同城容灾方案
本章节介绍了PolarDB O在企业版中的同城容灾方案。
同城容灾简介
同城容灾是指在同一个Region的两个IDC,他们相互独立但互为备份,当主机房出现异常时,通过ASR切换服务,将备机房切换到线上。
用户应用通过域名访问两个机房里的PolarDB O集群。当云产品切换到备机房时,PolarDB O集群的域名不变,用户应用无需改造,让用户开发聚焦于业务,降低应用开发难度,方便用户使用PolarDB O数据库。
同城容灾架构
同城容灾架构如下图所示。
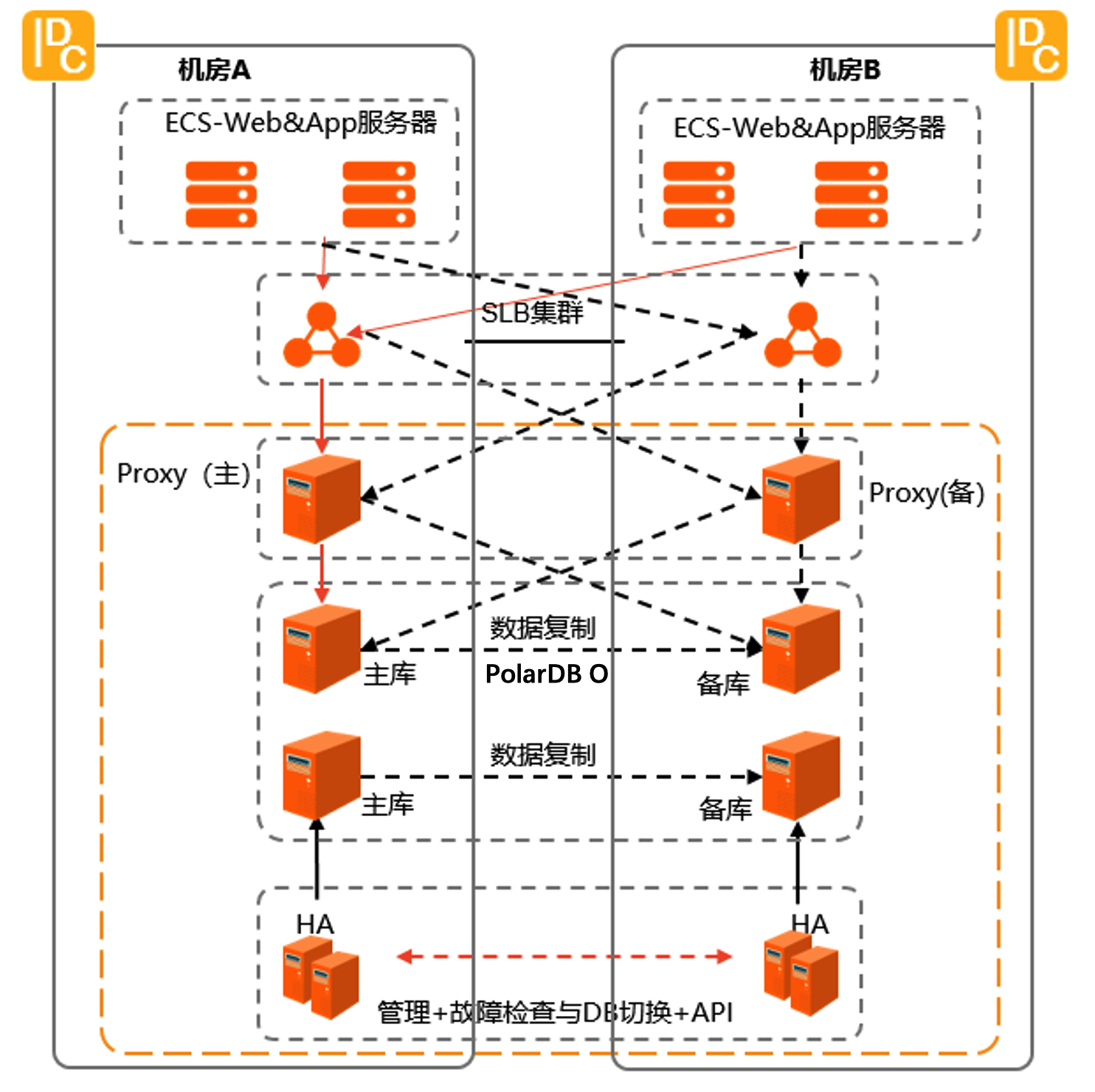
支持的数据库引擎:RDS是阿里云关系型数据库服务,为业务提供不同类型的数据库引擎。PolarDB O即是支持同城容灾的RDS数据库引擎之一。
数据库数据同步:PolarDB O在专有云企业版双机房环境里,两个机房的PolarDB O是一个整体集群,业务应用可以通过域名访问数据库实例,数据库主备切换业务应用无感知,一个数据库实例的主备库跨机房分布,主备库之间通过两个机房之间的高速网络复制数据,保证数据的RPO接近于0。
高可用逻辑模块:HA高可用模块负责数据库故障检查、主备库切换等内部管控业务。每个机房部署3个HA模块组成高可用集群,A/B机房的HA可以互通的情况下,HA模块可以发现数据库实例不可用,自动切换主备数据库实例;当A/B机房的HA不能互相访问时,HA不会主动切换实例,需要人为判断执行主备数据库切换。
数据库访问链路: PolarDB O的访问链路经过SLB、Proxy,再访问到数据库。
为了实现读写分离、七层负载均衡和避免连续闪断,引入了Proxy链路,也就是高安全访问模式,可防止90%的连接闪断。
RPO和RTO
本节以机房掉电这一场景为例,介绍PolarDB O在同城容灾架构下的RPO和RTO指标。
-
RPO(Recovery Point Objective):即数据恢复点目标,以时间为单位,即在灾难发生时,系统和数据必须恢复的时间点要求。RPO标志系统能够容忍的最大数据丢失量。系统容忍丢失的数据量越小,RPO的值越小。
-
RTO(Recovery Time Objective):即恢复时间目标,以时间为单位,即在灾难发生后,信息系统或业务功能从停止到必须恢复的时间要求。RTO标志系统能够容忍的服务停止的最长时间。系统服务的紧迫性要求越高,RTO的值越小。
| 部署架构 | RPO | RTO |
|---|---|---|
| 同机房部署架构 | 0 | < 30s |
| 同城部署架构 | 0 | < 60s |
容灾切换
正常情况下数据库的切换是由主机房的高可用模块处理,主机房断电、主机房网路孤岛场景下,需要切换数据库主库到备机房,切换流程如下:
- 检查相关的数据库切换模块、容灾模块、DNS API是否可用。
- 检查数据库实例是否都是正常的状态,没有损坏和不可以切换的数据库实例,只切换正常状态的数据库。
- 把所有可切换的数据库实例从主机房的高可用Aurora集群托管到备机房的Aurora集群。
- 对每个数据库创建切换任务,备机房高可靠模块Aurora集群异步处理切换任务。
- 容灾模块检查任务处理进展,最后汇报切换结果。
非对等容灾
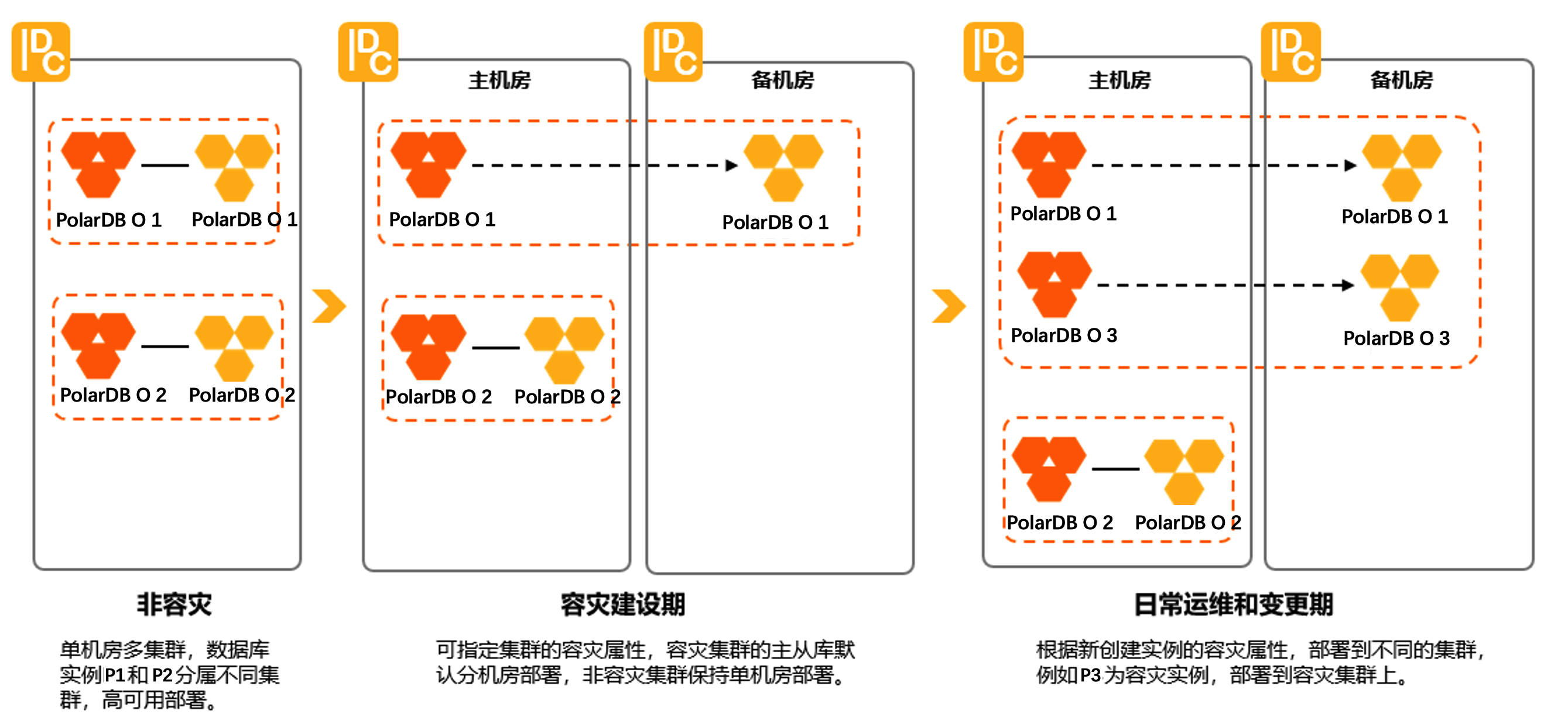
通过PolarDB O多集群能力实现PolarDB O非对等容灾。在规划时,将备机房PolarDB O集群的群组ID(cell_no),配置成和主机房PolarDB O集群的群组ID(cell_no)一致,即可组件成一个跨机房的容灾集群。不做容灾的PolarDB O集群依然保持单机房的形态。
用户在Apsara Uni-manager运营控制台上创建PolarDB O集群时,选择对应的可用区。不同的可用区分别对应单机房实例集群和跨机房容灾实例集群。用户可以根据需要选择部分实例进行容灾,而不必所有实例都开启容灾。容灾切换时只切换容灾部署的实例,不切换非容灾部署的单机房实例。如果需要单机房实例更改为容灾实例,只需迁移实例就能转换形态。
- 本页导读 (0)