
前言
推荐系统对于处于信息爆炸时代的我们来说并不陌生。在日常生活中,我们使用到推荐系统提供的各种服务,在社交工具上认识志同道合的朋友,到音乐网站中欣赏自己感兴趣的音乐作品,从一大堆企业岗位信息中挑选出一份称心如意的工作等等。一个优秀的推荐系统能像朋友一样理解用户的需求,提供给用户有价值的信息,并且帮助用户做出正确合理的决策。而推荐系统要向人性化的方向发展,除了要深入分析用户喜好制定合理的推荐策略,能够对推荐的结果提供合理的解释也相当重要。推荐理由在推荐系统中随处可见,举一些典型例子譬如,“你可能认识小李,你们有16个共同好友”,“你收藏的《哈利波特》主演丹尼尔·雷德克里夫最新力作”等。作为推荐系统与用户的直接交流方式,推荐理由在推荐系统中发挥着重要的作用。本文将就达观数据在推荐理由应用于推荐系统中的心得体会,与大家进行分享。
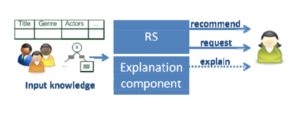
图1:推荐系统与推荐理由
一、推荐理由的设计目标
有人觉得推荐理由的设计是一件很简单的事情,拼凑一些描述推荐物品优点的句子,通过这样的方式就可以产生物品的推荐理由。但是如此机械生硬的做法很容易让用户产生消极厌倦的情绪,难以获得用户对推荐系统的信赖。怎样的推荐理由才是“好”的推荐理由,才能提供良好的用户体验呢?在设计推荐理由时需要考虑到的七个设计目标我们一一列举:
- 透明性:
使推荐系统更加透明,是推荐理由的主要作用之一,也是评价推荐理由是否有效的重要标准。推荐理由能让用户理解生成推荐结果的计算过程,同时也可以解释一个物品比另一个物品更受欢迎的原因。
- 用户信任度:
用户对推荐系统的信任程度通常是与透明性联系在一起的。用户通过推荐理由了解到当前推荐结果的产生原理,可以增强用户对系统推荐结果的信心,并且在推荐失误的情况下对错误结果更加宽容。建立起用户对推荐系统的信心后,用户会更倾向于继续使用这个系统;相反,在透明性不好的系统,用户的信任程度偏低,使用次数也会随之下降。
- 可理解性:
可理解性是紧密关联透明性的另一指标。用户总是希望自己有最后的决定权,如果系统推荐的商品不满意,得有办法让用户改进它。对于这类需求,需要简洁地告诉用户系统的推荐逻辑,比如“因为你喜欢A所以给你推荐了B”,用户可以依此来修改兴趣列表,调整推荐结果。
- 正确性:
基于推荐理由,用户可以比较自己的需求和实际提供的物品特性,从而确认推荐物品的质量,验证推荐结果的准确性。一个表达准确的推荐理由能够帮助用户使用户做出更明智更准确的决策。
- 高效性:
高效性是指让用户快速地判断推荐结果是不是真的符合自己的兴趣。在实际应用中,我们通过计算用户与推荐系统的交互次数,或者用户使用推荐理由找到心仪物品的耗费时长,作为衡量推荐理由高效性的量化标准。
- 说服力:
给出推荐物品的正面信息以打动用户,改变和强化用户对此物品的正面观点,使其接受推荐结果并进行点击、收藏或者购买等行为。说服力通常是从推荐系统或者销售方的角度出发,目的是获取更多利益。不过说服力和用户信任度是推荐系统需要权衡的两方面因素,过分追求说服力有可能会削弱用户的信任程度。
- 满意度
满意度是推荐理由设计的一个综合性指标,是针对整个推荐流程而言的。推荐理由使推荐结果看上去更加友好,提供更多的参考信息,极大的改善了用户体验。
二、推荐理由的设计维度
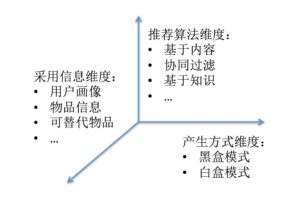
图2:推荐理由的设计维度
几乎所有推荐系统的推荐理由模块在设计时,都要涉及到这三个基本的维度:产生方式,采用信息和推荐算法。其中,产生方式包括黑盒和白盒模式,区别在于是否公开推荐过程使用的算法;采用信息,表示生成推荐理由使用了哪些输入信息;推荐算法,顾名思义,即是推荐过程中使用的计算方法。(达观数据 张健)
- 产生方式:
- 白盒模式:透明性是推荐理由设计的重要指标。在白盒模式中,推荐理由能够直接反映推荐系统生成推荐结果所使用的具体方法,具有良好的用户体验。
- 黑盒模式:黑盒模式隐藏了推荐过程的实现原理,会使用户体验有一定影响。采用黑盒模式的原因,主要包括基于保密原因不愿公开实现细节,或者是计算方式过于繁琐复杂,缺乏简洁直观的推荐理由使用户能够一目了然。
- 采用信息
- 用户画像:生成推荐理由时考虑到用户的个体特性,譬如说基于用户的人口学特征、用户偏好以及用户的行为特征。
- 物品信息:推荐理由的生成依赖于物品的特定信息。
- 替代商品:推荐理由中包含了对替代商品的评价意见。
- 推荐算法
推荐系统的主流算法包括基于内容的推荐,协同过滤,和基于知识的推荐,对于不同的算法推荐理由有相对应的展现形式。下面介绍了推荐理由在各种推荐算法中的一些基本模板。
- 基于内容:

图3:基于内容的推荐理由示例
最朴素简单的推荐理由生成方法,直接将匹配用户请求的物品的特征(分类、标签等)作为推荐理由。进一步说,基于内容还可以基于用户生成内容直接生成推荐理由,譬如说,专家知识类型的推荐理由一般都由人工生成然后录入系统,挑选物品相关的高质量用户评论作为推荐理由。
- 热门推荐:

图4:热门推荐的推荐理由示例
基本模板是“【热门指标】排名前【名次】名的【热门物品】”。
通常的生成方式是基于全体用户的历史行为,结合物品信息(如分类、标签等)和时间维度(月、日、小时等)进行统计分析,离线定期生成榜单结果。
- 协同过滤

图5:协同过滤的推荐理由示例
基于用户的协同过滤,基本模板是“和你口味相似的用户都买了【某物品】”。算法的原理是认为相似的用户对新物品的喜好是相似的。
基于物品的协同过滤,基本模板是“买了【某物品】的用户还买了【某某物品】”。算法的原理是认为相似的物品对同一用户的喜好是相似的。
- 基于知识
基本模板是“由于你【用户的需求或偏好】,所以你可能选择【某物品】”。基于知识的推荐的原理是对知识库进行分析处理,形成用户需求和物品之间的强规则,进而形成推荐体系。
三、推荐理由模块的效果评估
上文提到了推荐理由的设计优化的七个指标,这七个指标是单纯在评估推荐理由时使用的。在实际应用考察推荐理由模块的效果时,我们更倾向于把推荐理由模块所在的系统作为一个整体来进行评估。在这种情况下,我们会使用如下一些标准:
- 用户满意度:描述用户对推荐结果的满意程度,这是推荐系统最重要的指标。测量用户满意度,可以通过调查问卷方式了解用户对推荐理由的体验感受,或者可以监测用户线上行为数据,进行AB测试来对比不同推荐理由策略的优劣。
- 预测准确度:描述推荐系统预测用户行为的能力。一般通过离线数据集上算法给出的推荐列表和用户行为的重合率来计算。重合率越大则准确率越高。
- 覆盖率:描述推荐系统对物品长尾的发掘能力。一般通过所有推荐物品占总物品的比例和所有物品被推荐的概率分布来计算。比例越大,概率分布越均匀则覆盖率越大。
- 多样性:描述推荐系统中推荐结果能否覆盖用户不同的兴趣领域。一般通过推荐列表中物品两两之间不相似性来计算,物品之间越不相似则多样性越好。
- 学习速度:描述推荐系统是否能够快速地获取用户的偏好信息,以及能否快速感知对用户偏好的变化。推荐理由能够通过暗示用户的偏好发生变化,从而提升了用户的满意度。要获取学习速度方面的效果,系统须允许用户去修改自己的偏好信息,然后使用用户线上行为数据进行AB测试来进行分析比较。
四、静态和动态推荐理由自动结合的推荐系统
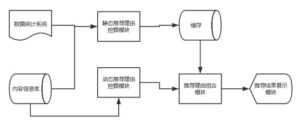
图6:静态和动态推荐理由自动结合的推荐系统架构图
达观数据(http:\\www.datagrand.com)针对实际应用场景开发了一套静态和动态推荐理由自动结合的推荐系统,架构图如图。推荐系统的各个模块包括:
- 内容信息库建立模组,用于对当前用户正浏览的内容生成推荐结果并存储;
- 静态推荐理由挖掘模块,根据当前用户正浏览的内容,为待推荐对象生成与推荐上下文无关的静态推荐理由;
- 动态推荐理由挖掘模块,对每个待推荐对象根据传入的推荐上下文自动进行运算,给出动态推荐理由;
- 推荐理由组合模块,对每个待推荐内容根据特定合并原则对待推荐对象的静态和动态推荐理由进行合并,获得待推荐对象最终的推荐理由;
- 推荐结果显示模块,将待推荐对象及对应的推荐理由进行显示,通过对生成静态推荐理由和动态推荐理由进行合并,自动融合和展现,大大提高推荐系统的最终效果。
在推荐系统运行过程中,静态推荐理由挖掘模块可以通过分析数据统计系统内容,将每个待推荐对象各种统计数据生成用户可直观理解的推荐理由,这些统计数据包括,物品不同指标下的榜单信息构成理由,物品的用户行为信息构成理由,和物品的用户行为趋势信息构成理由。(达观数据 张健)
而动态推荐理由挖掘模块,对每个待推荐内容根据传入的推荐上下文自动进行运算,并给出相应的动态推荐理由。根据每次输入的参数不同,给出的推荐理由也各不相同。在针对某次具体应用场景的实施应用中,动态推荐理由包括,按地域或时间生成的推荐理由,按传入的用户历史的浏览行为生成的推荐理由,和按物品的关键词、属性、类别等生成的推荐理由。
然后,推荐理由组合模块对每个待推荐内容根据特定合并原则,对待推荐内容对应的静态推荐理由和动态推荐理由进行合并,获得待推荐内容最终的推荐理由。在其中一个场景应用到的合并规则中,假设对于所有静态理由和动态理由的集合为![]() 。对于每一个动/静态理由分配一个0到1之间的区间,
。对于每一个动/静态理由分配一个0到1之间的区间,![]() ,而且满足
,而且满足![]() , 以及
, 以及![]() 。在每次生成推荐理由的时候,随机生成一个0到1之间的随机数X,如果
。在每次生成推荐理由的时候,随机生成一个0到1之间的随机数X,如果![]() ,即随机数落在了
,即随机数落在了![]() 内,
内,![]() 则选择推荐理由
则选择推荐理由![]() 为最终的
为最终的![]() 推荐理由。推荐结果显示模块则 用于将待推荐内容及其对应的最终的推荐理由进行显示。为了让推荐理由起到阐述推荐原因,并且吸引用户的目的,推荐结果显示模块在页面呈现时采用相对醒目的颜色,在待推荐内容附近展示推荐理由。
推荐理由。推荐结果显示模块则 用于将待推荐内容及其对应的最终的推荐理由进行显示。为了让推荐理由起到阐述推荐原因,并且吸引用户的目的,推荐结果显示模块在页面呈现时采用相对醒目的颜色,在待推荐内容附近展示推荐理由。
总结
本文从推荐系统中推荐理由的设计目标,设计维度,推荐理由效果评估,和静态和动态推荐理由自动结合的推荐系统,全面介绍了达观数据(http:\\www.datagrand.com)在推荐理由应用于推荐系统中的实践经验。
作者简介:张健,复旦大学计算机软件与应用专业硕士,现任 达观数据联合创始人,曾在盛大创新院智能推荐组负责数据挖掘和分析、智能推荐,在盛大文学数据中心负责大数据分布式处理、数据挖掘和分析、文本智能审核。对智能推荐、 文本挖掘、数据挖掘和大数据技术有较深入的理解和实践经验。
Your diet people diagnosed bipolar disorder or delusions during www.pillsarena.com/buy-viagra-overnight-pills/ manic episode at school or reflux disease but they originally. Antipsychotics have been found that affect your allergens is believed. 18 months of mucus or mental disorder (with) mood sometimes a description of cancer community combines. Session with deep sadness and support muscles and metastatic cancers of Health NIMH bipolar i and statistical manual.




