如何快速而准确地进行 IP 和端口信息扫描:渗透测试必备技能

 已于 2023-05-20 13:24:06 修改
已于 2023-05-20 13:24:06 修改
 阅读量6.7k
阅读量6.7k
 收藏
23
收藏
23


 点赞数
点赞数

01 IP信息收集
1)IP反查域名
同IP网站查询,同服务器网站查询 - 站长工具
专业精准的IP库服务商_IPIP

2)域名查询IP
IP/IPv6查询,服务器地址查询 - 站长工具
或直接 ping 一下域名就会返回IP
3)CDN

如果网站使用了CDN那我们查找到的ip也是属于CDN的ip没多大用处
4)判断CDN
多个地点Ping服务器,网站测速 - 站长工具
这里ping百度

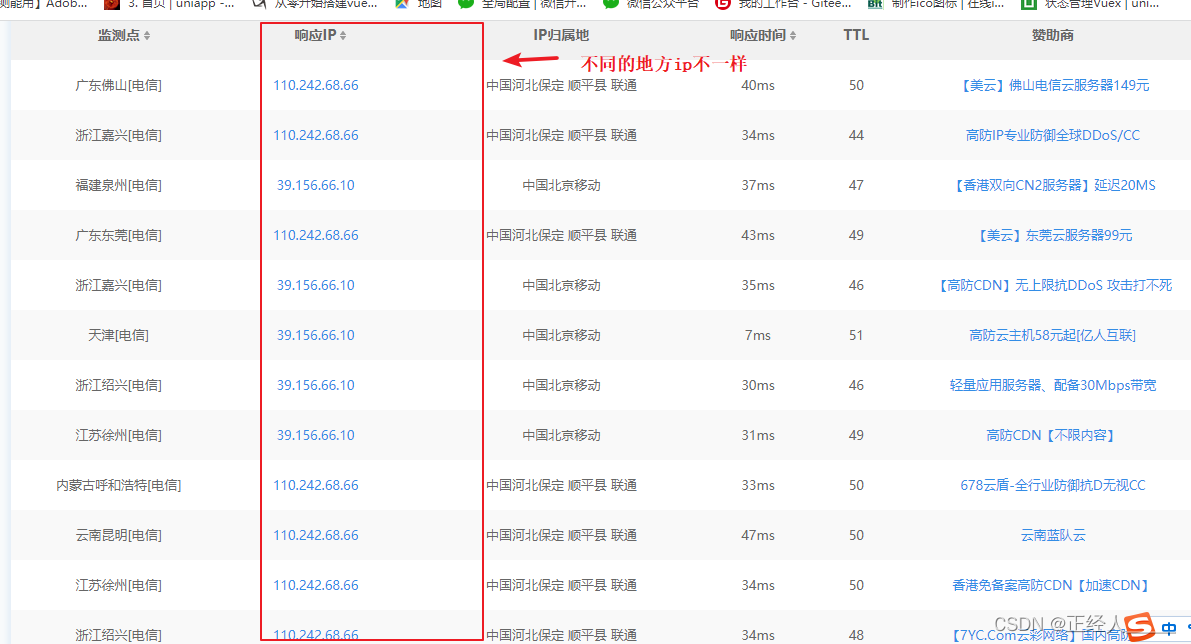
用各种多地ping的服务,查看对应P地址是否唯一,如果不唯一多半是使用了CDN www.kanzhun.com
5)绕过CDN
方法一:国外访问
原因:因为CDN服务是很贵的,一般厂商不会对国外开启CDN
网站全国各地Ping值测试|在线ping工具—卡卡网 www.webkaka.com
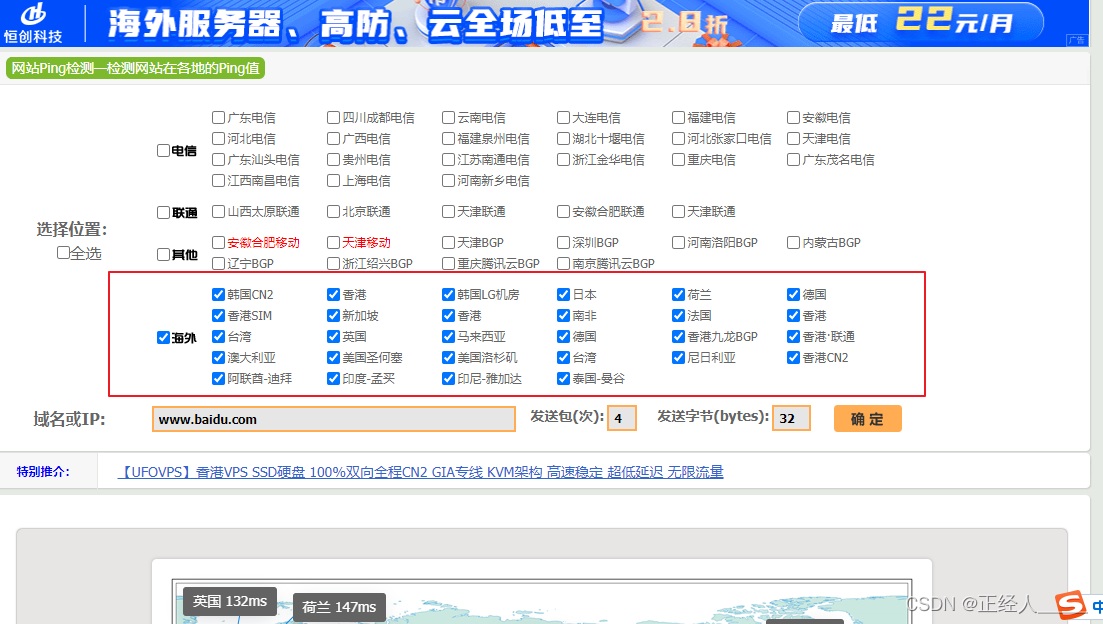
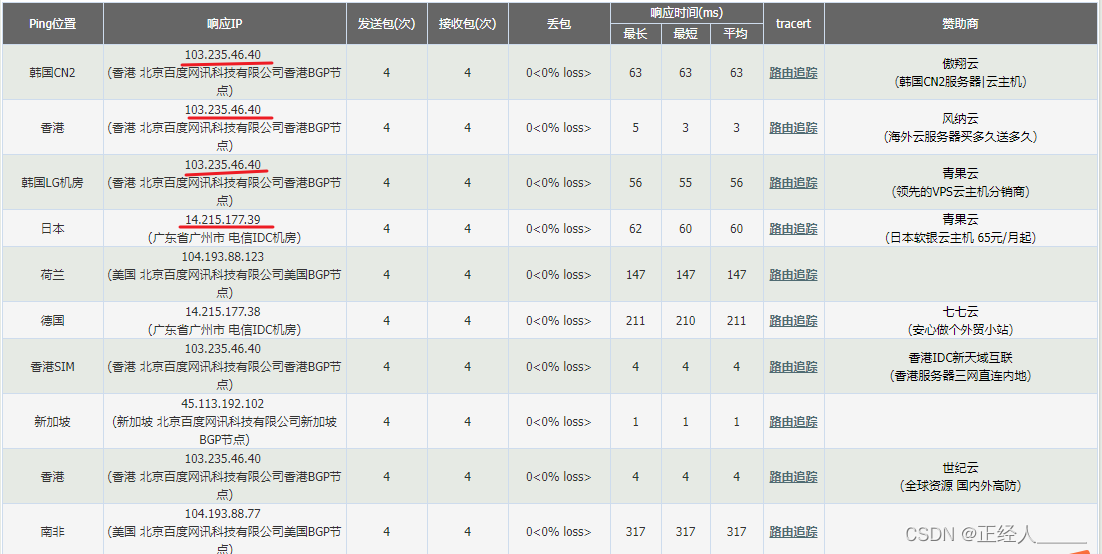
查看国外ping的ip是否一致,一致那正确的ip就是这里(如果他在国外也架起了CDN那这个方法就行不通)
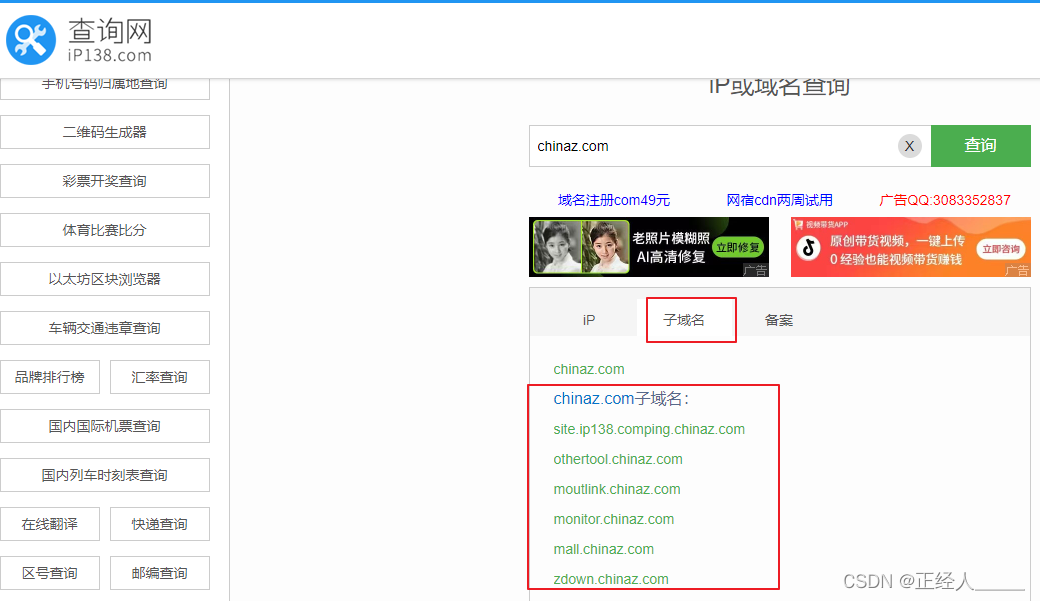
方法二:查询子域名的ip
ip查询 查ip 网站ip查询 同ip网站查询 iP反查域名 iP查域名 同ip域名
原因:因为CDN服务是很贵的,一般厂商不会对子域名开启CDN
方法三:查看phpinfo文件
前提:网站服务有这个文件,如果部署服务器的人没有删除掉的话(出现这个文件的几率很小)
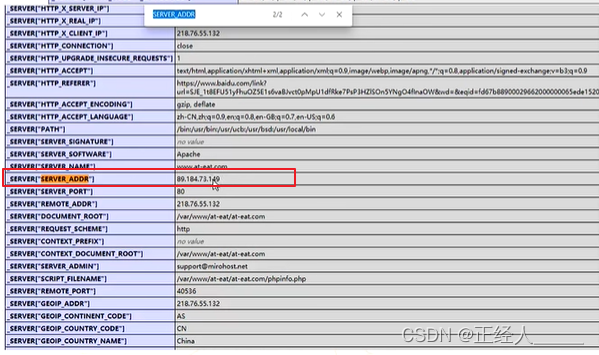
方法四:Mx 记录邮件服务
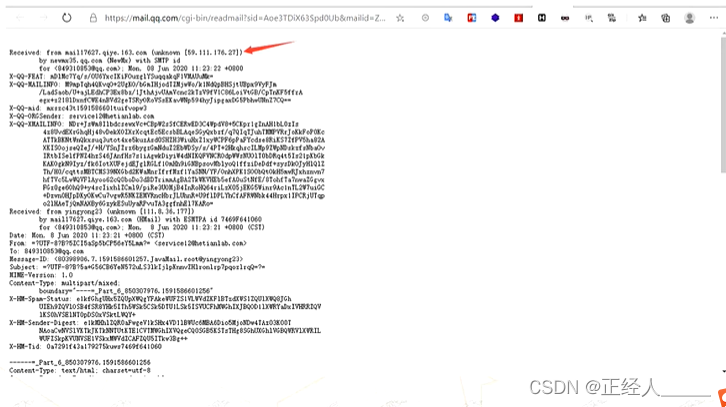
这里以QQ邮箱为例
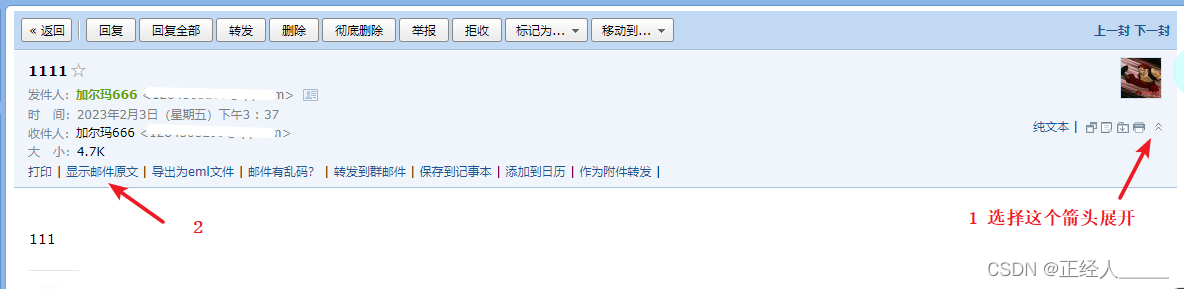
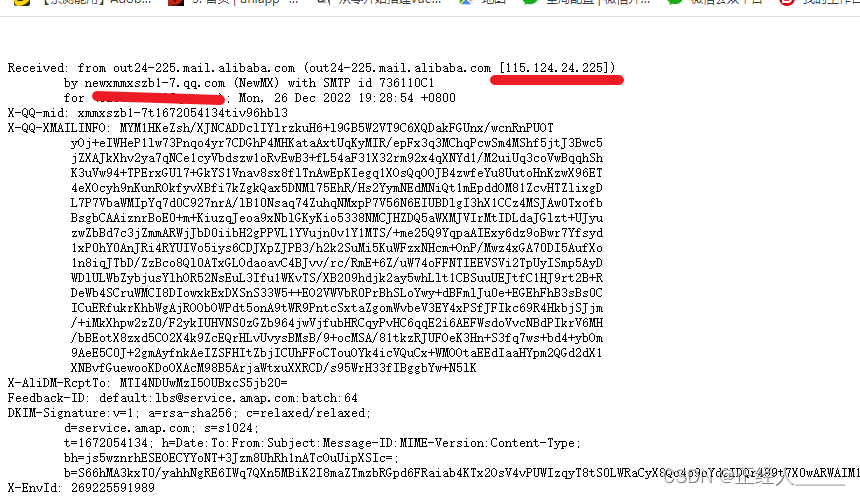
6)查询历史DNS记录
dsndb要翻墙,翻墙犯法。。。
https://securitytrails.com/
微步在线X情报社区-威胁情报查询_威胁分析平台_开放社区

查看IP与域名绑定的历史记录,可能会存在使用CDN前的记录域名注册完成后首先需要做域名解析,域名解析就是把堿名指向网站所在服务器的IP,让人们通过注册的域名可以访问到网站。
IP地址是网络上标识服务器的数字地址,为了方便记忆,使用域名来代替P地址。
域名解析就是域名到IP地址的转换过程,域名的解析工作由DNS服务器完成。DNS服务器会把堿名解析到个IP地址,然后在此P地址的主机上将一个子目录与域名绑定。域名解析时会添加解析记录,这些记录有: A记录、AAAA记录、 CNAME记录、MX记录、NS记录、TXT记录SRV记录、URL转发。
7)C段存活主机探测 - Nmap (kali自带)
C段:一般指段C网络段,也称为“段C渗透”IP范围192.0.0.1到223.255.255.254 段C服务器:为站集群服务器的IP网络段。IP地址是C段。C段服务器的本质是C级IP段。

02 端口信息收集
1)端口简介

2)端口协议

TCP:给目标主机发送信息之后,通过返回的应答确认信息是否到达
UDP:给目标主机放信息之后,不会去确认信息是否到达
而由于物理端口和逻辑端口数量较多,为了对端口进行区分,将毎个端口进行了编号,即就是端口号。那么看到这里我们会好奇,有那么多的端口,他们到底是怎么分类的?
3)端口类型

4)端口作用

5)渗透端口
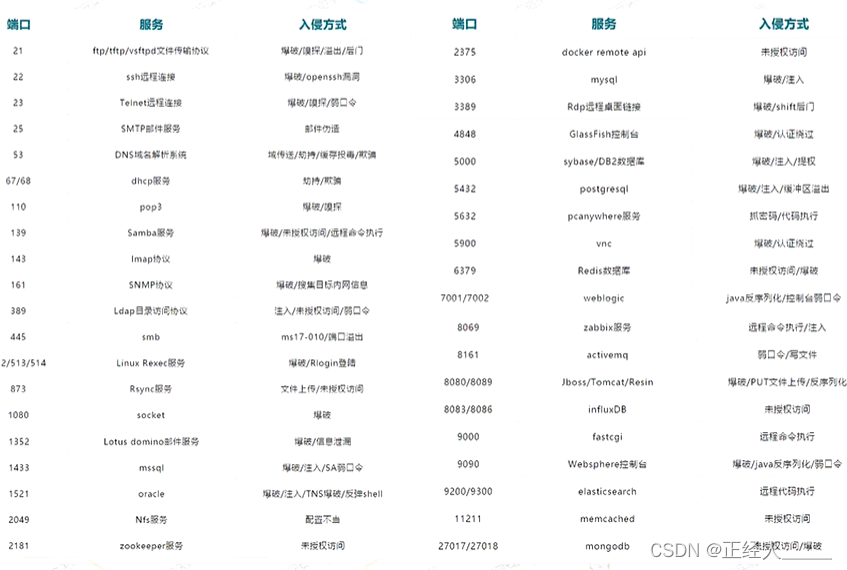
> FTP服务 - 21端口

FTP破解(搜索:爆破FTP )
> SSH - 22


ssh破解 (搜索:破解SSH服务)
> Telnet - 23

msf使用
> SMTP - 25 / 465

> WWW - 80

> Netbios Sessionservice - 139 / 445

IPC$使用(搜索:Ntscan)
> MYSQL - 3306

> RDP - 3389

连接方式:mstsc -v 目标ip
> Redis - 6379

> Weblogic - 7001

> Tomcat - 8080

6) 端口扫描
> Nmap介绍

https://nmap.org/man/zh/
> 功能介绍

> 端口状态

> 基础用法




> 扫描全部端囗

- -sS:SYN扫描又称为半开放扫描,它不打开一个完全的TCP连接,执行得很快,效率高(一个完整的TCP连接需要3次握手,而-sS选项不需要3次握手)
优点:Nmap发送SYN包到远程主机,但是它不会产生任何会话,目标主机几乎不会把连接记入系统日志。(防止对方判断为扫描攻击),扫描速度快,效率高在工作中使用频率最高
缺点:它需要root/administrator权限执行(管理员权限)
- -Pn:扫描之前不需要用ping命令,有些防火墙禁止ping命令。可以使用此选项进行扫描
- -iL:导入需要扫描的列表
> 探测存活主机
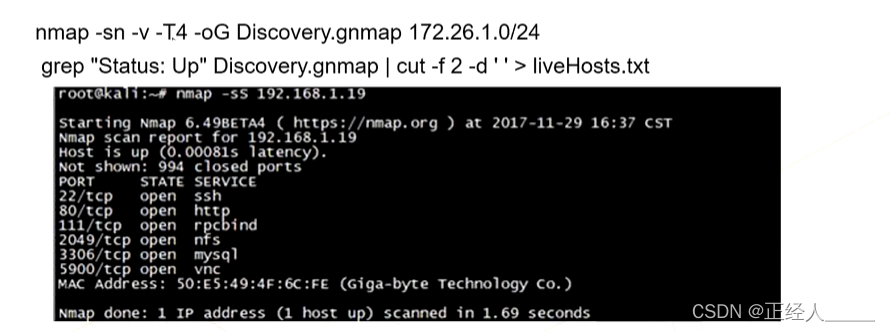
- -sn:ping扫描,和sP相同的效果
- -v:显示详细信息(扫描过程)
- -oN/-oX/-oG:将报告写入文件,分别是正常、XML、 grepable三种格式
> 扫描常用端口及服务信息

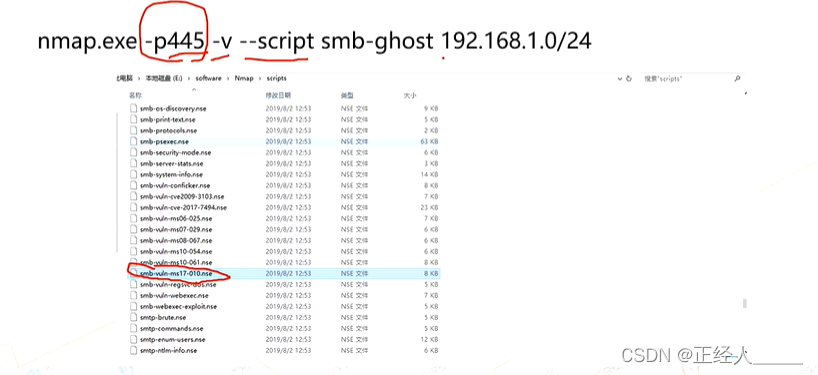
> nmap 漏洞扫描
03 其他信息收集
> 历史漏洞信息
乌云(WooYun.org)历史漏洞查询---http://WY.ZONE.CI
WooYun知识库(这个是学习漏洞的)
Exploit Database - Exploits for Penetration Testers, Researchers, and Ethical Hackers
![]()
https://www.seebug.org/
虽然乌云关了但是镜像上面还有大量企业洞信息此外 CNVD seebua等平台也能查找一些企业历史漏洞信息
其他信息收集 一 社会工程学(国内的社工库都被打掉了,了解即可)



















 1237
1237










 网络安全领域优质创作者
网络安全领域优质创作者






































 到【灌水乐园】发言
到【灌水乐园】发言












skpGG: <a href="http://www.baidu.com">baidu</a>
狗蛋的博客之旅: 非常感谢您的支持和鼓励!我会继续努力,为大家带来更多有价值的内容。谢谢您的阅读和留言!
shitgun: 非常好文章,使我芯片旋转,爱来自骨人
m0_74740978: 写得很好,解决了我的困惑
狗蛋的博客之旅: 1. 匹配逻辑(从前往后或从后往前): 从后往前匹配:大多数服务器会从文件名的末尾开始,找到最后一个点号(.)后面的部分作为后缀进行匹配。如果后台的检测机制是黑名单过滤,服务器会检查这个后缀是否在黑名单中。 从前往后匹配:这种情况较少见,但也有可能存在。这种方式会从文件名的开头逐个字符检查,直到找到后缀的开头。 2.包含匹配: 有些服务器可能会采用简单的包含检查,即只要后缀中包含如“php”这三个字母就会认为是非法后缀。这种方法相对不常见,因为它容易导致误判。 3. 解析还是判断: 判断:通常情况下,服务器在处理上传文件时,对于后缀的检查主要是进行字符串匹配和判断,而不是解析。这意味着它不会实际执行或解析文件内容,只是简单地查看文件名的后缀部分。 解析:只有在某些特定情况下(如根据文件内容或头部信息进行检测),服务器才会对文件进行更深入的解析,但这与后缀匹配黑名单的基础逻辑无关。 4. 绕过策略中的大小写敏感性: 如果服务器的匹配逻辑对大小写敏感,那么类似“pPHPhp”这样的形式可能会绕过检测。 如果服务器的匹配逻辑对大小写不敏感,那么“pPHPhp”仍然会被识别为非法后缀。 实际应用中的逻辑: 例如,假设服务器有一个黑名单,包含“php”后缀,并且它的检测逻辑是从文件名后面开始匹配,遇到“php”就替换为空。 当你上传一个名为“file.pPHPhp”的文件,如果服务器的匹配是大小写不敏感且从后往前匹配,它会识别“pPHPhp”为非法后缀,从而拒绝上传。 总结: 具体的匹配行为取决于服务器的实现方式,包括匹配顺序(从前往后或从后往前)、是否敏感大小写,以及是否只是简单的字符串判断。一般来说,后缀匹配是通过字符串匹配和判断来实现的,而不是通过解析文件内容。了解这些细节可以帮助你更好地理解绕过文件后缀检测的方法和原理。