社交网络的无偏数据采集系统及采集方法与流程
本发明涉及社交网络数据采集技术领域,具体涉及一种社交网络的无偏数据采集系统及采集方法。
背景技术:
社交网络(socialnetwork)指人与人之间、组织与组织之间为达到特定的目的进行信息交流而形成的关系网。由于互联网的兴起与发展,twitter、facebook、微博等具有代表性的提供社交网络服务的平台得到了飞速发展。随着用户群体的迅速增长,用户与用户之间进行信息交流形成的社交网络结构也变得更加复杂,这些变化自然引起了国内外学者的广泛关注,使得社交网络成为了一个新的研究领域。
社交网络通常会模型化为社交图进行研究分析。研究者直接面临的问题就是社交网络的数据量太过庞大。首先,想要得到完整的数据集是不切实际的,因为抓取到如此庞大的社交图要耗费难以想象的时间,有些时候也是不可能的。与此同时,处理如此庞大的社交图,即使利用高性能计算机集群也需要大量的时间进行计算。其次,出于商业机密以及用户的私有设置,社交网络的完整数据也并不可获得。最后,社交网络的用户数量增长迅速并且用户间的关系会随时间改变,因此经典的大型网络并不能完全爬取。所以,如何在大型网络中抓取适量的样本,并保持原始网络的网络属性就成了社交网络研究的基础问题。
目前常用的网络抽样技术,普遍上应用广度优先搜索算法进行数据抽样。广度优先搜索算法虽然可以快速获取大量用户数据。然而在实际的生产中需要消耗大量资源设计去重队列,这样会大大减少数据的抽取效率。同时广度优先搜索算法是典型的网络的遍历算法,其算法抽取的数据会偏向高度的节点,从而该方法不能获取可靠的用户数据。
技术实现要素:
为了解决现有社交网络数据抽取方案不能获取无偏数据以及需要设计去重队列的不足,本发明提供一种社交网络的数据采集系统及方法,从而可以获取更加可靠的无偏数据,具体技术方案如下:
一种社交网络的无偏数据采集系统,其包括用户信息抓取模块、用户节点选择模块和社交网络数据存储模块,其中,所述用户信息抓取模块通过网页解析技术或请求第三方api的方式从社交网络服务商获取用户数据,所述的获取的用户数据是根据需要抽样的网络决定的;
所述用户节点选择模块包括待爬用户缓存区及下一用户选择子模块,所述待爬用户缓存区采用redis高速缓存数据库设计的数据结构实时存储被探索用户的用户id,以及该用户id被探索的次数;所述的下一用户选择子模块通过带有延迟接受技术的马尔科夫链随机游走算法,从当前用户的好友中选择下一个爬虫用户,并采用geweke诊断算法检测单个马尔科夫链的数据收敛情况;
所述社交网络数据存储模块将爬虫过程中抽取到的用户信息持久化保存到数据库中,并保持用户数据的更新及对重复爬取的数据做删除处理。
进一步的,所述待爬用户缓存区采用redis高速缓存数据库设计数据结构,所述数据结构采用字典嵌套列表的形式,将具有相同好友数量的用户id放入同一个数据块中,并记录每一个用户id的被访问次数,每当新的用户u需要压入缓存区时,会执行以下步骤:
步骤一:根据好友数量及用户id查询缓存区是否已经存在用户u,若不存在,增加用户u的用户id,并置该用户的被访问次数n为1;若存在,执行步骤二;
步骤二:更新用户u的被访问次数,使被访问次数n自加1。
更进一步的,所述下一用户选择子模块的用户采用如下选择策略:
步骤一:在当前用户的好友列表中等概率的随机选择一定数量的好友,一般取5~10个好友,将他们的用户id及好友数量存入待爬用户缓存区中;
步骤二:随机在当前用户的好友列表中选择一个用户u;
步骤三:当用户u的好友数量/当前用户好友数量>=随机小数[0,1]时,直接将用户u作为下一个待爬取的用户;当用户u的好友数量/当前用户好友数量<随机小数[0,1]时,以80%的概率从待爬用户缓存区中选择被访问次数最少的同时与用户u具有相同用户数量的用户id作为下一个待爬取用户,以20%的概率直接将用户u作为下一个待爬取的用户;
更进一步的,采用geweke诊断算法检测单个马尔科夫链的数据收敛情况的步骤具体如下:
令数列x为爬虫过程中按时间顺序排列的用户好友数量,geweke诊断将x分为两个子数列xa和xb,计算数值z:
其中,xa为用户好友数量的前10%,xb为用户好友数量的后50%,e(xa)为xa的平均值,e(xb)为xb的平均值,x为x中某个样本值,即某个具体用户的好友数量,n为样本数量,即x数列中元素的个数;
若从某个数据量开始,z的值都在[-1,1]这个区间,则诊断为收敛。
上述社交网络的无偏数据采集系统采用如下的数据采集方法:
步骤一,从社交网络中随机选择一个当前用户v,并通过网页解析技术或请求第三方api的方式从社交网络服务商获取该用户数据,所述的获取的用户数据是根据需要抽样的网络决定的;
步骤二,采用通过带有延迟接受技术的马尔科夫链随机游走算法,从当前用户的好友中选择下一个爬虫用户,采用redis高速缓存数据库设计的数据结构实时存储被探索用户的用户id,并采用geweke诊断算法检测单个马尔科夫链的数据收敛情况;
步骤三,将爬虫过程中抽取到的用户信息持久化保存到数据库中,并保持用户数据的更新及对重复爬取的数据做删除处理。
进一步的,其中所述的redis高速缓存数据库设计的数据结构采用字典嵌套列表的形式,将具有相同好友数量的用户id放入同一个数据块中,并记录每一个用户id的被访问次数,每当新的用户u需要压入缓存区时,会执行以下步骤:
步骤一:根据好友数量及用户id查询缓存区是否已经存在用户u,若不存在,增加用户u的用户id,并置该用户的被访问次数n为1;若存在,执行步骤二;
步骤二:更新用户u的被访问次数,使被访问次数n自加1。
更进一步的,所述下一爬虫用户的选择采用如下选择策略:
步骤一:在当前用户的好友列表中等概率的随机选择一定数量的好友,一般取5~10个,将他们的用户id及好友数量存入待爬用户缓存区中;
步骤二:随机在当前用户的好友列表中选择一个用户u;
步骤三:当用户u的好友数量/当前用户好友数量>=随机小数[0,1]时,直接将用户u作为下一个待爬取的用户;当用户u的好友数量/当前用户好友数量<随机小数[0,1]时,以80%的概率从待爬用户缓存区中选择被访问次数最少的同时与用户u具有相同用户数量的用户id作为下一个待爬取用户,以20%的概率直接将用户u作为下一个待爬取的用户;
更进一步的,所述采用geweke诊断算法检测单个马尔科夫链的数据收敛情况的步骤具体如下:
令数列x为爬虫过程中按时间顺序排列的用户好友数量,geweke诊断将x分为两个子数列xa和xb,计算数值z:
其中,
其中,xa为用户好友数量的前10%,xb为用户好友数量的后50%,e(xa)为xa的平均值,e(xb)为xb的平均值,x为x中某个样本值,即某个具体用户的好友数量,n为样本数量,即x数列中元素的个数;
若从某个数据量开始,z的值都在[-1,1]这个区间,则诊断为收敛。
本发明的有益效果是,可以从社交网络中爬取无偏的数据,这样采集的用户信息的度分布与原始网络相同,即,网络中的每个用户被等概率的抓取,有效解决了一般抽样方法的信息偏移问题,并且该方法可以克服一般的社交网络系统需要耗费大量时间空间资源去处理重复用户信息的缺点。
附图说明
图1为社交网络数据的无偏采集系统结构图;
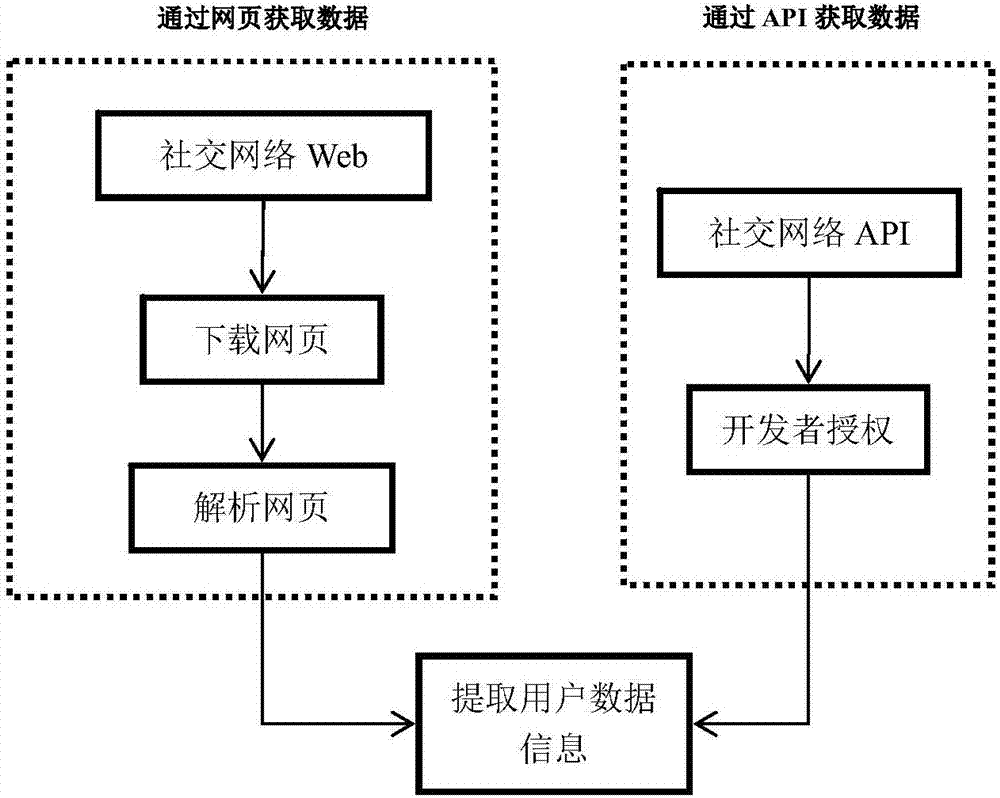
图2为社交网络用户信息抓取模块图;
图3为社交网络的无偏数据采集系统中下一用户选择流程图;
图4为待爬用户缓存区数据结构示意图;
图5为用户数据抽样的收敛性判断过程。
具体实施方式
下面结合附图对社交网络的无偏数据采集系统及采集方法作进一步的说明。
如图1所示,本发明的社交网络的的无偏数据采集系统包括用户信息抓取模块、用户节点选择模块和社交网络数据存储模块。其中用户信息抓取模块通过网页解析技术或请求第三方api的方式从社交网络服务商获取用户数据,获取的用户数据通常根据需要抽样的网络决定,主要包括年龄,性别,地区,昵称,关注者列表,粉丝列表等。
如图2所示,用户信息抓取模块可以通过网页获取数据,或者调用企业api的方法获得相应的用户信息数据。其中,
通过网页解析技术从社交网络服务商获取用户数据的步骤如下:
1)用户登录认证,采用cookies伪装认证;
2)获取用户信息页面的url链接地址;
3)从社交网络上下载用户页面的html源码;
4)用xpath或正则表达式从下载的源码中抽取用户信息。
通过第三方api从社交网络服务商获取用户数据的步骤如下:
1)使用oauth2.0进行得到accesstoken;
2)获取希望抽取的用户id;
3)调用api接口,获取相应xml或json文件;
4)解析xml或json文件,得到用户信息数据。
本发明所提取用户信息是根据具体需要抽样的网络进行设计的,以微博为例子,但不限于一种社交网络。更具体的说需要提取的用户信息可以有:1)用户id:采用“用户id”作为唯一标识;2)用户的好友数量num_frients(若为有向社交网络,需要附加粉丝数量num_fans,关注数量num_follows;3)出生日期birthday;4)所在城市city;5)微博的个人首页url等。
用户节点选择模块包括待爬用户缓存区及下一用户选择子模块,待爬用户缓存区采用redis高速缓存数据库设计的数据结构,如图4所示,实时存储被探索用户的用户id,以及该用户id被探索的次数,所述数据结构采用字典嵌套列表的形式,将具有相同好友数量的用户id放入同一个数据块中,并记录每一个用户id的被访问次数,每当新的用户u需要压入缓存区时,会执行以下步骤:
步骤一:根据好友数量及用户id查询缓存区是否已经存在用户u,若不存在,增加用户u的用户id,并置该用户的被访问次数n为1;若存在,执行步骤二;
步骤二:更新用户u的被访问次数,使被访问次数n自加1。
下一用户选择子模块通过带有延迟接受技术的马尔科夫链随机游走算法,从当前用户的好友(如关注者列表和分析列表)中选择下一个爬虫用户,其中下一用户选择子模块的用户采用如下选择策略,具体如图3所示:
步骤一:在当前用户的好友列表中等概率的随机选择一定数量的好友,一般取5~10个好友,将他们的用户id及好友数量存入待爬用户缓存区中;
步骤二:随机在当前用户的好友列表中选择一个用户u;
步骤三:当用户u的好友数量/当前用户好友数量>=随机小数[0,1]时,直接将用户u作为下一个待爬取的用户;当用户u的好友数量/当前用户好友数量<随机小数[0,1]时,以80%的概率从待爬用户缓存区中选择被访问次数最少的同时与用户u具有相同用户数量的用户id作为下一个待爬取用户,以20%的概率直接将用户u作为下一个待爬取的用户;
使用马尔科夫建模可以证明,以上的抽样策略可以等概率的获取网络中的用户信息,而不会偏向于采集社交网络中影响力大的用户信息(即,好友数量很多的用户)。
数据采集系统运行时,需要给出单次采集的最小收集数据量,用以保证收集到的数据是足够可靠的,也就是保证采集到的用户数据的网络度分布较真实网络而言是一致的。如图五,展示了执行一次无偏爬虫方案所获得的用户数据的收敛判断过程。更详细的有以下步骤:
第一步:从保存用户数据的数据库中,提取前10%的用户的好友数量,并按数据库中的顺序合成向量xa;同样的,提取后50%的用户的好友数量,并合成向量xb。
第二步:计算xa和xb的样本均值e(xa)和e(xb)。
第三步:计算xa和xb的样本方差var(xa)和var(xb),更具体的说:
其中,n为样本数量(即,xa的维度),x为具体的样本值(即,具体某个用户的好友数量
第四步:计算数值
社交网络数据存储模块将爬虫过程中抽取到的用户信息持久化保存到数据库中,并保持用户数据的更新及对重复爬取的数据做删除处理。
- 一种网络社区的用户推荐方法及...
- 基于隐空间的符号链接预测方法...
- 保费结算方法和装置与流程
- 理财产品推荐方法与流程
- 一种互联网金融资源整合的方法...
- 基于方向指向设备操作查看证券...
- 一种投资关系网络可视化分析方...
- 一种紧急交易的方法和装置与流...
- 一种账户交易方法和装置与流程
- 一种同种货币下多个账户管理行...
- 还没有人留言评论。精彩留言会获得点赞!
- 一种基于NB‑IoT的电表数据采集系统的制造方法与工艺
- 一种无线电表数据采集系统及其采集方法与流程
- 织机数据采集系统的制造方法与工艺
- 一种基于V/F的数据采集系统的制造方法与工艺
- 基于云平台的车载人体健康数据采集系统以及健康监控方法与流程
- 监控和数据采集系统及其数据设计方法与流程
- 用于测试风力涡轮机叶片的数据采集系统和数据采集方法与制造工艺
- 一种基于Hilscher的可信数据采集系统和方法与制造工艺
- 一种政务数据采集共享系统与方法与制造工艺
- 一种海底地震水下数据采集系统的制造方法与工艺
- 面向中小企业离散制造车间的数据采集终端的制造方法与工艺
- 一种无线通讯控制系统的制造方法与工艺
- 一种民机空调系统在线健康监测数据采集与分析方法与流程
- 基于传感器和物联网的企业金融数据采集系统的制造方法与工艺
- 一种基于FPGA的数据采集系统的制造方法与工艺
- 一种锂电池数据采集装置及系统的制造方法
- 一种IMF‑OBS多通道数据采集应用系统的制造方法与工艺
- 一种多功能模拟信号采集电路的制造方法与工艺
- 一种新型智能水表的数据采集方法与流程
- 分布式微型数据采集系统的制造方法与工艺
- 一种基于V/F的数据采集系统的制造方法与工艺
- 监控和数据采集系统及其数据设计方法与流程
- 一种基于Hilscher的可信数据采集系统和方法与制造工艺
- 一种政务数据采集共享系统与方法与制造工艺
- 一种基于LabVIEW和声卡的同步数据采集系统及采集方法与制造工艺
- 一种超低功耗基于无线传输的数据采集系统及采集方法与制造工艺
- 一种高招大本数据采集系统及方法与制造工艺
- 一种影视大数据采集方法及系统与制造工艺
- 一种运动数据采集系统的制造方法与工艺
- 一种安全可靠的数据采集系统的制造方法与工艺
- 一种车辆数据无线采集系统的制作方法
- 网络数据采集系统及方法
- 一种智能化的网络信息采集方法及网络信息采集系统的制作方法
- 一种基于大数据的网络导购系统的制作方法
- 一种停车位数据精准采集及网络预订系统的制作方法
- 应用于社区服务的gsm网络电能数据采集系统的制作方法
- 二维码在线采集系统、在线关联方法及数据收集设备的制造方法
- 一种数据终端采集系统的制作方法
- 一种基于分布式网络数据定向采集的方法
- 一种基于3g网络的智能家居数据采集系统的制作方法
- 一种无线电表数据采集系统及其采集方法与流程
- 织机数据采集系统的制造方法与工艺
- 一种基于V/F的数据采集系统的制造方法与工艺
- 基于云平台的车载人体健康数据采集系统以及健康监控方法与流程
- 用于测试风力涡轮机叶片的数据采集系统和数据采集方法与制造工艺
- 一种基于Hilscher的可信数据采集系统和方法与制造工艺
- 一种政务数据采集共享系统与方法与制造工艺
- 一种基于LabVIEW和声卡的同步数据采集系统及采集方法与制造工艺
- 一种超低功耗基于无线传输的数据采集系统及采集方法与制造工艺
- 一种高招大本数据采集系统及方法与制造工艺
- 织机数据采集系统的制造方法与工艺
- 一种基于V/F的数据采集系统的制造方法与工艺
- 基于云平台的车载人体健康数据采集系统以及健康监控方法与流程
- 多通道数据采集处理系统的制造方法与工艺
- 监控和数据采集系统及其数据设计方法与流程
- 一种数据采集终端、系统和方法与制造工艺
- 一种基于Hilscher的可信数据采集系统和方法与制造工艺
- 一种政务数据采集共享系统与方法与制造工艺
- 一种基于LabVIEW和声卡的同步数据采集系统及采集方法与制造工艺
- 一种超低功耗基于无线传输的数据采集系统及采集方法与制造工艺
- 一种基于LabVIEW和声卡的同步数据采集系统及采集方法与制造工艺
- 一种超低功耗基于无线传输的数据采集系统及采集方法与制造工艺
- 一种高招大本数据采集系统及方法与制造工艺
- 一种运动数据采集系统的制造方法与工艺
- 一种安全可靠的数据采集系统的制造方法与工艺
- 一种棚室环境数据采集系统的制造方法与工艺
- 一种面向机械故障监测的无线传感网络数据采集和传输装置的制造方法
- 一种用电量采集和传输装置的制造方法
- 检测杯数据采集仪的制作方法
- 一种用于磁共振视觉传输的信号采集电路的制作方法
- 一种可将电极信号转化为数字信号的电极的制作方法
- 直立式带数据采集触发信号传输功能的防盗器的制造方法
- 电能表数据采集仪的制作方法
- 一种带id识别功能的数据采集传输设备的制造方法
- 无线智能温度采集传输仪的制作方法
- 燃气轮机状态数据采集仪的制作方法
- 数据采集装置的制造方法
- 一种高压电输电线寿命监测系统的制作方法
- 数据收集方法
- 一种计算机安全监控装置的制造方法
- 一种低功耗智能数据采集箱的制作方法
- 一种新型的无线动态数据采集箱的制作方法
- 井场数据采集控制箱的制作方法
- 一种多角度光伏数据采集箱的制作方法
- 一种数据采集装置和一种数据采集箱的制作方法
- 一种海冰监测数据采集箱的制作方法