一种基于Spark的旅游兴趣推荐系统及推荐方法与流程
本发明属于旅游技术领域,具体涉及一种基于spark的旅游兴趣推荐系统,本发明还涉及利用上述推荐系统进行推荐的方法。
背景技术:
目前,随着生活水平的提高,人们在满足物质需求的基础上,更加注重精神需求,但是,目前旅游景点商业化和旅行团跟团游存在的强制消费以及无自由时间活动等问题,使得消费者无法享受当地文化中的建筑之美,文化之美,餐饮之美。而且,目前的旅游消费体系中忽略了当地大学生的导游作用,通过私人定制旅游系统,有利于当地大学生通过兼职导游解决生活来源的问题,有利于大学生带领消费者体验纯正的当地文化,不再盲目聚集。在当前大数据的时代背景下,信息过载是消费者面临的重要问题之一,如何帮助游客在海量的数据集中获取自己不明确和难以表达的需求,筛选到满意的大学生导游是目前面临的主要问题。
在旅游推荐系统中面临的主要挑战是:数据稀疏性、冷启动以及多样性和新颖性等问题。当采用单一的推荐算法如svd算法会存在冷启动以及维度高,计算复杂等问题,基于人口统计学的推荐方法粗糙不准确。这些推荐算法都有自己的特点和适用场景,但都无法面对复杂的旅游推荐场景。为了充分利用各种数据提供的信息,保证推荐的准确性、多样性、新颖性,旅游推荐中采用并行混合推荐算法。
传统的推荐算法运行在单机环境中,其性能受到限制,使得分析计算效率低下,存储空间扩展性能不足,为了快速响应用户的需求,推荐系统需要大数据处理的能力。目前这一领域的框架很多,其中spark是最新一代的计算框架,大数据处理能力很强,将spark用于大数据的离线和在线计算将大大提高推荐系统的运行效率。
技术实现要素:
本发明的目的是提供一种基于spark的旅游兴趣推荐系统,解决了现有推荐算法分析计算效率低下、存储空间扩展性不足的问题。
本发明的另一个目的是提供利用上述推荐系统进行推荐的方法。
本发明所采用的第一种技术方案是,一种基于spark的旅游兴趣推荐系统,包括:
数据仓库模块,用于存储数据;
数据收集模块,将用户交互界面的数据进行收集,将收集到的数据存储到数据仓库模块中;
推荐引擎组模块,从数据仓库模块中提取数据,每个引擎都有自己的推荐策略;
结果处理模块,对推荐引擎组模块输出的结果按照权重统一起来,并将最终的结果展示给游客;
评估模块,对推荐引擎组模块的每一个引擎针对准确度和多样性进行评估,以便确定各个引擎的使用场景;
引擎管理模块,根据评估模块的结果,动态的增加、删除推荐引擎,确定各个引擎的权重;
用户反馈处理模块,将用户交互界面的用户反馈数据收集,并将收集到的反馈数据发送至数据仓库模块。
本发明第一种技术方案的特点还在于:
推荐引擎组模块包括三个推荐引擎,分别是:
基于内容的推荐,利用了大学生导游描述文件;
基于人口统计学的推荐,利用了游客描述文件;
基于svd的推荐,利用了游客评分文件;
三个推荐引擎之间采用模块化设计,根据情况线性添加、删除及实时的调整推荐系统的权值分布。
每一个推荐引擎都分为两部分,离线计算模块和在线计算模块。
推荐引擎的离线计算模块处理数据量和计算量较大的原始数据,采用spark分布式计算框架,供在线计算时使用。
推荐引擎的在线计算模块与具体的推荐目标相关,计算量不大,在离线计算的基础上,以最快的速度给出推荐结果。
本发明所采用的第二种技术方案是:采用一种基于spark的旅游兴趣推荐系统的推荐方法,数据收集模块从用户交互界面获取用户数据user.dat、大学生导游数据student.dat、用户打分记录rating.dat存储到数据仓库模块,用户反馈处理模块从用户交互界面收集反馈数据发送给数据仓库模块;数据仓库模块包括原始数据层、离线中间层、推荐结果层,原始数据层将数据集中的数据抽象后封装,以prequet文件的形式存储于hdfs中以供推荐引擎组模块调用;离线中间层基于原始数据层,离线中间层是将各个推荐引擎离线部分产生的中间计算结果存储在数据仓库中,与具体的推荐对象无关,目的是先提前计算好以便供推荐引擎组模块在线计算使用;推荐结果层是各个推荐引擎基于离线中间层数据个性化推荐的结果数据存储于内存中;结果处理模块将推荐结果层中存储的数据过滤排序后直接返回给用户交互页面;评估模块对推荐引擎组模块的推荐结果的准确性、新颖性进行评估,根据评估的评估模块的结果,引擎管理模块动态的增加、删除推荐引擎,确定各个引擎的权重,以便获取需要的准确性、新颖性信息。
本发明所采用的第二种技术方案的特点还在于:
推荐系统中利用了数据集的三个文件:
①user.dat,用于描述用户信息,用来构造人口统计学的推荐,每条记录的数据格式设置为:
userid::gender::age::occupation::hobby
其中occupation和hobby被数字字典化;userid是指用户id,gender是指用户性别,age是指用户年龄,occupation是指用户职业,hobby是指用户兴趣;
②student.dat,用于描述大学生导游信息,用来构造基于内容的推荐,文件中每行的数据格式为:
studentid::gender::age::university::hobby
其中studentid是指学生导游id,gender是指学生导游性别,age是指学生导游年龄,university是指学生导游学校,hobby是指学生导游兴趣;
③rating.dat,用于描述用户打分记录,提供了用户行为信息,用来构造基于svd的推荐,文件中每条记录的数据格式为:
userid::studentid::rating::time
userid是指用户id,student是指学生导游id,rating是指用户对学生导游的评分,time是指用户对学生导游评分的日期。
数据仓库模块中数据仓库表的具体实现为:
①设计字符串schema;
②将上述字符串转化为spark能处理的schema对象,并给每一个字段分配类型;
③构造原始数据rdd-dataset_rating、dataset_user、dataset_student,这是对原始文件rating.dat、user.dat、student.dat的抽象,用于分布式抽取其中的数据进行处理;
④构建rowrdd,将上述dataset_rating、dataset_user、dataset_student中的每一条数据处理得到结构化记录;
⑤将rowrdd与shema对象绑定并存储到hdfs中,将最终产生的parquet文件存储在数据仓库模块中。
推荐引擎组模块中三个推荐引擎包括两部分:离线计算和在线计算;
离线计算
使用sparksql从数据仓库模块中读取用户表记录,构造rdd(row),其中每一行是用户信息,将rdd(row)进行笛卡尔积操作,得到rdd(row1,row2),其中row1和row2包含了rdd(row)中任意两行的组合,然后对rdd(row1,row2)中每一行的两个row对象进行相似度计算,得到rdd(user1,user2,sim),最后将此rdd持久化存储到数据仓库模块中;
在线计算实现了两个基本的推荐:评分预测和top-n推荐
评分预测的入口参数如下:
inut(score)=(user,student)表示用户给大学生导游的打分;
top-n推荐
评分预测入口参数如下:
input(top-n)=(user)表示给用户推荐n个可能感兴趣的导游;
评分预测的具体步骤为:
①从数据仓库模块中选择与目标用户距离小于阈值的用户,得到rdd(user,sim),每一条记录表示与目标用户距离为sim的user;
②从原始数据层rating_base表中选出选择过目标导游的所有用户以及评分,得到rdd(user,rating);
③将前两步得到的rdd按照user进行join算子操作,得到rdd(user,(rating,sim)),其中user是所有选择过导游,且与目标用户距离小于阈值的用户;
④对上一步中的rdd进行map操作,交换顺序rdd(sim,(user,rating)),并按照sim由小到大的顺序排序,按照相似度排名取前k个;
⑤计算打分:
score=∑i∈r(sim/sim_all)*ratingi
其中i表示列表中的项,r是所有的记录,sim_all是列表中用户相似度的和;
最终的打分为推荐引擎估算目标用户对目标大学生导游可能的打分;
top-n推荐的具体步骤为:
①在评分预测中已经得到与目标用户相似的用户及距离rdd(user,sim),其中此距离要小于阈值,高于此阈值的被删除;
②由rating_base表得到rdd(user,(student,rasting)),与上一步中的rdd进行join操作,得到rdd(user,((student,rating),sim));
③将上一步得到的rdd进行groupbykey算子操作,得到rdd(user,iterable[((student,rating),sim)]),表示与目标用户距离为sim的user,其已经选择过的所有大学生导游及评分记录。然后将该rdd进行map得到rdd(sim,(user,iterable[student,rating])),然后将sim从大到小进行排序,取相似度最高的k个人;
④根据上一步取出的记录进行flatmap操作,得到rdd(student,score1),表示导游的推荐度为score1:
score1=sim*(rating-2.5)
然后根据该大学生导游的推荐度,对其中的记录进行reducebykey操作,按照student进行推荐度叠加,进一步得到rdd(student,score2);
将rdd(student,score2)按照score2由大到小排序,选取n个值,则为最终的推荐结果。
结果处理模块对推荐结果的处理具体步骤为:
首先对推荐引擎内进行标准化评分,即组内最高评分,然后将所有的评分与权值相乘,从得到的结果进行排序,得到最终的推荐结果:
norm(i,s)=(s/smax)*λi
其中,norm(i,s)表示推荐引擎i输出的结果集中s评分的标准化结果,smax表示该引擎推荐结果的最高分,λi表示该引擎的权重;
在初始推荐中设定每个引擎平均分配权值为0.33;
权值的调整是根据游客对筛选导游的行为设定的,不同的游客有不同的倾向,根据用户的偏好、季节、兴趣的变化等合适的调整权值,从而体现个性化的推荐。
本发明的有益效果是:本发明一种基于spark的旅游兴趣推荐系统及推荐方法,①设计实现一个高效的数据仓库,作为原始数据及推荐引擎离线计算结果的数据仓库,该仓库能够大大提高推荐系统离线及在线计算效果;②基于spark编程模型通过实现三个推荐算法的并行化,进一步实现了三个推荐引擎,使得这些引擎能够很好地与底层数据仓库融合,基于spark的设计大大减少了离线及在线计算时间,同时,推荐算法的并行化设计可以解决新注册用户的冷启动问题、数据稀疏问题以及确保推荐结果的新颖性、多样性;③通过这种并行化混合推荐模型,统一各个推荐引擎的结果,并且根据游客的选择自动调整各引擎的权重,从而实现更加个性化的推荐。
附图说明
图1是本发明旅游兴趣推荐系统的整体架构图;
图2是本发明旅游兴趣推荐系统中推荐引擎组模块的框架图。
图中,1.数据仓库模块,2.数据收集模块,3.推荐引擎组模块,4.结果处理模块,5.评估模块,6.引擎管理模块,7.用户反馈处理模块。
具体实施方式
下面结合附图和具体实施方式对本发明进行详细说明。
本发明一种基于spark的旅游兴趣推荐系统,是联系游客与大学生导游的媒介,通过收集静态数据——游客描述信息与大学生描述信息,和动态数据——游客评分记录,推荐系统可以根据不同的情况,向游客推荐他们感兴趣的大学生导游,以一种直观的方式显示在地图上供游客筛选。在本系统中采用多种推荐引擎的混合模型,分别是基于内容法的推荐、基于人口统计学的推荐、和基于svd的推荐,并行处理每个推荐引擎获得推荐结果,确保实现推荐系统的多样性、新颖性。
本发明一种基于spark的旅游兴趣推荐系统,如图1所示,包括:
数据仓库模块1,用于存储数据;
数据收集模块2,将用户交互界面的数据进行收集,将收集到的数据存储到数据仓库模块1中;
推荐引擎组模块3,是整个旅游推荐系统的核心,从数据仓库模块1中提取数据,每个引擎都有自己的推荐策略;
结果处理模块4,对推荐引擎组模块3输出的结果按照权重统一起来,并将最终的结果展示给游客;
评估模块5,对推荐引擎组模块3的每一个引擎针对准确度和多样性进行评估,以便确定各个引擎的使用场景;
引擎管理模块6,根据评估模块5的结果,动态的增加、删除推荐引擎,确定各个引擎的权重;
用户反馈处理模块7,将用户交互界面的用户反馈数据收集,并将收集到的反馈数据发送至数据仓库模块1。
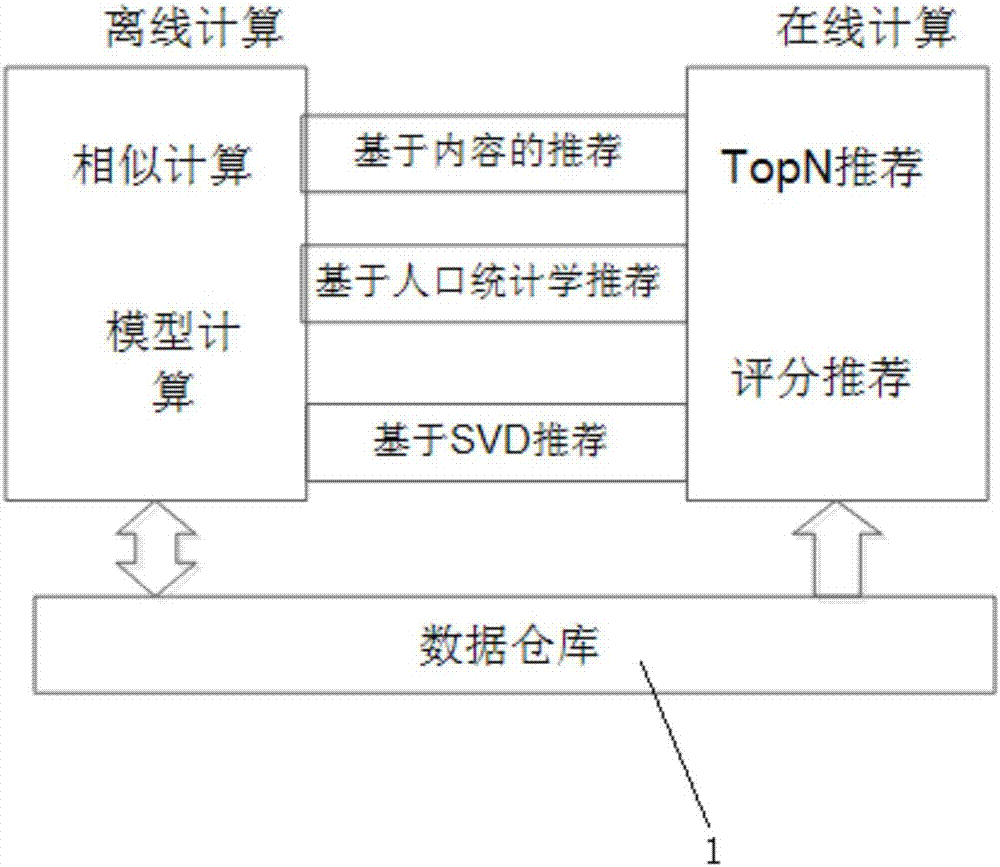
如图2所示,推荐引擎组模块3包括三个推荐引擎,分别是:
基于内容的推荐,利用了大学生导游描述文件;
基于人口统计学的推荐,利用了游客描述文件;
基于svd的推荐,利用了游客评分文件;
三个推荐引擎之间采用模块化设计,根据情况线性添加、删除及实时的调整推荐系统的权值分布,使得最终的推荐结果准确、多样、新颖。
每一个所述推荐引擎都分为两部分,离线计算模块和在线计算模块。离线计算部分主要处理数据量和计算量较大的原始数据,采用spark分布式计算框架,供在线计算时使用。在线计算与具体的推荐目标相关,计算量不大,在离线计算的基础上,以最快的速度给出推荐结果。
推荐引擎的离线计算模块处理数据量和计算量较大的原始数据,采用spark分布式计算框架,供在线计算时使用。
推荐引擎的在线计算模块与具体的推荐目标相关,计算量不大,在离线计算的基础上,以最快的速度给出推荐结果。
采用上述一种基于spark的旅游兴趣推荐系统的推荐方法,数据收集模块2从用户交互界面获取用户数据user.dat、大学生导游数据student.dat、用户打分记录rating.dat存储到数据仓库模块1,用户反馈处理模块7从用户交互界面收集反馈数据发送给数据仓库模块1;数据仓库模块1包括原始数据层、离线中间层、推荐结果层,原始数据层将数据集中的数据抽象后封装,以prequet文件的形式存储于hdfs中以供推荐引擎组模块3调用;离线中间层基于原始数据层,离线中间层是将各个推荐引擎离线部分产生的中间计算结果存储在数据仓库中,与具体的推荐对象无关,目的是先提前计算好以便供推荐引擎组模块3在线计算使用;推荐结果层是各个推荐引擎基于离线中间层数据个性化推荐的结果数据存储于内存中;结果处理模块4将推荐结果层中存储的数据过滤排序后直接返回给用户交互页面;评估模块5对推荐引擎组模块3的推荐结果的准确性、新颖性进行评估,根据评估的评估模块5的结果,引擎管理模块6动态的增加、删除推荐引擎,确定各个引擎的权重,以便获取需要的准确性、新颖性信息。
推荐系统中利用了数据集的三个文件:
①user.dat,用于描述用户信息,用来构造人口统计学的推荐,每条记录的数据格式设置为:
userid::gender::age::occupation::hobby
其中occupation和hobby被数字字典化;userid是指用户id,gender是指用户性别,age是指用户年龄,occupation是指用户职业,hobby是指用户兴趣;
②student.dat,用于描述大学生导游信息,用来构造基于内容的推荐,文件中每行的数据格式为:
studentid::gender::age::university::hobby
其中studentid是指学生导游id,gender是指学生导游性别,age是指学生导游年龄,university是指学生导游学校,hobby是指学生导游兴趣;
③rating.dat,用于描述用户打分记录,提供了用户行为信息,用来构造基于svd的推荐,文件中每条记录的数据格式为:
userid::studentid::rating::time
userid是指用户id,student是指学生导游id,rating是指用户对学生导游的评分,time是指用户对学生导游评分的日期。
数据仓库模块1中数据仓库表的具体实现为:
①设计字符串schema;
②将上述字符串转化为spark能处理的schema对象,并给每一个字段分配类型;
③构造原始数据rdd-dataset_rating、dataset_user、dataset_student,这是对原始文件rating.dat、user.dat、student.dat的抽象,用于分布式抽取其中的数据进行处理;
④构建rowrdd,将上述dataset_rating、dataset_user、dataset_student中的每一条数据处理得到结构化记录;
⑤将rowrdd与shema对象绑定并存储到hdfs中,将最终产生的parquet文件存储在数据仓库模块1中。
推荐引擎组模块3中三个推荐引擎包括两部分:离线计算和在线计算;
离线计算
使用sparksql从数据仓库模块1中读取用户表记录,构造rdd(row),其中每一行是用户信息,将rdd(row)进行笛卡尔积操作,得到rdd(row1,row2),其中row1和row2包含了rdd(row)中任意两行的组合,然后对rdd(row1,row2)中每一行的两个row对象进行相似度计算,得到rdd(user1,user2,sim),最后将此rdd持久化存储到数据仓库模块1中;
在线计算实现了两个基本的推荐:评分预测和top-n推荐
评分预测的入口参数如下:
inut(score)=(user,student)表示用户给大学生导游的打分;
top-n推荐
评分预测入口参数如下:
input(top-n)=(user)表示给用户推荐n个可能感兴趣的导游;
评分预测的具体步骤为:
①从数据仓库模块1中选择与目标用户距离小于阈值的用户,得到rdd(user,sim),每一条记录表示与目标用户距离为sim的user;
②从原始数据层rating_base表中选出选择过目标导游的所有用户以及评分,得到rdd(user,rating);
③将前两步得到的rdd按照user进行join算子操作,得到rdd(user,(rating,sim)),其中user是所有选择过导游,且与目标用户距离小于阈值的用户;
④对上一步中的rdd进行map操作,交换顺序rdd(sim,(user,rating)),并按照sim由小到大的顺序排序,按照相似度排名取前k个;
⑤计算打分:
score=∑i∈r(sim/sim_all)*ratingi
其中i表示列表中的项,r是所有的记录,sim_all是列表中用户相似度的和;
最终的打分为推荐引擎估算目标用户对目标大学生导游可能的打分;
top-n推荐的具体步骤为:
①在评分预测中已经得到与目标用户相似的用户及距离rdd(user,sim),其中此距离要小于阈值,高于此阈值的被删除;
②由rating_base表得到rdd(user,(student,rasting)),与上一步中的rdd进行join操作,得到rdd(user,((student,rating),sim));
③将上一步得到的rdd进行groupbykey算子操作,得到rdd(user,iterable[((student,rating),sim)]),表示与目标用户距离为sim的user,其已经选择过的所有大学生导游及评分记录。然后将该rdd进行map得到rdd(sim,(user,iterable[student,rating])),然后将sim从大到小进行排序,取相似度最高的k个人;
④根据上一步取出的记录进行flatmap操作,得到rdd(student,score1),表示导游的推荐度为score1:
score1=sim*(rating-2.5)
然后根据该大学生导游的推荐度,对其中的记录进行reducebykey操作,按照student进行推荐度叠加,进一步得到rdd(student,score2);
将rdd(student,score2)按照score2由大到小排序,选取n个值,则为最终的推荐结果。
结果处理模块4对推荐结果的处理具体步骤为:
首先对推荐引擎内进行标准化评分,即组内最高评分,然后将所有的评分与权值相乘,从得到的结果进行排序,得到最终的推荐结果:
norm(i,s)=(s/smax)*λi
其中,norm(i,s)表示推荐引擎i输出的结果集中s评分的标准化结果,smax表示该引擎推荐结果的最高分,λi表示该引擎的权重;
在初始推荐中设定每个引擎平均分配权值为0.33;
权值的调整是根据游客对筛选导游的行为设定的,不同的游客有不同的倾向,根据用户的偏好、季节、兴趣的变化等合适的调整权值,从而体现个性化的推荐。
- 离群点检测方法和装置与流程
- 基于数据流结构的海量网络数据...
- 一种基于知识分类的多屏知识可...
- 用户违章通知系统和车辆违章通...
- 一种渔业大数据检测分析方法及...
- 一种自行车定位追踪方法及系统...
- 基于多任务学习的对话策略在线...
- 基于保序子矩阵和频繁序列挖掘...
- 一种VNF包以及其引用的镜像...
- 一种基于主题模型和遗忘规律的...
- 还没有人留言评论。精彩留言会获得点赞!