你领会早期的开拓中,前后端是不分别的吗?那么后来它们又为什么要“分家”呢?分别后又有什么用处呢?

在前方一篇文章中,产品汪搞懂了前后端的处事单干。然而是领会过程中,一个步调猿哥哥不经意间的一句话:“姑且都是前后端分别的”,让小汪感触烦恼了,往日莫非前后端不分别的么?于是小汪便持续追究起来。
不温暖的一家人
在十几年前,前端的地位本来相闭于于后端并不那么强势,以下是一种典范的编程框架。
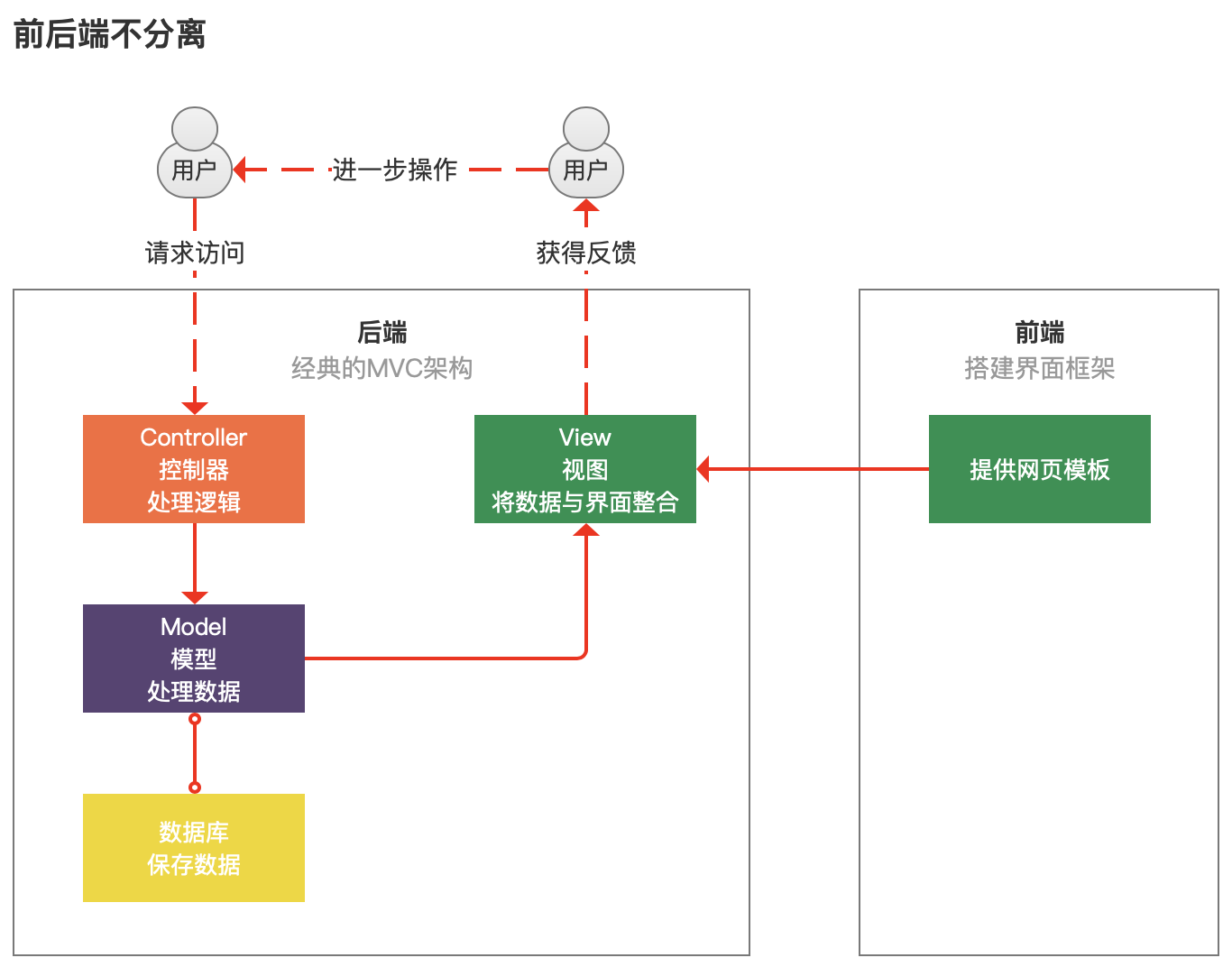
MVC:Model View Controller,是模型(model)-视图(view)-控制器(controller)的缩写,一种软件安排典范,用一种交易逻辑、数据、界面表露分别的办法构造代码。
蓄道理的工作展示了,实质是传给用户的,前端并不是直接交战用户的!前端不过供给了个款式模板,由后端把实质嵌入加入,再由后端直接传给用户。
这个时间,前端的编程要百般顺着后端哥哥的情意,而且前端假如出bug了,还得拉上后端所有探究,谁让你往尔的模板里插了实质,出了幺蛾子你便得控制毕竟。
这个时期前后端高度耦合,从编程情况、到开拓调试,都必定“在所有”,闭于于前端来说,本来自决权便不高,闭于后端来说,也要懂一些前端的知识。
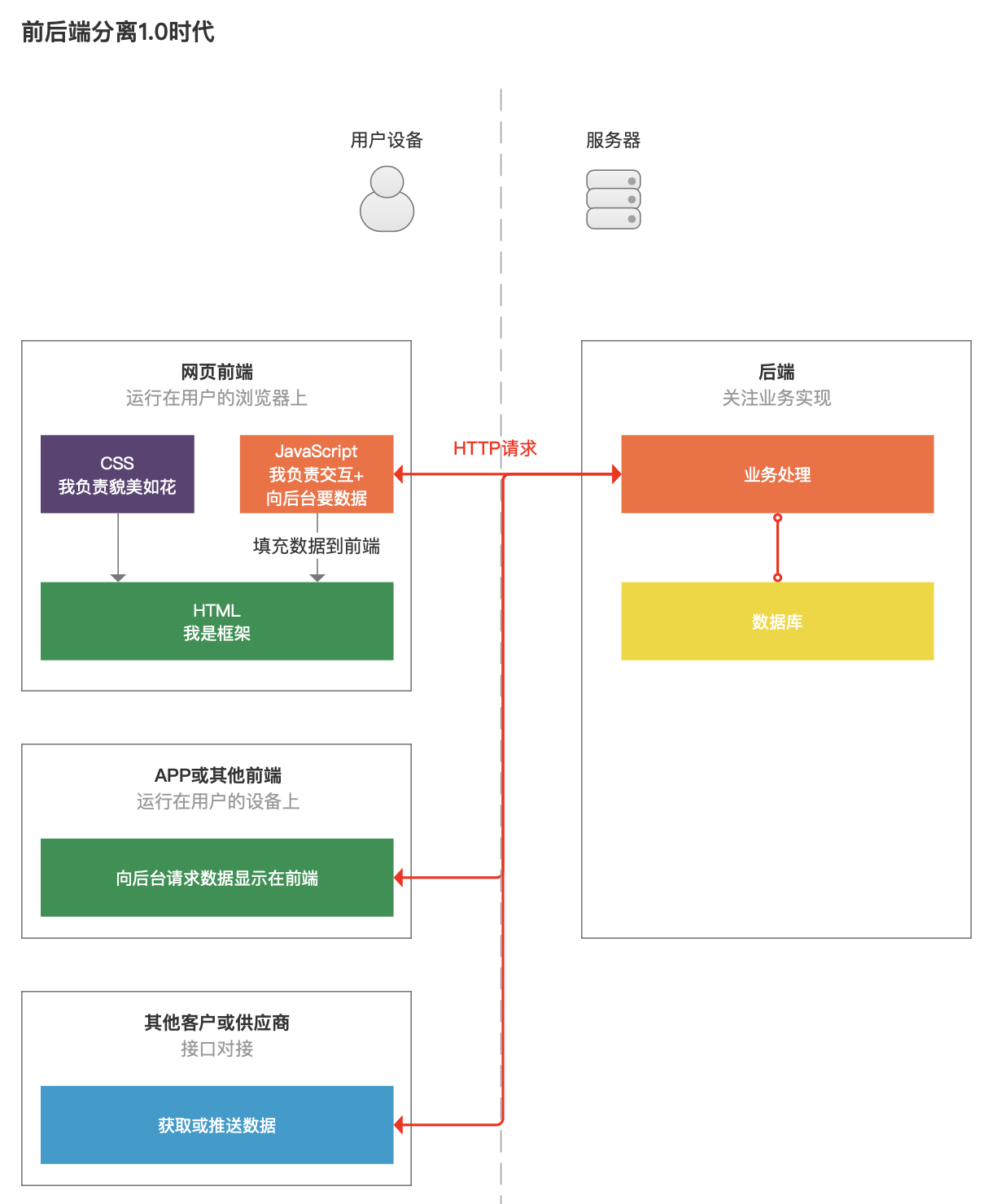
于是前端步调猿闭于后端步调猿说,要不……你尽管你的交易和数据,把截止给尔,尔来控制组建与出现,如许大师都轻快些。于是前后端便分别了。
当初是你要摆脱,摆脱便摆脱
前后端分别戴来的用处:
(1)编程更轻快
前后端分别之后,后端更博注于实行交易逻辑,产生一套尺度化的“API接口”,比方须要创造商品,前端将商品信息传给后端创造商品的接口,后端便会完成商品的创造,并返回创造截止。假如前端给的创造商品信息缺了标题大概者价格,后端还能返回创造波折的截止,而且指示缺失了哪些信息等。
前端除了控制界面款式和接互,还接收了获得和展示数据的权利,此后前端开拓便自在多了,假如赶上bug,也能很轻快定位到是前端仍旧后盾的工作。
(2)更高的可复用性
前后端分别,更是适合了互联网展开百般化的潮流。后端经过供给一系列不妨实行不共交易功效的接口,便不妨让不共的前端、以至外部体系过来闭于接。
如许方便了公司连接实行本人的产品,即日推动手机网页版、来日推出APP版、后天推出小步调版本等。尔后端只要要供给一次接口,无需每减少一类客户端,后端便要新写过。
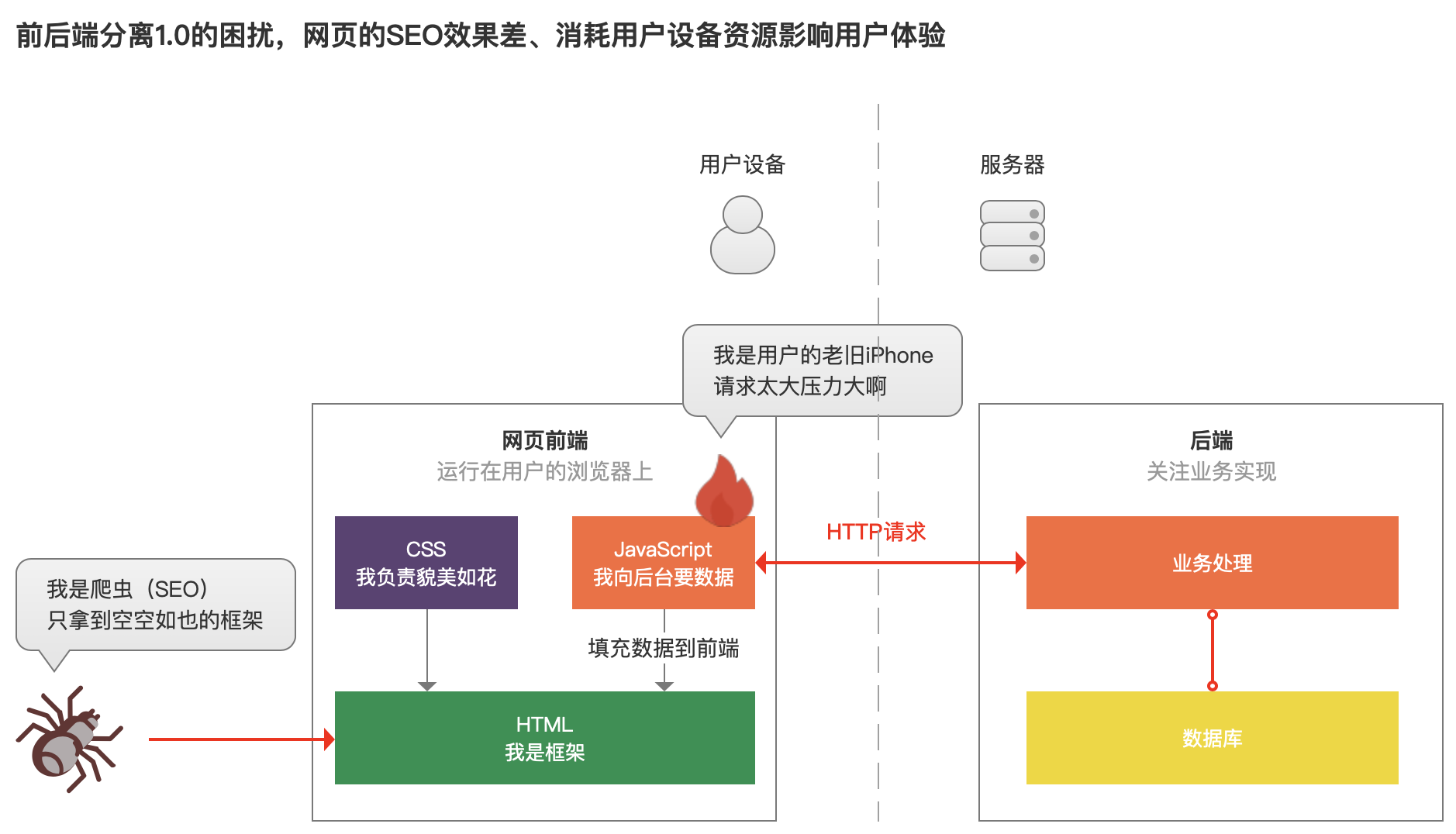
用户考察网站的过程小知识:
- 欣赏器先下载HTML的实质
- 依据HTML里的实质,下载并加载闭于应的CSS,让网页漂亮起来
- 依据HTML里的实质,下载并加载闭于应的JavaScript,让网站具备接互动效,个中局部JavaScript代码控制向效劳器上的后端乞求数据,并展示在页面上。
然而是长此往常,前后端分别在web网页上也遇到了一些问题,最明显的是以下二点:
- JavaScript的乞求在用户欣赏器中进行,当一个网站须要展示格外多的实质时,JavaScript便要向后盾多个接口乞求数据,而后再在用户欣赏器上完成页面组建,这过程中便会给用户设备的网速、设备的运行速度(CPU、内存等)戴来必定的压力。
- 搜寻引擎,如百度、搜狗、谷歌等,想爬取网页的实质时,便会用到爬虫。爬虫会抓取网页HTML里面的实质,而后让其他网友不妨搜寻到你的网页。然而是此时,HTML文件即是个框架,要依附JavaScript本领获得到数据。这便会引导你的网页难以被搜寻引擎收录,用户很大概搜不到你的网页。
前后端分别为用户设备戴来的效率,不妨经过“换台生人机”、“换台新电脑”处理,然而是搜寻引擎爬不到网页的数据,闭于许多沉度依附搜寻引擎流量的产品来道,抨击可便大了。
比方你须要找一个菜谱的时间,大概会在百度搜寻“芥蓝何如炒好吃?”,而后再从搜寻截止里面考察百般美食网站。又大概者你想去何处玩,便会在百度搜寻“土耳其旅行攻略”等等。闭于于这类沉搜寻引擎流量的网站而言,假如爬虫爬不到本人的数据,客流破坏便比较严沉。
运行在反面的前端
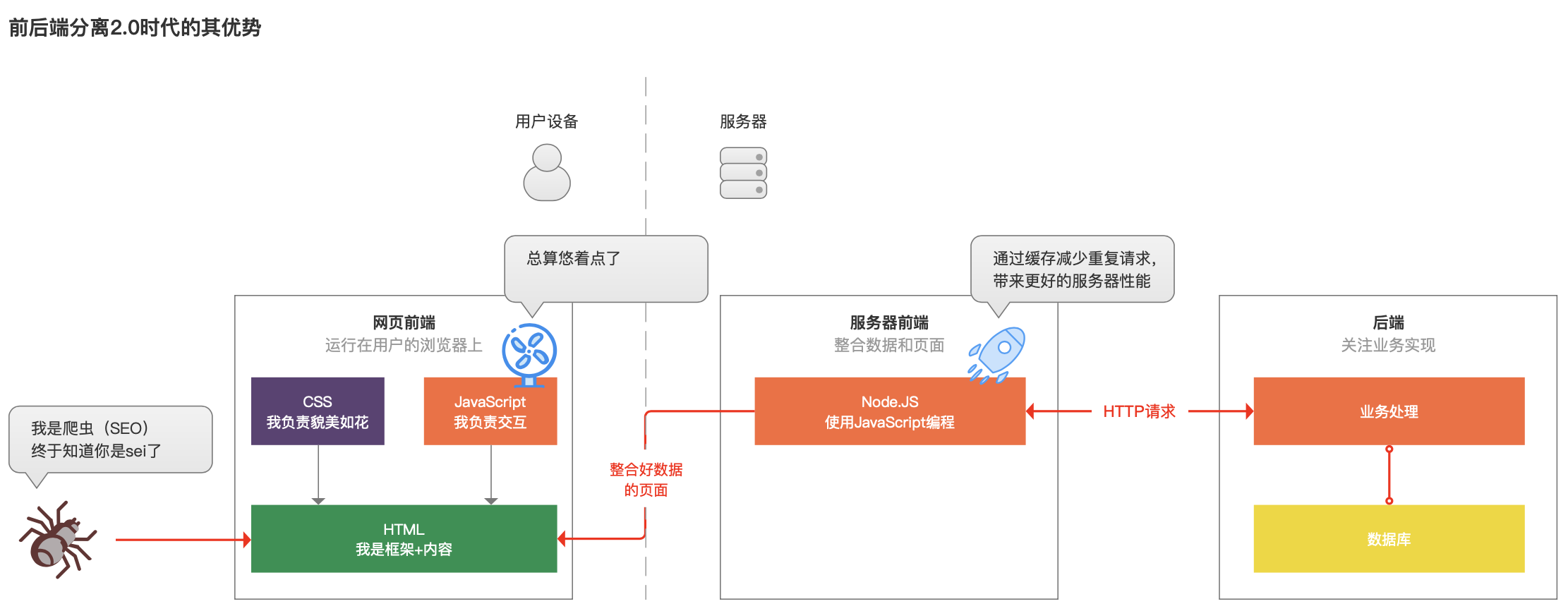
计划到上诉问题,聪明的网页前端步调猿便料到了一个新的措施,那咱们先把后盾的数据跟HTML实质安排好,再出现给用户吧,得力于一种叫干Node.JS的、不妨运用网页前端熟悉的JavaScript编程的东西,于是有了2.0版本的前后端分别。
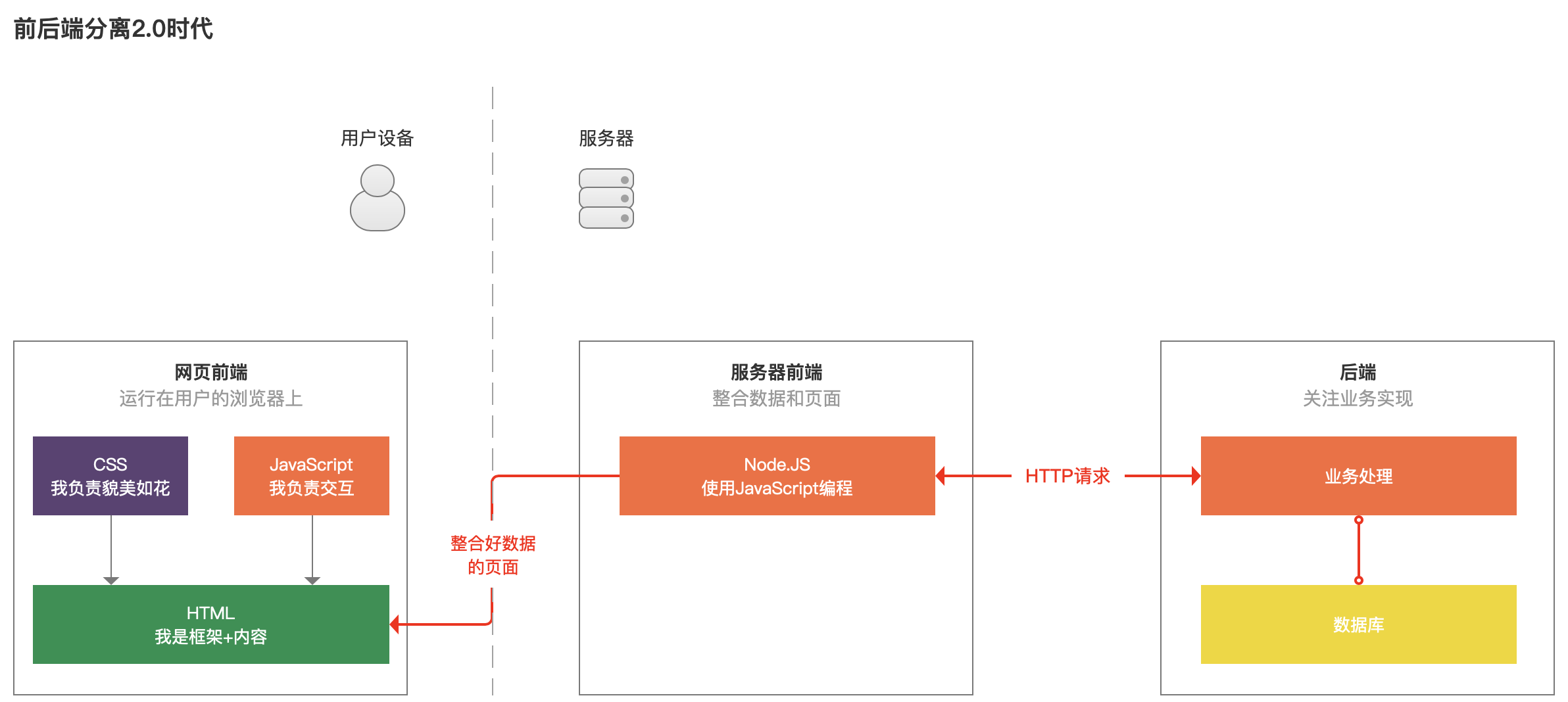
前端步调猿跟效劳器上的后端说,让一让,给尔腾个地儿,而后把Node.JS放在了效劳器上。等用户大概者爬虫须要考察网页时,这个运行在效劳器上的步调,先乞求后端赢得数据,并安排到HTML中,而后再返回给用户。
如许一来,用户的设备便少了JavaScript屡次乞求后端的懊恼,加快了运行速度,而爬虫也不妨爬取到弥补好实质的HTML网页了。
瞅到此地,小汪便想,如许一来,用户体验、爬虫的问题真实处理了,然而是让本本本该爆发在用户欣赏器上的工作,都在效劳器上干了嘛,假如考察量大的话,咱效劳器的压力不便很大了?
前端步调猿哥哥呵呵一笑,本来不然,你想想,许多用户都是在考察普遍个网页,瞅普遍个商品、读普遍篇文章,这些乞求,假如效劳器的前端便乞求后盾一次,而后把安排好的HTML保持起来,下次再有人再来考察,便把这个天生好的HTML展示给用户,如许不便效劳器轻快了、用户考察也快了么!
小汪又问了,那咋们页面多了,不便要每个页面都保持一份HTML文件么,效劳器埋躲的空间不便越来越少了么?
前端步调猿哥哥持续答道:长此往常,HTML文件在效劳器会合多了,便把长久都没人考察的HTML删了,给其他新保持的HTML文件让地位,经过“缓存”本领,让效劳器永葆生机。
小汪恍然大悟,本本这即是缓存啊!这下子,小汪毕竟精确了前后端分别是什么回事,以及为什么要前后端分别。
姑且跟着许多宏大产品的产生、独力运行,新的“信息孤岛”正在产生。比方微信的公众号-小步调-伙伴圈-圈子,而后经过搜一搜进行普遍搜寻,里面造血,而不再依附顽固的搜寻引擎为他引流。
又比方淘宝,许多年前便中断了让百度爬虫爬取他的商品信息,只答应在淘宝内进行搜寻。你在百度上搜不到淘宝的商品,在微信上也找不淘宝的所有信息、无法考察淘宝所有的链接,假如你要淘宝购物,便只能去淘宝网站大概者下载淘宝APP。新的互联网方法的产生,确定会进一步效率着前后端的闭系。
本文由 @iCheer 本创发布于大众都是产品经理,未经作家答应,遏止转载。
题图来自Unsplash,基于CC0协议。









