随着日历最后一页的最后一格被勾掉的那一刻,这一年的岁月也就算画上句号,这一年的记忆也就开始封存。
在年终的时候,我们总会使用不同的方式,从不同的角度,以不同的媒介来进行全年的总结。
一年三百多天,十二个月,每个月都不同,都会发生具有特点的事情,成为每个月的特定记忆标签,而这一标签的刻画,通常需要有可供计算的历时文本存在,也就是语言学上的历时语料库,这个在现在的新闻平台历时榜单中有直接的体现;
也需要有记忆标签的生成方式,我们可以简单而高效的词云直接刻画,例如,之前文章《NLP文本多样性可视化开源组件大赏:TextGrapher图谱、wordcloud词云、shifterator差异性等项目总结》一文中介绍了多种文本分析的方法。
因此,本文作为对2022年的历史性记忆回顾,以开源项目trending-in-one给出的当前全年历时热点数据,进行词云生成,并按月度为单位,以不同的榜单进行统计呈现,将词云及代表性热点记忆进行客观、真实的展示,供大家一起思考。
这是2022年老刘的最后一篇文章,感谢大家的支持与关注,提前祝大家新年快乐。

一、基于历时热点数据的词云生成逻辑
1、数据来源
开源项目trending-in-one,给出了当前的历时热点数据。包括今日头条热搜、知乎热门视频、知乎热搜榜、知乎热门话题以及微博热搜榜,记录从 2020-11-29 日开始的热搜。每小时抓取一次数据,按天归档。
项目地址:https://github.com/huqi-pr/trending-in-one
2、代码实现逻辑
以当前的几个热点榜单为例,不同的榜单从不同的平台,不同的用户群体和角度对即将过去的2022年进行了总结。
而从文本分析的角度上来说,使用词云的方式进行展示是目前的一种简单而有效的方式。
因此,我们通过每个榜单,以月为单位,收集每个月对应的文本,然后进行分词,并取得其中的名词、动词、形容词、缩略语和成语,并统计其频次,保留前100个词进行展示,最后调用pyecharts的词云展示方法进行html生成。
3、动手实现 我们可以很简单的进行处理,具体代码如下:
# coding = utf-8
import os
import json
import jieba.posseg as pseg
from collections import Counter
from pyecharts import options as opts
from pyecharts.charts import Page, WordCloud
"""
toutiao-search:头条热搜,
zhihu-questions:知乎热门话题
zhihu-search:知乎热搜
zhihu-video:知乎热门视频
weibo-search:微博热搜
"""
def create_docs(cate):
date_dict = dict()
for root, dirs, files in os.walk("raw/%s"%cate):
for file in files:
filepath = os.path.join(root, file)
if "2022" not in file:
continue
date = file.split('-')[0] + file.split('-')[1]
content = open(filepath).read()
json_ = json.loads(content)
titles = []
if cate == "toutiao-search":
titles = [i["word"] for i in json_]
elif cate == "zhihu-questions":
titles = [i["title"] for i in json_]
elif cate == "zhihu-search":
titles = [i["display_query"] for i in json_]
elif cate == "zhihu-video":
titles = [i["title"] for i in json_]
if not titles:
continue
if date not in date_dict:
date_dict[date] = titles
else:
date_dict[date] += titles
if not os.path.exists("%s_news"%cate):
os.makedirs("%s_news"%cate)
for date, titles in date_dict.items():
out = open("%s_news/%s.txt"%(cate, date), 'w+')
out.write('\n'.join(titles))
out.close()
return
def draw_cloud(cate, date, words):
# words = [
# ("我爱你", 10000), ("美丽", 6181),("天空", 4386),
# ("江西", 4055),("任务", 2467), ("红色", 2244),
# ("大海", 1868), ("人民", 1281)
# ]
def wordcloud_base() -> WordCloud:
c = (
WordCloud()
.add("", words, word_size_range=[20, 100])
.set_global_opts(title_opts=opts.TitleOpts(title="%s-%s 高频词云"%(cate, date)))
)
return c
wd = wordcloud_base()
if not os.path.exists("%s-cloud"%cate):
os.makedirs("%s-cloud"%cate)
wd.render("%s-cloud/%s.html"%(cate, date))
def draw(cate):
for root, dirs, files in os.walk("%s_news"%cate):
for file in files:
print(file)
wds_all = []
filepath = os.path.join(root, file)
date = file.split('.')[0]
for line in open(filepath):
line = line.strip()
if not line:
continue
wds = [i.word for i in pseg.cut(line) if i.flag[0] in {"n", 'v', 'a', 'i', 'l'} and len(i.word) > 1]
wds_all += wds
words = Counter(wds_all).most_common()
draw_cloud(cate, date, words[:100])
return
if __name__ == '__main__':
create_docs("toutiao-search")
create_docs("weibo-search")
create_docs("zhihu-questions")
create_docs("zhihu-search")
create_docs("zhihu-video")
draw("toutiao-search")
create_docs("weibo-search")
draw("zhihu-questions")
draw("zhihu-search")
draw("zhihu-video") 二、2022年1月词云及代表性热点记忆
1、五大榜单的词云

2、微博热搜
3、头条热搜

4、知乎热点话题

三、2022年2月词云及代表性热点记忆
1、五大榜单的词云

2、微博热搜
3、头条热搜

4、知乎热点话题

四、2022年3月词云及代表性热点记忆
1、五大榜单的词云

2、微博热搜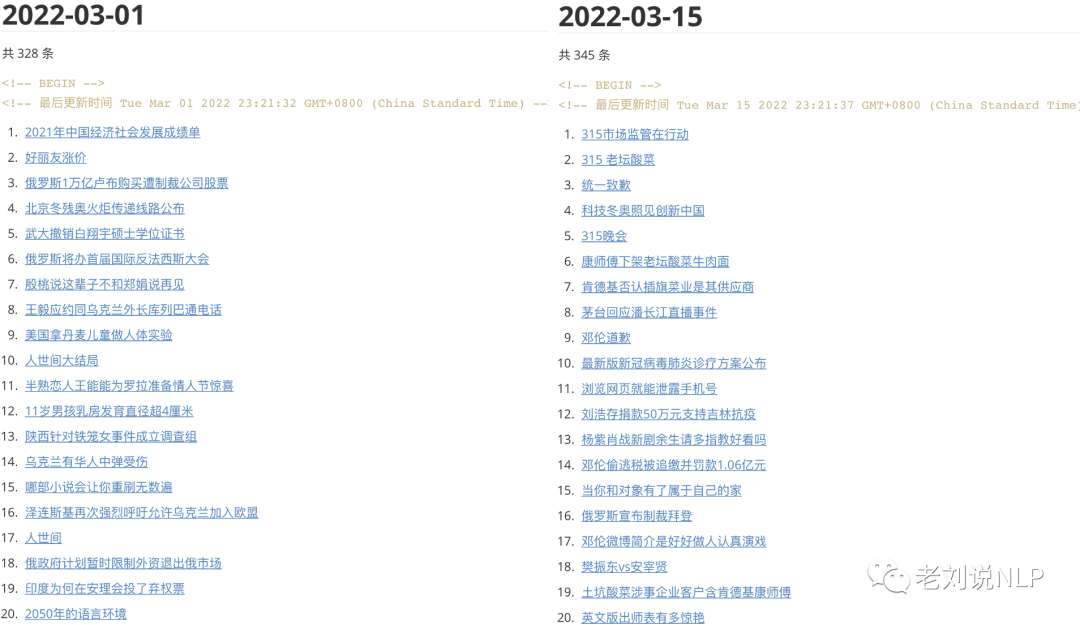
3、头条热搜
 4、知乎热点话题
4、知乎热点话题

五、2022年4月词云及代表性热点记忆
1、五大榜单的词云
2、微博热搜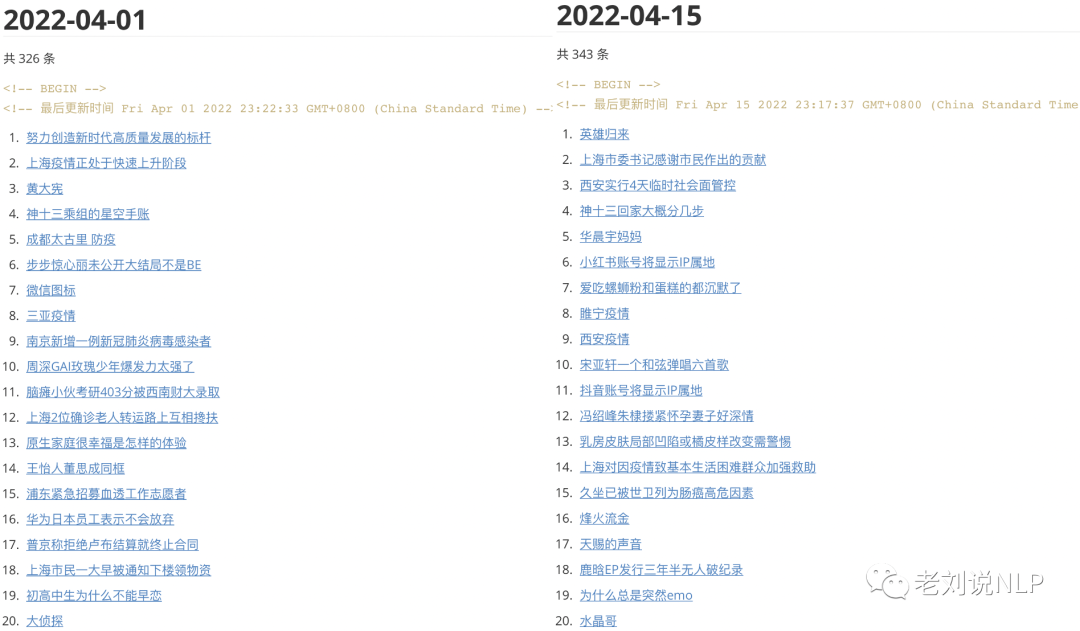
2、头条热搜

3、知乎热点话题

六、2022年5月词云及代表性热点记忆
1、五大榜单的词云

2、微博热搜
3、头条热搜

4、知乎热点话题

七、2022年6月词云及代表性热点记忆
1、五大榜单的词云

2、微博热搜
3、头条热搜

4、知乎热点话题

八、2022年7月词云及代表性热点记忆
1、五大榜单的词云

2、微博热搜
3、头条热搜

4、知乎热点话题

九、2022年8月词云及代表性热点记忆
1、五大榜单的词云
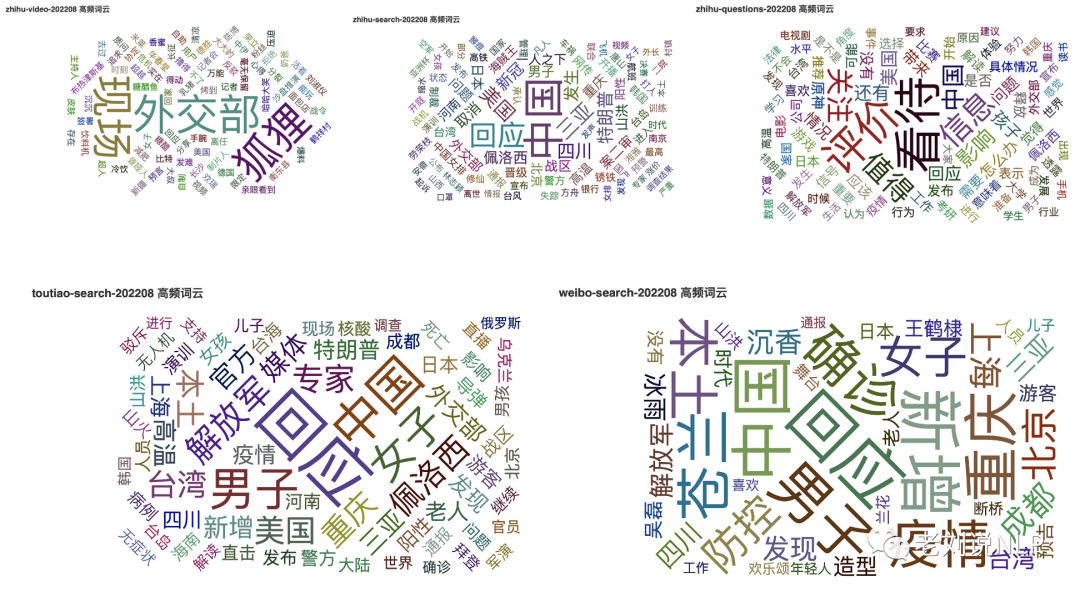
2、微博热搜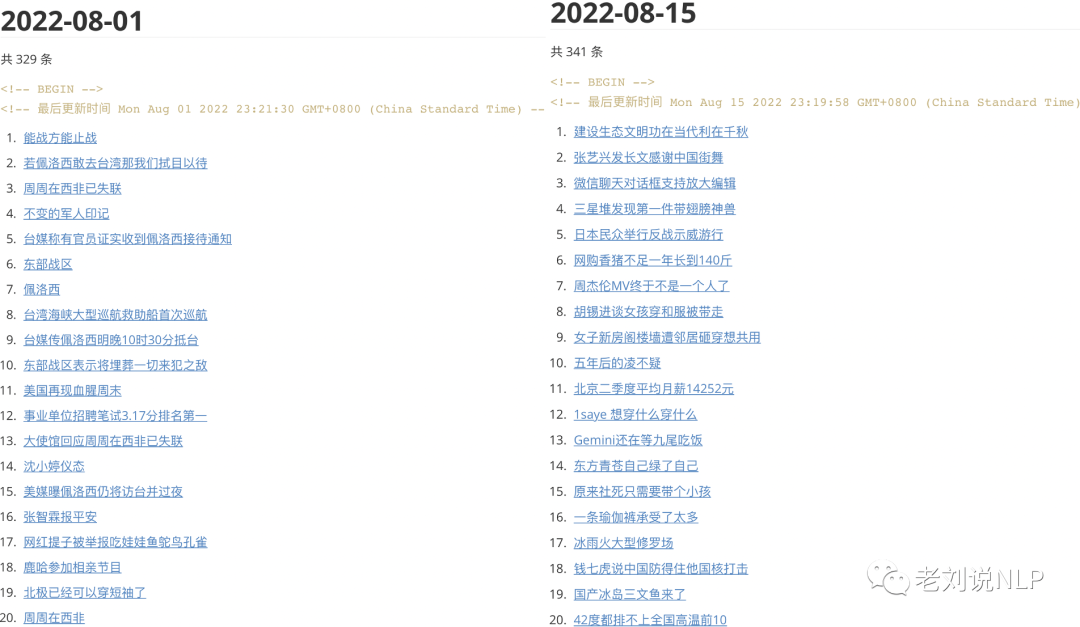
3、头条热搜

4、知乎热点话题

十、2022年9月词云及代表性热点记忆
1、五大榜单的词云

2、微博热搜
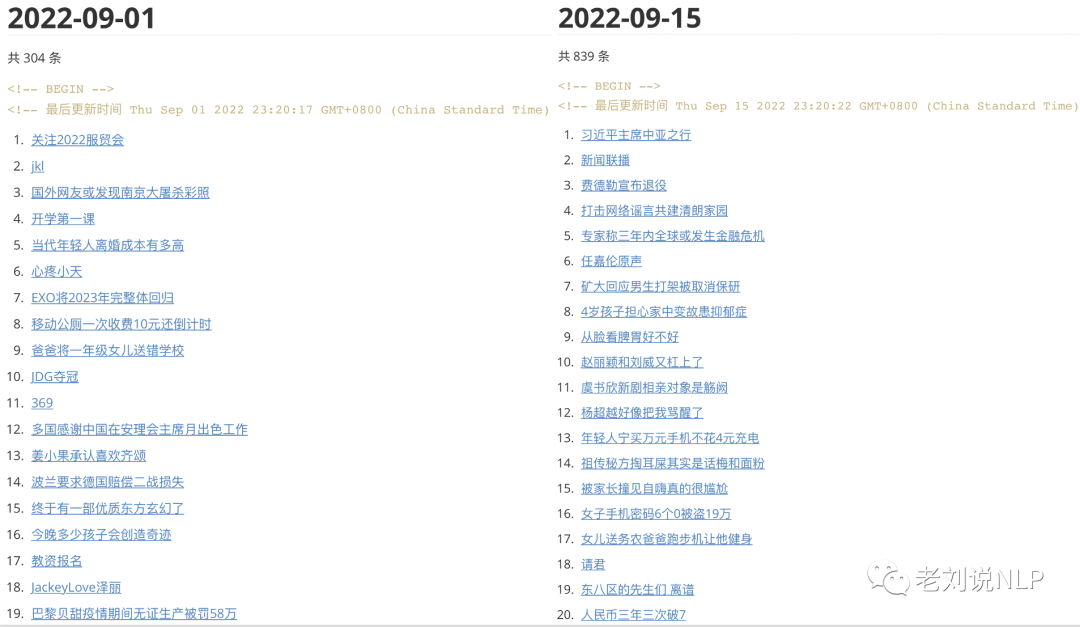
3、头条热搜

4、知乎热点话题

十一、2022年10月词云及代表性热点记忆
1、五大榜单的词云

2、微博热搜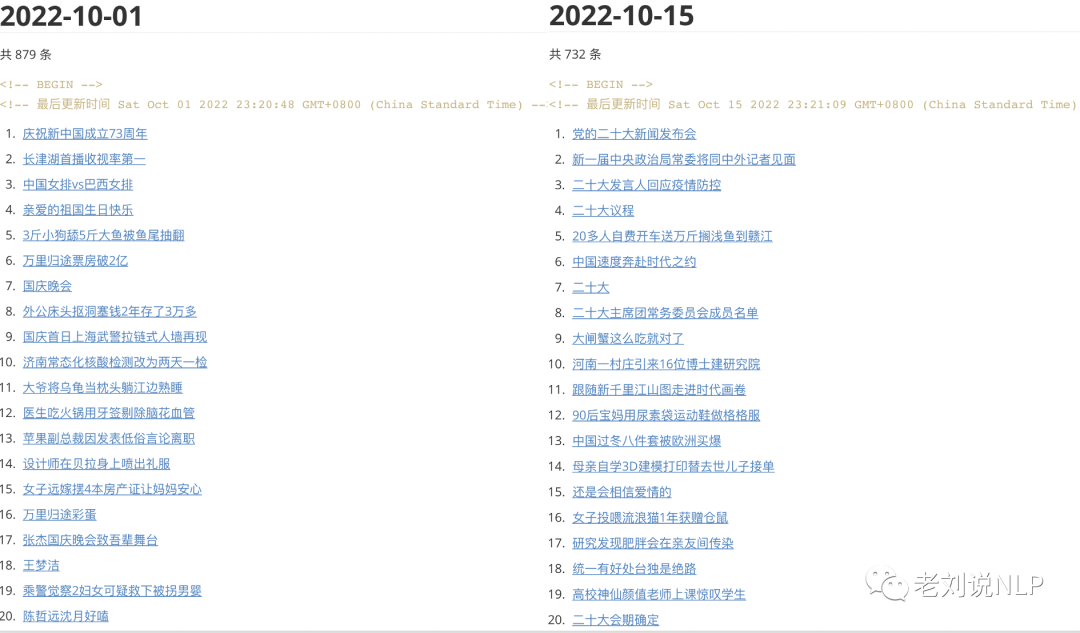
3、头条热搜
4、知乎热点话题

十二、2022年11月词云及代表性热点记忆
1、五大榜单的词云

2、微博热搜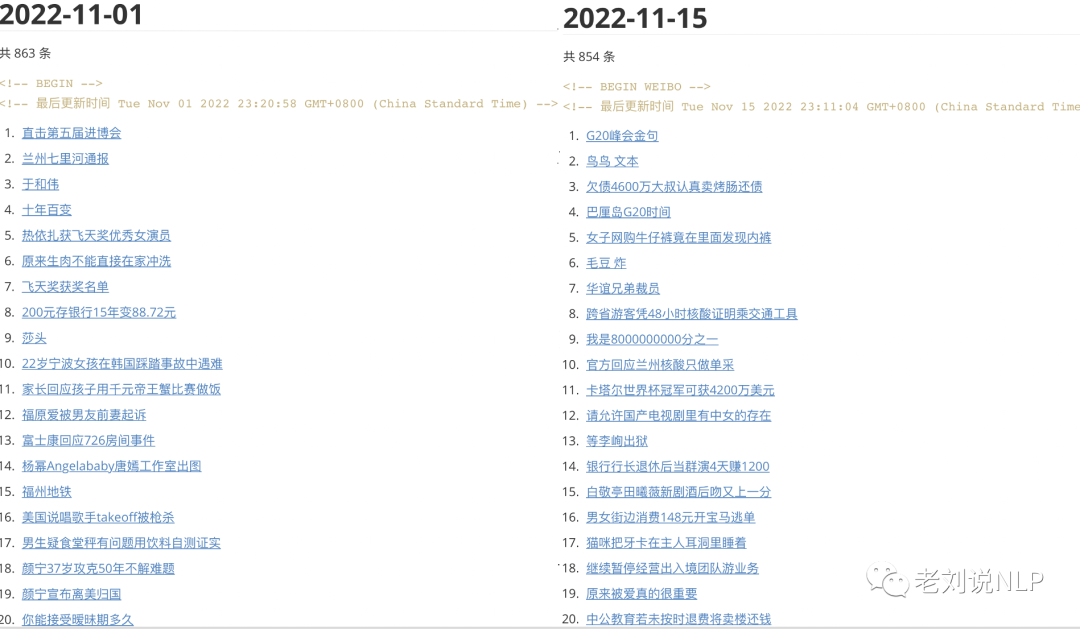
3、头条热搜
4、知乎热点话题

十三、2022年12月词云及代表性热点记忆
1、五大榜单的词云

2、微博热搜
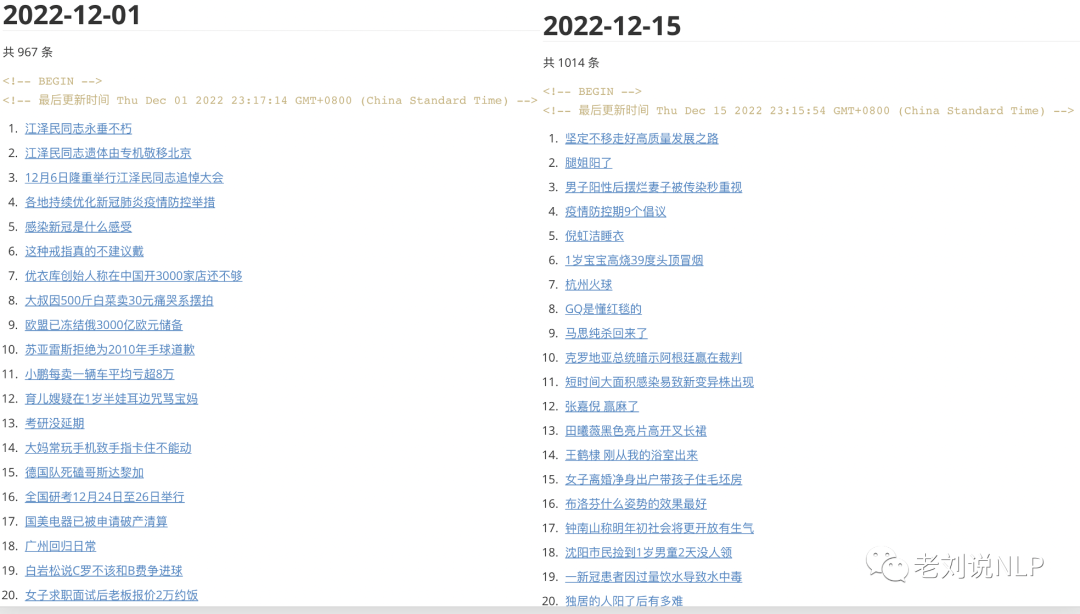

3、头条热搜

4、知乎热点话题


总结
本文作为对2022年的历史性记忆回顾,以开源项目trending-in-one给出的当前全年历时热点数据,进行词云生成,并按月度为单位,以不同的榜单进行统计呈现,将词云及代表性热点记忆进行客观、真实的展示。
从语言学及文本分析的角度,历时语料库为我们提供了一个记录历史的视角,这是一个很宝贵的财富,我们可以使用不同的方法进行社会的计算与剖析,这种方法最为客观与公正。
随着日历最后一页的最后一格被勾掉的那一刻,这一年的岁月也就算画上句号,这一年的记忆也就开始封存。
2022年是一个折腾不断的、并不太平的、让人抑郁而又抱有希望的一年,这一年在这一刻,就要过去了。
新年的钟声再过不到2小时就要敲响了,老刘说NLP祝大家新年快乐,在2023新的一年有新的收获、新的历程,踏踏实实地、平淡但不平凡地活出自己。
参考文献
1、https://github.com/huqi-pr/trending-in-one
2、https://mp.weixin.qq.com/s/INPkoAIELGdOyosLmB0yTQ

评论
沙发等你来抢