作者:和君
引言
ClickHouse是近年来备受关注的开源列式数据库,主要用于数据分析(OLAP)领域。目前国内各个大厂纷纷跟进大规模使用:
- 今日头条内部用ClickHouse来做用户行为分析,内部一共几千个ClickHouse节点,单集群最大1200节点,总数据量几十PB,日增原始数据300TB左右。
- 腾讯内部用ClickHouse做游戏数据分析,并且为之建立了一整套监控运维体系。
- 携程内部从18年7月份开始接入试用,目前80%的业务都跑在ClickHouse上。每天数据增量十多亿,近百万次查询请求。
- 快手内部也在使用ClickHouse,存储总量大约10PB, 每天新增200TB, 90%查询小于3S。
- 阿里内部专门孵化了相应的云数据库ClickHouse,并且在包括手机淘宝流量分析在内的众多业务被广泛使用。
在国外,Yandex内部有数百节点用于做用户点击行为分析,CloudFlare、Spotify等头部公司也在使用。
在开源的短短几年时间内,ClickHouse就俘获了诸多大厂的“芳心”,并且在Github上的活跃度超越了众多老牌的经典开源项目,如Presto、Druid、Impala、Geenplum等;其受欢迎程度和社区火热程度可见一斑。
而这些现象背后的重要原因之一就是它的极致性能,极大地加速了业务开发速度,本文尝试解读ClickHouse存储层的设计与实现,剖析它的性能奥妙。
ClickHouse的组件架构
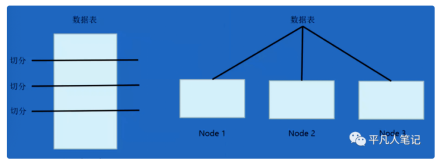
下图是一个典型的ClickHouse集群部署结构图,符合经典的share-nothing架构。

整个集群分为多个shard(分片),不同shard之间数据彼此隔离;在一个shard内部,可配置一个或多个replica(副本),互为副本的2个replica之间通过专有复制协议保持最终一致性。
ClickHouse根据表引擎将表分为本地表和分布式表,两种表在建表时都需要在所有节点上分别建立。其中本地表只负责当前所在server上的写入、查询请求;而分布式表则会按照特定规则,将写入请求和查询请求进行拆解,分发给所有server,并且最终汇总请求结果。
ClickHouse写入链路
ClickHouse提供2种写入方法,1)写本地表;2)写分布式表。
写本地表方式,需要业务层感知底层所有server的IP,并且自行处理数据的分片操作。由于每个节点都可以分别直接写入,这种方式使得集群的整体写入能力与节点数完全成正比,提供了非常高的吞吐能力和定制灵活性。但是相对而言,也增加了业务层的依赖,引入了更多复杂性,尤其是节点failover容错处理、扩缩容数据re-balance、写入和查询需要分别使用不同表引擎等都要在业务上自行处理。
而写分布式表则相对简单,业务层只需要将数据写入单一endpoint及单一一张分布式表即可,不需要感知底层server拓扑结构等实现细节。写分布式表也有很好的性能表现,在不需要极高写入吞吐能力的业务场景中,建议直接写入分布式表降低业务复杂度。
以下阐述分布式表的写入实现原理。
ClickHouse使用Block作为数据处理的核心抽象,表示在内存中的多个列的数据,其中列的数据在内存中也采用列存格式进行存储。示意图如下:其中header部分包含block相关元信息,而id UInt8、name String、_date Date则是三个不同类型列的数据表示。

在Block之上,封装了能够进行流式IO的stream接口,分别是IBlockInputStream、IBlockOutputStream,接口的不同对应实现不同功能。
当收到INSERT INTO请求时,ClickHouse会构造一个完整的stream pipeline,每一个stream实现相应的逻辑:
InputStreamFromASTInsertQuery #将insert into请求封装为InputStream作为数据源 -> CountingBlockOutputStream #统计写入block count -> SquashingBlockOutputStream #积攒写入block,直到达到特定内存阈值,提升写入吞吐 -> AddingDefaultBlockOutputStream #用default值补全缺失列 -> CheckConstraintsBlockOutputStream #检查各种限制约束是否满足 -> PushingToViewsBlockOutputStream #如有物化视图,则将数据写入到物化视图中 -> DistributedBlockOutputStream #将block写入到分布式表中
注:*左右滑动阅览
在以上过程中,ClickHouse非常注重细节优化,处处为性能考虑。在SQL解析时,ClickHouse并不会一次性将完整的INSERT INTO table(cols) values(rows)解析完毕,而是先读取insert into table(cols)这些短小的头部信息来构建block结构,values部分的大量数据则采用流式解析,降低内存开销。在多个stream之间传递block时,实现了copy-on-write机制,尽最大可能减少内存拷贝。在内存中采用列存存储结构,为后续在磁盘上直接落盘为列存格式做好准备。
SquashingBlockOutputStream将客户端的若干小写,转化为大batch,提升写盘吞吐、降低写入放大、加速数据Compaction。
默认情况下,分布式表写入是异步转发的。DistributedBlockOutputStream将Block按照建表DDL中指定的规则(如hash或random)切分为多个分片,每个分片对应本地的一个子目录,将对应数据落盘为子目录下的.bin文件,写入完成后就返回client成功。随后分布式表的后台线程,扫描这些文件夹并将.bin文件推送给相应的分片server。.bin文件的存储格式示意如下:

ClickHouse存储格式
ClickHouse采用列存格式作为单机存储,并且采用了类LSM tree的结构来进行组织与合并。一张MergeTree本地表,从磁盘文件构成如下图所示。

本地表的数据被划分为多个Data PART,每个Data PART对应一个磁盘目录。Data PART在落盘后,就是immutable的,不再变化。ClickHouse后台会调度MergerThread将多个小的Data PART不断合并起来,形成更大的Data PART,从而获得更高的压缩率、更快的查询速度。当每次向本地表中进行一次insert请求时,就会产生一个新的Data PART,也即新增一个目录。如果insert的batch size太小,且insert频率很高,可能会导致目录数过多进而耗尽inode,也会降低后台数据合并的性能,这也是为什么ClickHouse推荐使用大batch进行写入且每秒不超过1次的原因。
在Data PART内部存储着各个列的数据,由于采用了列存格式,所以不同列使用完全独立的物理文件。每个列至少有2个文件构成,分别是.bin 和 .mrk文件。其中.bin是数据文件,保存着实际的data;而.mrk是元数据文件,保存着数据的metadata。此外,ClickHouse还支持primary index、skip index等索引机制,所以也可能存在着对应的pk.idx,skip_idx.idx文件。
在数据写入过程中,数据被按照index_granularity切分为多个颗粒(granularity),默认值为8192行对应一个颗粒。多个颗粒在内存buffer中积攒到了一定大小(由参数min_compress_block_size控制,默认64KB),会触发数据的压缩、落盘等操作,形成一个block。每个颗粒会对应一个mark,该mark主要存储着2项信息:1)当前block在压缩后的物理文件中的offset,2)当前granularity在解压后block中的offset。所以Block是ClickHouse与磁盘进行IO交互、压缩/解压缩的最小单位,而granularity是ClickHouse在内存中进行数据扫描的最小单位。
如果有ORDER BY key或Primary key,则ClickHouse在Block数据落盘前,会将数据按照ORDER BY key进行排序。主键索引pk.idx中存储着每个mark对应的第一行数据,也即在每个颗粒中各个列的最小值。
当存在其他类型的稀疏索引时,会额外增加一个<col>_<type>.idx文件,用来记录对应颗粒的统计信息。比如:
- minmax会记录各个颗粒的最小、最大值;
- set会记录各个颗粒中的distinct值;
- bloomfilter会使用近似算法记录对应颗粒中,某个值是否存在;

在查找时,如果query包含主键索引条件,则首先在pk.idx中进行二分查找,找到符合条件的颗粒mark,并从mark文件中获取block offset、granularity offset等元数据信息,进而将数据从磁盘读入内存进行查找操作。类似的,如果条件命中skip index,则借助于index中的minmax、set等信心,定位出符合条件的颗粒mark,进而执行IO操作。借助于mark文件,ClickHouse在定位出符合条件的颗粒之后,可以将颗粒平均分派给多个线程进行并行处理,最大化利用磁盘的IO吞吐和CPU的多核处理能力。
总结
本文主要从整体架构、写入链路、存储格式等几个方面介绍了ClickHouse存储层的设计,ClickHouse巧妙地结合了列式存储、稀疏索引、多核并行扫描等技术,最大化压榨硬件能力,在OLAP场景中性能优势非常明显。