:μn+1=μn-a*β(αn)(αn-μn)σn;
步骤5、若已迭代次数n小于t,则返回步骤2;否则进行步骤6。
步骤6、若fmin大于f(αn),即找到了更小值,则fmin=f(αn),t=n;记录当前最小值点f(αn),返回步骤2并重新计算迭代次数,但标准差σ中的迭代次数计数不归零;否则结束本算法。
为证明本实施例的一般性,将本实施例在无噪声、标准差分别为0.1和0.5的两个高斯噪声以及两个范围分别在[-0.1,0.1]和[-1,1]的均匀白噪声共5个环境中进行实验。根据shubert函数对四种算法分别进行50次实验,求平均值,得到各算法的正确率与平均迭代次数,比较实验结果得出结论。
所述的四种算法分别为:基于cala的函数优化算法(算法1)、基于与改进的平滑函数结合的cala的函数优化算法(算法2)、基于改进的cala的函数优化算法(算法3)以及基于与平滑函数结合的改进的cala的函数优化算法(算法4),其中:算法4为本发明的算法。
所述的shubert函数为一个用于测试优化性能的基准函数。
所述的迭代次数记为t,每轮迭代动用t次去搜索最小值,然后观察是否找到更小值以及是否需要继续运行算法,实验中t=20000。
实验目的是针对算法1这一类普通的cala算法以及算法3这种常见的改进的cala算法中本身存在的比较严重的容易陷入局部极小值和较弱的抗噪能力的问题进行改进,通过算法1和算法2(加入改进的平滑函数)与改进后的算法3和算法4(加入了改进的平滑函数)进行对比实验,得到实验结果。
所述的算法1具体包括以下步骤:
s1:初始化行为取值的高斯分布的均值μ与方差σ,两者根据行为区间随机选择。
s2:根据当前的分布n(μ,σ)随机产生一个值αn并把αn和μn作为两个行为输入环境,n为当前迭代次数,1<=n<=20000,αmin≤αn≤αmax(此时n为1)。
s3:从环境中获得反馈β(αn)和β(μn):
s4:更新μ和σ:
μn+1=μn+p*f1[μn,σn,αn,β(αn),β(μn)],
σn+1=σn+p*f2[μn,σn,αn,β(αn),β(μn)]-c*α[σn-σl];
其中:
s5:当迭代次数达到t时,结束本算法,将n作为函数最优点输出,否则返回s2。
所述的算法2具体包括以下步骤:
s1:初始化t、a、b、μ和σ的值,并设fmin=inf,t=inf,以保证第一次搜索不利用平滑函数。
s2:根据当前的分布n(μ,σ)随机产生一个值αn并把αn和μn作为两个行为输入环境,n为当前迭代次数,1<=n<=20000。
s3:从环境中获得反馈β(αn)和β(μn):
s4:更新μ和σ:
μn+1=μn+a*f1[μn,σn,αn,β(αn),β(μn)]
σn+1=σn+a*f2[μn,σn,αn,β(αn),β(μn)]-c*αn[σn-σl];其中:f1(.)、f2(.)和
s5:若迭代次数小于t,则返回s2;否则进行s6。
s6:若fmin大于f(n),即经过本轮的t次cala算法找到了一个比上一轮迭代得到的局部极小值更小的局部极小值点,则使fmin=f(n),t=n以记录当前最小值点。返回s2并重新计算迭代次数;否则结束本算法。
所述的算法3具体包括以下步骤:
s1:初始化行为取值的高斯分布的均值μ与方差σ,两者根据行为区间随机选择。
s2:根据当前的分布n(μ,σ)随机产生一个值αn并把αn和μn作为两个行为输入环境,n为当前迭代次数,1<=n<=20000。
s3:将αn和μn作为两个行为输入环境并从环境中获得反馈β(αn)和β(μn):β(αn)=(min(fmin,f(αn))-λ1)/λ2,β(μn)=(min(fmin,f(μn))-λ1)/λ2
s4:更新μ和σ:μn+1=μn-c*β(αn)(αn-μn)σn,
s5:当已迭代次数n达到t时,结束本算法,把n作为函数最优点输出,否则返回s2。
所述的四种算法的参数设置如下:
算法1:m=4,p=3*10^-4,σl=0.01,c=5;
算法2:m=4,p=3*10^-4,σl=0.01,c=5,a=10,b=1;
算法3:c=1,λ1=-15,λ2=30,m=4;
算法4:λ1=-15,λ2=30,m=4,a=10,b=1。
所述的shubert函数为:
所述的函数u(x,b,k,m)在[-10,10]之间拥有19个局部极小值点,其中的3个是全局最小值点。当x在-5.9、0.4和6.8时能取到全局极小值点,有全局最小值点为-12.87。
所述的实验结果如表1所示,迭代轮次均为3轮。
表1各算法平均正确率(%)
在高斯噪声的环境下进行的实验结果显示,标准差为0.1时算法3与算法4的平均正确率分别为56%和86%,性能提高了0.34倍;标准差为0.5时算法3与算法4的平均正确率分别为58%和84%,性能提高了0.44倍。
通过实验结果可以得到结论:现有的cala算法与改进的cala算法中加入了改进的平滑函数后,可以跳出局部最小值,并且抗噪能力大大增加。
本实施例涉及一种最优路径的优化系统,包括:初始化模块、行为选择模块、环境反馈模块、更新模块和输出模块,其中:初始化模块初始化cala算法的参数,输入行为选择模块进行行为选择,行为通过路径环境的应用得到反馈然后进入环境反馈模块,得到行为对应的环境反馈;更新模块根据环境反馈更新cala算法的参数,将更新的参数输入行为选择模块完成一次迭代;当迭代次数达到设定值时,将当前的环境反馈输入输出模块,输出最优的路径信息。
采用本实施例的算法后,得到的最优路径,相比于现有技术的路径选择,不会被局部极小点约束,抗噪能力也有明显提升。
上述具体实施可由本领域技术人员在不背离本发明原理和宗旨的前提下以不同的方式对其进行局部调整,本发明的保护范围以权利要求书为准且不由上述具体实施所限,在其范围内的各个实现方案均受本发明之约束。
- 量子状态搜索方法及装置与流程
- 一种模糊推理系统的完备决策生...
- 一种深度神经网络推理方法及计...
- 一种基于自适应深度置信网络的...
- 一种深度学习的参数交换方法、...
- 数据处理方法、数据处理装置以...
- 神经形态多位式数字权重单元的...
- 一种用于深度神经网络高速实时...
- 信号处理的系统和方法与流程
- 一种卷积神经网络的建立装置及...
- 还没有人留言评论。精彩留言会获得点赞!