
本文汇总了SNIP/SNIPER、SSD、空洞卷积、FPN等多尺度图像处理方法,详细介绍了它们的网络结构和实现细节,对大家理解小目标检测很有帮助。
传统的图像金字塔
最开始在深度学习方法流行之前,对于不同尺度的目标,大家普遍使用将原图构建出不同分辨率的图像金字塔,再对每层金字塔用固定输入分辨率的分类器在该层滑动来检测目标,以求在金字塔底部检测出小目标;或者只用一个原图,在原图上,用不同分辨率的分类器来检测目标,以求在比较小的窗口分类器中检测到小目标。经典的基于简单矩形特征(Haar)+级联Adaboost与Hog特征+SVM的DPM目标识别框架,均使用图像金字塔的方式处理多尺度目标,早期的CNN目标识别框架同样采用该方式,但对图像金字塔中的每一层分别进行CNN提取特征,耗时与内存消耗均无法满足需求。但该方式毫无疑问仍然是最优的。值得一提的是,其实目前大多数深度学习算法提交结果进行排名的时候,大多使用多尺度测试。同时类似于SNIP使用多尺度训练,均是图像金字塔的多尺度处理。
SNIP/SNIPER中的多尺度处理
论文地址:https://arxiv.org/abs/1711.08189
代码地址:https://github.com/mahyarnajibi/SNIPER
当前的物体检测算法通常使用微调的方法,即先在ImageNet数据集上训练分类任务,然后再迁移到物体检测的数据集上,如COCO来训练检测任务。我们可以将ImageNet的分类任务看做224×224的尺度,而COCO中的物体尺度大部分在几十像素的范围内,并且包含大量小物体,物体尺度差距更大,因此两者的样本差距太大,会导致映射迁移(Domain Shift)的误差。
SNIP是多尺度训练(Multi-Scale Training)的改进版本。MST的思想是使用随机采样的多分辨率图像使检测器具有尺度不变特性。然而作者通过实验发现,在MST中,对于极大目标和过小目标的检测效果并不好,但是MST也有一些优点,比如对一张图片会有几种不同分辨率,每个目标在训练时都会有几个不同的尺寸,那么总有一个尺寸在指定的尺寸范围内。
SNIP的做法是只对size在指定范围内的目标回传损失,即训练过程实际上只是针对某些特定目标进行,这样就能减少domain-shift带来的影响。
SNIP的网络结构如下图所示:
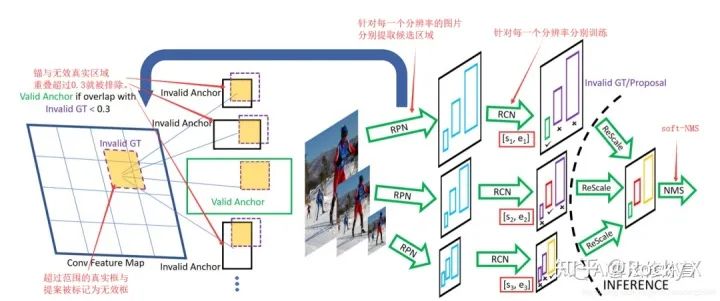
具体的参考资料链接:
[1] https://zhuanlan.zhihu.com/p/93922612
[2] https://blog.csdn.net/woduitaodong2698/article/details/86556206
[3] https://blog.csdn.net/u014380165/article/details/82284128?utm_source=blogxgwz5

评论
沙发等你来抢