Python 开发web服务器,返回HTML页面

 最新推荐文章于 2024-04-09 09:46:50 发布
最新推荐文章于 2024-04-09 09:46:50 发布
 阅读量4.7k
阅读量4.7k
 收藏
14
收藏
14


 点赞数
5
点赞数
5
仅供学习,转载请注明出处
前情篇章
Python 开发Web静态服务器 - 返回固定值:胖子老板,来包槟榔
从上一个篇章的内容中已经完成了使用TCP协议返回HTTP的请求,达到一个返回数据到访问浏览器的效果。
那么本次篇章的需求:
就是返回一个HTML文件到浏览器。
那么该怎么去开发这个功能呢?
大致开发思路
上一篇是通过TCP返回一长串http的数据,分别为 header 和 body 部分。
那么是不是只要读取一个HTML的文件内容,拼接通过body部分进行数据返回。
那么就可以达到访问浏览器获取对应HTML数据的效果呢?
那么还有一个问题,就是访问浏览器的时候的url路径,如何去解析访问哪个html文件呢?
简单来说,就可以使用服务端接受到的url地址,使用正则表达式来解析最后的路径,再根据路径来判断访问哪个html文件。
好了,思路已有,下面就是一步步去实现。
首先回顾一下上一篇的代码
[root@server01 web]# cat server.py
#coding=utf-8
from socket import *
def handle_client(client_socket):
"""为一个客户端服务"""
# 接收对方发送的数据
recv_data = client_socket.recv(1024).decode("utf-8") # 1024表示本次接收的最大字节数
# 打印从客户端发送过来的数据内容
#print("client_recv:",recv_data)
request_header_lines = recv_data.splitlines()
for line in request_header_lines:
print(line)
# 返回浏览器数据
# 设置返回的头信息 header
response_headers = "HTTP/1.1 200 OK\r\n" # 200 表示找到这个资源
response_headers += "\r\n" # 空一行与body隔开
# 设置内容body
response_body = "<h1>fat boss<h1>\r\n"
response_body += "<h2>come on<h2>\r\n"
response_body += "<h3>binlang!!!<h3>\r\n"
# 合并返回的response数据
response = response_headers + response_body
# 返回数据给浏览器
client_socket.send(response.encode("utf-8")) #转码utf-8并send数据到浏览器
client_socket.close()
def main():
# 创建套接字
server_socket = socket(AF_INET, SOCK_STREAM)
# 设置当服务器先close 即服务器端4次挥手之后资源能够立即释放,这样就保证了,下次运行程序时 可以立即绑定7788端口
server_socket.setsockopt(SOL_SOCKET, SO_REUSEADDR, 1)
# 设置服务端提供服务的端口号
server_socket.bind(('', 7788))
# 使用socket创建的套接字默认的属性是主动的,使用listen将其改为被动,用来监听连接
server_socket.listen(128) #最多可以监听128个连接
# 开启while循环处理访问过来的请求
while True:
# 如果有新的客户端来链接服务端,那么就产生一个新的套接字专门为这个客户端服务
# client_socket用来为这个客户端服务
# server_socket就可以省下来专门等待其他新的客户端连接while True:
client_socket, clientAddr = server_socket.accept()
handle_client(client_socket)
if __name__ == "__main__":
main()
[root@server01 web]#
运行如下:

准备一个index.html的代码,提供返回浏览器访问
可以到一些建站模板网站下载一份前端代码:

那么下一步将html文件上传到服务器上。
编写读取index.html文件,然后访问浏览器
整体代码如下:
#coding=utf-8
from socket import *
def handle_client(client_socket):
"""为一个客户端服务"""
# 接收对方发送的数据
recv_data = client_socket.recv(1024).decode("utf-8") # 1024表示本次接收的最大字节数
# 打印从客户端发送过来的数据内容
#print("client_recv:",recv_data)
request_header_lines = recv_data.splitlines()
for line in request_header_lines:
print(line)
# 返回浏览器数据
# 设置返回的头信息 header
response_headers = "HTTP/1.1 200 OK\r\n" # 200 表示找到这个资源
response_headers += "\r\n" # 空一行与body隔开
# 设置内容body
# response_body = "<h1>fat boss<h1>\r\n"
# response_body += "<h2>come on<h2>\r\n"
# response_body += "<h3>binlang!!!<h3>\r\n"
# 合并返回的response数据
# response = response_headers + response_body
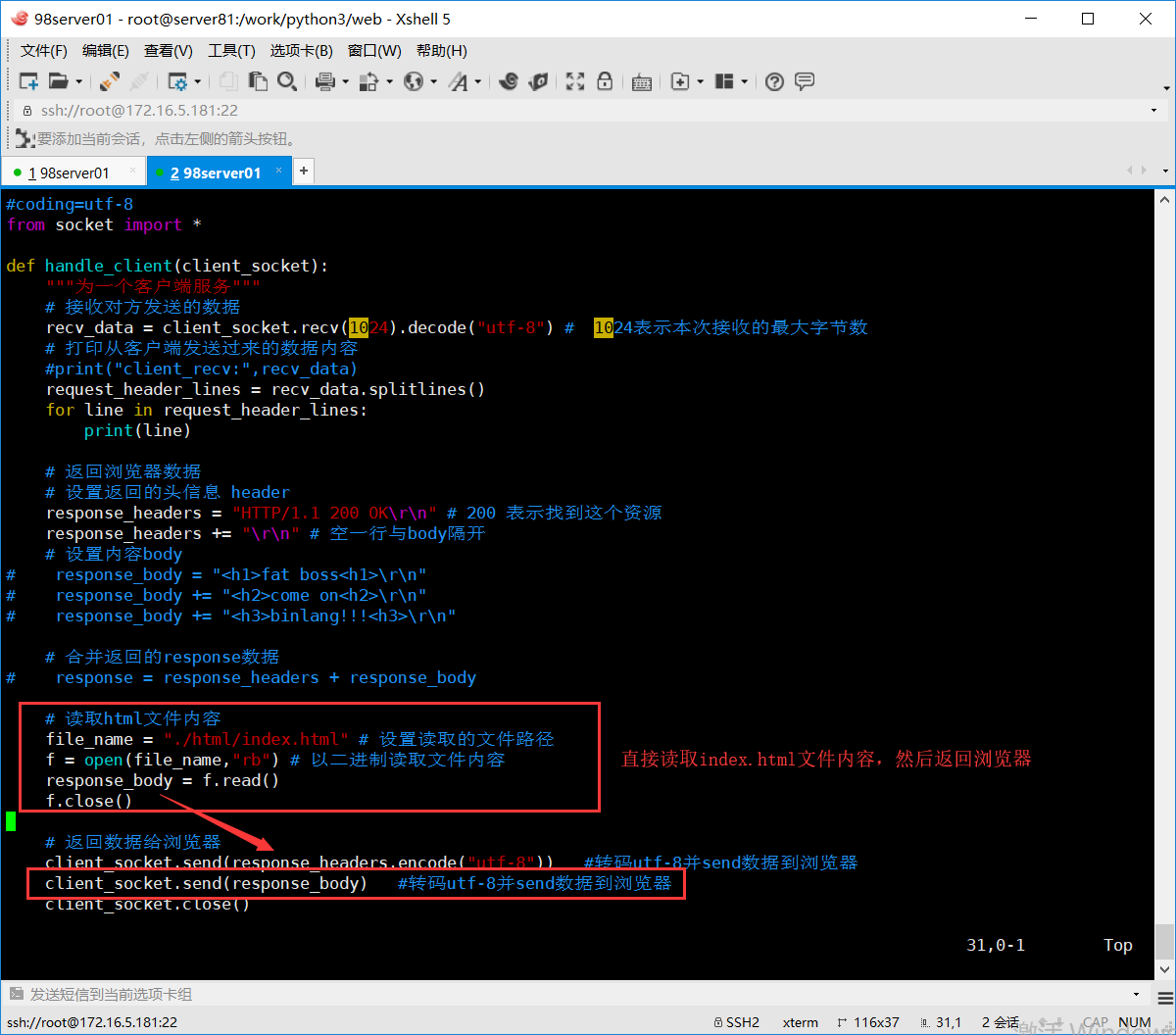
# 读取html文件内容
file_name = "./html/index.html" # 设置读取的文件路径
f = open(file_name,"rb") # 以二进制读取文件内容
response_body = f.read()
f.close()
# 返回数据给浏览器
client_socket.send(response_headers.encode("utf-8")) #转码utf-8并send数据到浏览器
client_socket.send(response_body) #转码utf-8并send数据到浏览器
client_socket.close()
def main():
# 创建套接字
server_socket = socket(AF_INET, SOCK_STREAM)
# 设置当服务器先close 即服务器端4次挥手之后资源能够立即释放,这样就保证了,下次运行程序时 可以立即绑定7788端口
server_socket.setsockopt(SOL_SOCKET, SO_REUSEADDR, 1)
# 设置服务端提供服务的端口号
server_socket.bind(('', 7788))
# 使用socket创建的套接字默认的属性是主动的,使用listen将其改为被动,用来监听连接
server_socket.listen(128) #最多可以监听128个连接
# 开启while循环处理访问过来的请求
while True:
# 如果有新的客户端来链接服务端,那么就产生一个新的套接字专门为这个客户端服务
# client_socket用来为这个客户端服务
# server_socket就可以省下来专门等待其他新的客户端连接while True:
client_socket, clientAddr = server_socket.accept()
handle_client(client_socket)
if __name__ == "__main__":
main()
执行访问如下:
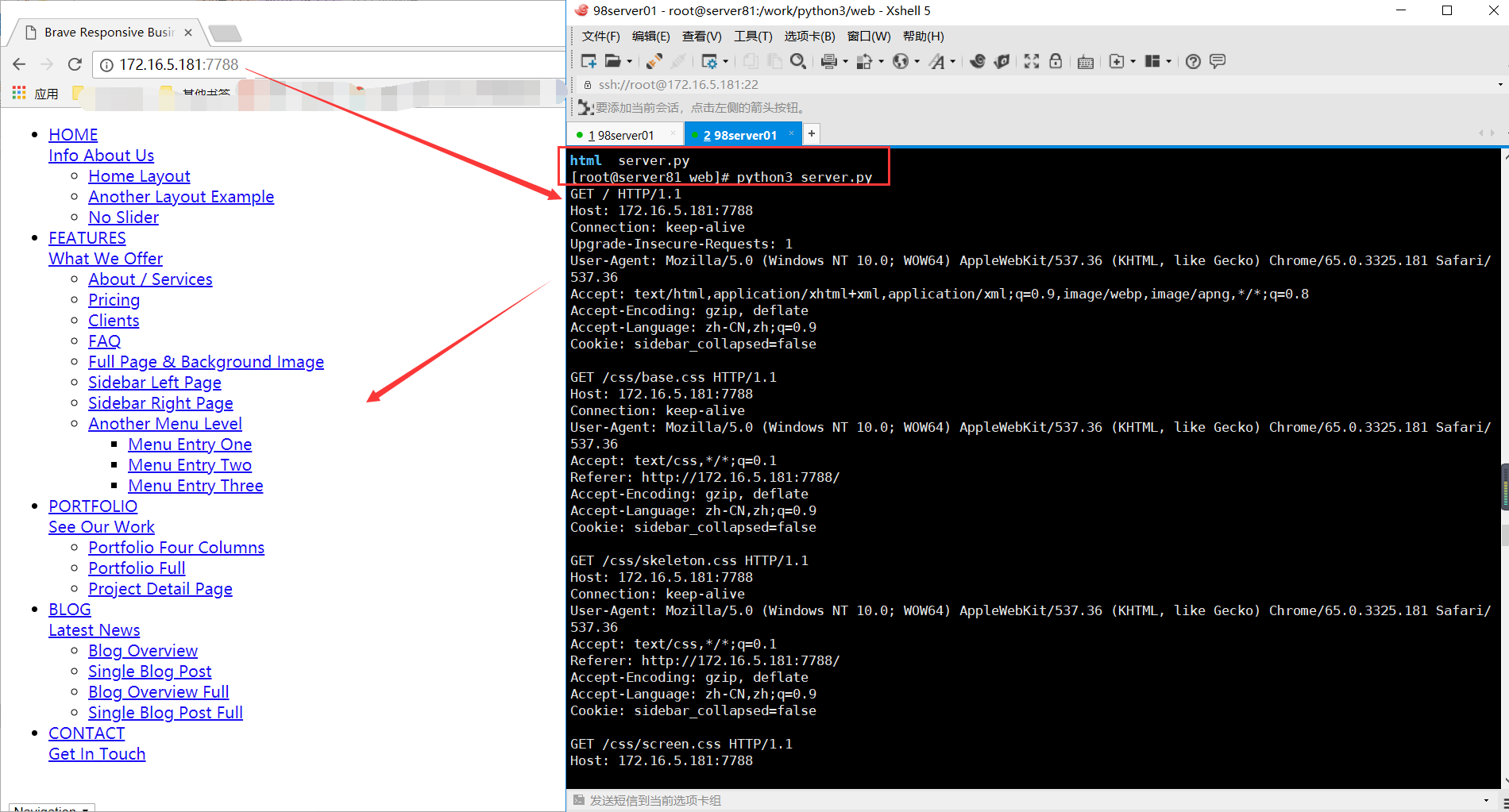
可以看到浏览器已经显示index.html的内容了,同时还发送了很多的请求到服务端。
但是由于没有请求下载到css和图片等数据内容,所以直接看到一个比较简陋的页面。
那么下一步,就应该使用正则匹配出所有的文件路径,这样的话,就可以返回浏览器关于css、js、image的图片了。
正则匹配请求中的路径,获取对应的文件地址
# IP地址换了不用慌,这是因为我回家了,用家里的演示机了。
[root@server01 web]# python3 server.py
GET / HTTP/1.1
Host: 192.168.150.128:7788
Connection: keep-alive
Cache-Control: max-age=0
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9
GET /css/base.css HTTP/1.1
Host: 192.168.150.128:7788
Connection: keep-alive
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36
Accept: text/css,*/*;q=0.1
Referer: http://192.168.150.128:7788/
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9
GET /css/skeleton.css HTTP/1.1
Host: 192.168.150.128:7788
Connection: keep-alive
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36
Accept: text/css,*/*;q=0.1
Referer: http://192.168.150.128:7788/
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9
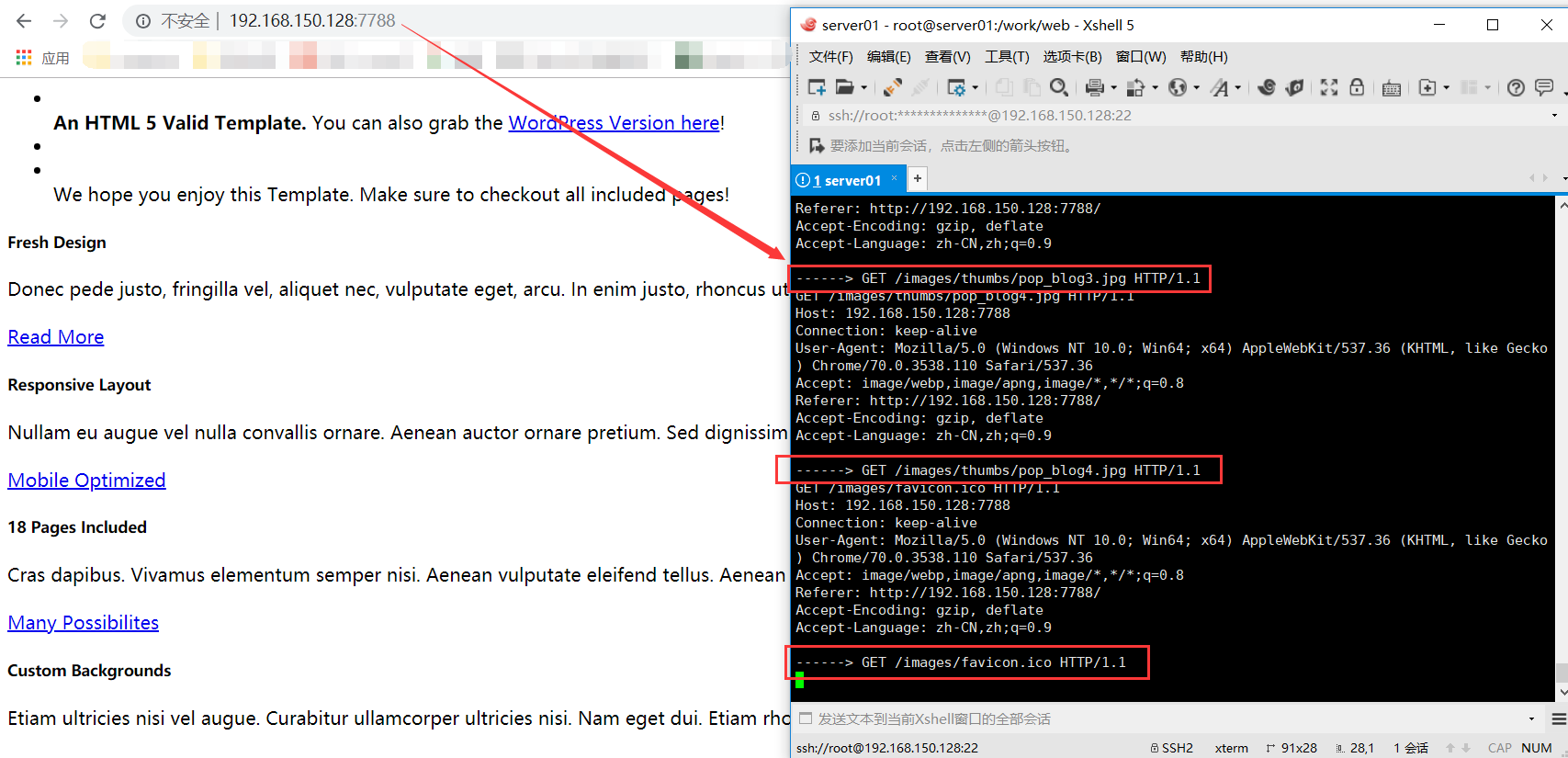
可以从上面的结果来看,我就是需要匹配出以下的内容:
GET / HTTP/1.1 -->
GET /index.html HTTP/1.1 ---> index.html
GET /css/base.css HTTP/1.1 ---> css/base.css
GET /css/skeleton.css HTTP/1.1 ---> css/skeleton.css
根据匹配到的文件,然后拼接路径,到html文件路径中去查找文件,再返回浏览器中。
那么先用ipython编写一下正则,匹配一下先。
In [1]: import re
# [^/] 表示从开头 ^ 匹配到 / 的一个字符,那么就是字符G了
In [7]: re.match(r"[^/]","GET /index.html HTTP/1.1").group()
Out[7]: 'G'
# 增加一个 + 号,匹配所有从开头到 / 的字符,那么就是 GET 空格符号
In [8]: re.match(r"[^/]+","GET /index.html HTTP/1.1").group()
Out[8]: 'GET '
# 那么匹配多一个 / ,然后后面的 index.html 就是应该从 这里作为开头匹配到中间的空格位置
In [9]: re.match(r"[^/]+/[^ ]*","GET /index.html HTTP/1.1").group()
Out[9]: 'GET /index.html'
# 然后去后面那部分作为分组,取第一个分组,就是匹配出来的文件路径了。
In [10]: re.match(r"[^/]+/([^ ]*)","GET /index.html HTTP/1.1").group(1)
Out[10]: 'index.html'
In [11]: re.match(r"[^/]+/([^ ]*)","GET /css/base.css HTTP/1.1").group(1)
Out[11]: 'css/base.css'
In [12]: re.match(r"[^/]+/([^ ]*)","GET /a/b/c/d/base.css HTTP/1.1").group(1)
Out[12]: 'a/b/c/d/base.css'
# 当然空格的那里可以使用 \s 来替代也是可以的。
In [13]: re.match(r"[^/]+/([^\s]*)","GET /a/b/c/d/base.css HTTP/1.1").group(1)
Out[13]: 'a/b/c/d/base.css'
In [14]: re.match(r"[^/]+/([^\s]*)","GET /index.html HTTP/1.1").group(1)
Out[14]: 'index.html'
In [15]:
只要拼接一下html路径,就可以找到对应请求的文件了。
[root@server01 web]# ls
html server.py
[root@server01 web]# ls ./html/css/base.css
./html/css/base.css
[root@server01 web]# ls ./html/index.html
./html/index.html
[root@server01 web]#
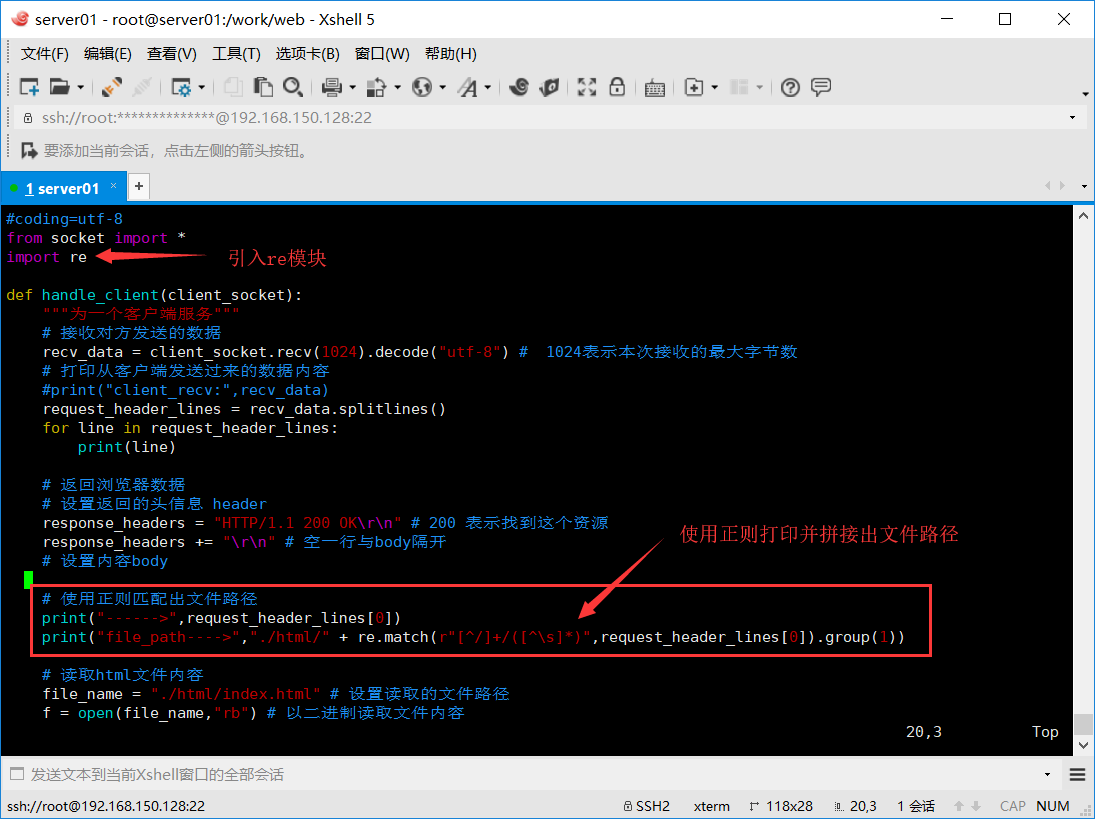
下面就是使用上面的正则规则写入代码中,然后找出文件路径了。

运行如下:
好了,打印出了准备正则的内容,那么下面就可以使用正则匹配出文件路径出来。
运行如下:

好了,到了这里就可以先简单得打开对应的文件,返回浏览器即可。

运行如下:

好啦,写到这里基本上也完成的七七八八啦。剩下就是优化以及bug的调整。
那么到底存在有哪些BUG呢?
简单来看看有哪些BUG需要改改
bug: 存在直接访问无路径的请求,导致服务端意外终止
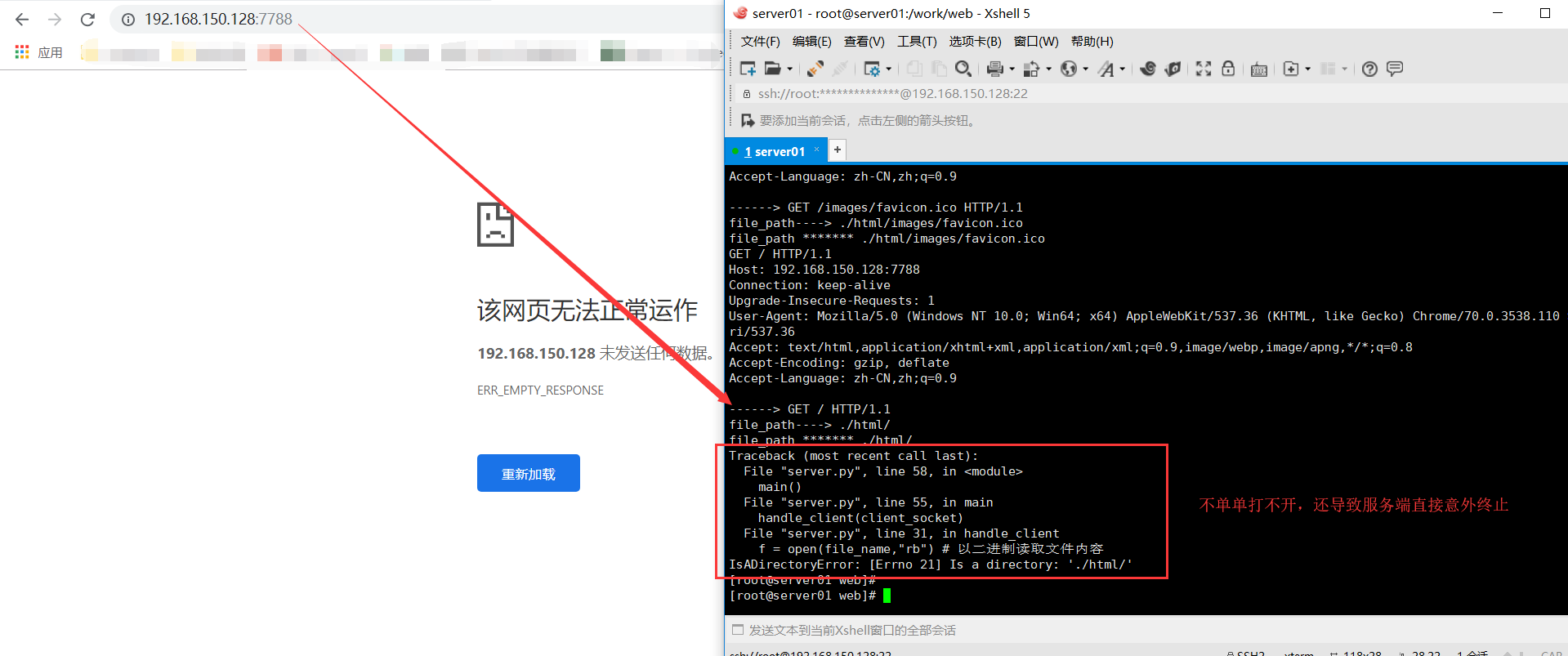

那么修复这个BUG的思路需要做两个时间:
- 第一,就是当匹配到 / 的时候,需要设置 file_path = index.html
- 第二,需要给文件打开的内容部分,做一个异常的捕获,避免直接服务端终止
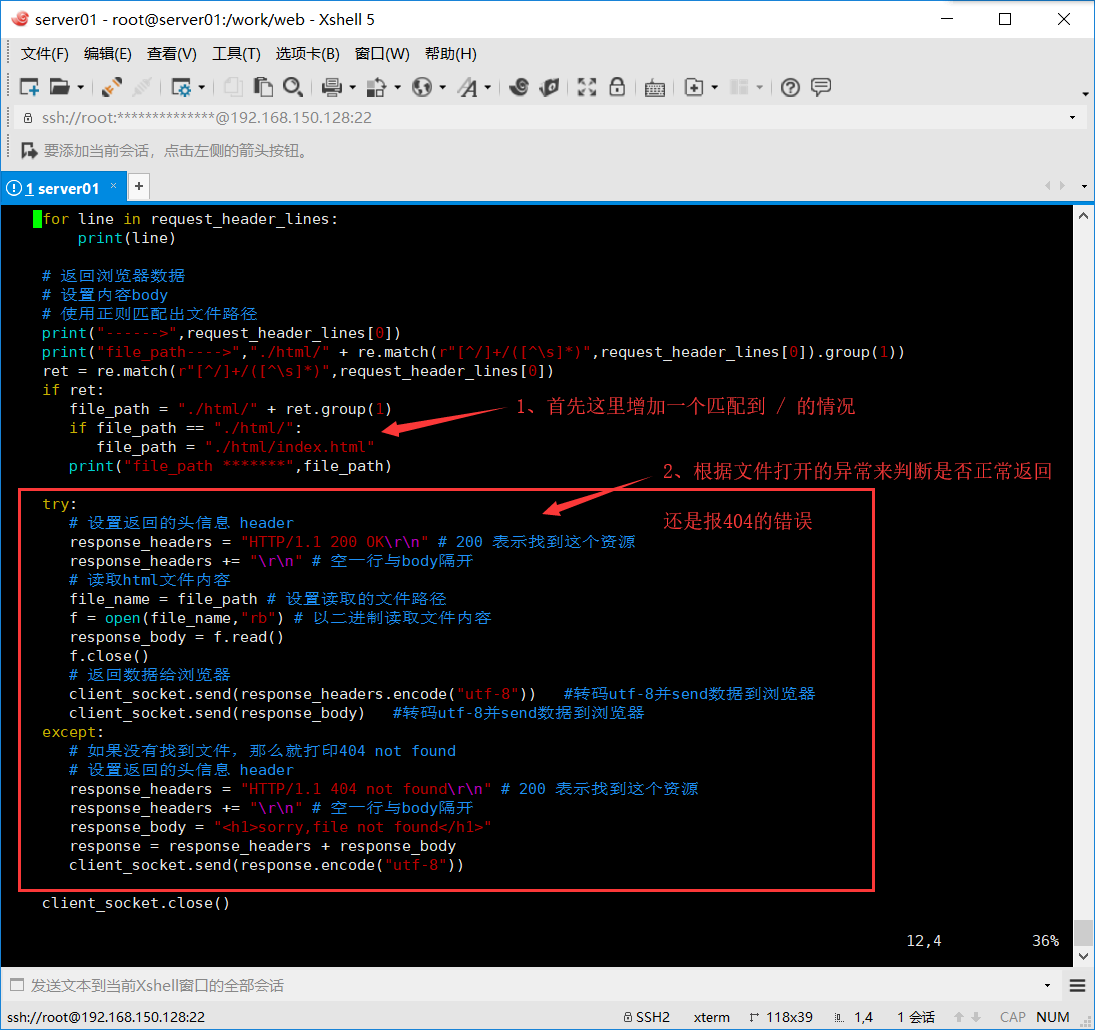
运行测试如下:


好了,到这里基本上大概的功能已经实现了,下一步就是优化服务返回数据的性能。
这方便就是要使用多进程的方式来进行数据返回才能优化了。
这次开发的完整代码如下
[root@server01 web]# cat server.py
#coding=utf-8
from socket import *
import re
def handle_client(client_socket):
"""为一个客户端服务"""
# 接收对方发送的数据
recv_data = client_socket.recv(1024).decode("utf-8") # 1024表示本次接收的最大字节数
# 打印从客户端发送过来的数据内容
#print("client_recv:",recv_data)
request_header_lines = recv_data.splitlines()
for line in request_header_lines:
print(line)
# 返回浏览器数据
# 设置内容body
# 使用正则匹配出文件路径
print("------>",request_header_lines[0])
print("file_path---->","./html/" + re.match(r"[^/]+/([^\s]*)",request_header_lines[0]).group(1))
ret = re.match(r"[^/]+/([^\s]*)",request_header_lines[0])
if ret:
file_path = "./html/" + ret.group(1)
if file_path == "./html/":
file_path = "./html/index.html"
print("file_path *******",file_path)
try:
# 设置返回的头信息 header
response_headers = "HTTP/1.1 200 OK\r\n" # 200 表示找到这个资源
response_headers += "\r\n" # 空一行与body隔开
# 读取html文件内容
file_name = file_path # 设置读取的文件路径
f = open(file_name,"rb") # 以二进制读取文件内容
response_body = f.read()
f.close()
# 返回数据给浏览器
client_socket.send(response_headers.encode("utf-8")) #转码utf-8并send数据到浏览器
client_socket.send(response_body) #转码utf-8并send数据到浏览器
except:
# 如果没有找到文件,那么就打印404 not found
# 设置返回的头信息 header
response_headers = "HTTP/1.1 404 not found\r\n" # 200 表示找到这个资源
response_headers += "\r\n" # 空一行与body隔开
response_body = "<h1>sorry,file not found</h1>"
response = response_headers + response_body
client_socket.send(response.encode("utf-8"))
client_socket.close()
def main():
# 创建套接字
server_socket = socket(AF_INET, SOCK_STREAM)
# 设置当服务器先close 即服务器端4次挥手之后资源能够立即释放,这样就保证了,下次运行程序时 可以立即绑定7788端口
server_socket.setsockopt(SOL_SOCKET, SO_REUSEADDR, 1)
# 设置服务端提供服务的端口号
server_socket.bind(('', 7788))
# 使用socket创建的套接字默认的属性是主动的,使用listen将其改为被动,用来监听连接
server_socket.listen(128) #最多可以监听128个连接
# 开启while循环处理访问过来的请求
while True:
# 如果有新的客户端来链接服务端,那么就产生一个新的套接字专门为这个客户端服务
# client_socket用来为这个客户端服务
# server_socket就可以省下来专门等待其他新的客户端连接while True:
client_socket, clientAddr = server_socket.accept()
handle_client(client_socket)
if __name__ == "__main__":
main()
[root@server01 web]#
有兴趣的朋友可以下载一个建站的模板html来尝试一下,编写一个web服务端。

关注微信公众号,回复【资料】、Python、PHP、JAVA、web,则可获得Python、PHP、JAVA、前端等视频资料。
















 1539
1539











 企业员工
企业员工




























 到【灌水乐园】发言
到【灌水乐园】发言












「已注销」: 不管进厂还是创业,要走出门和人交流才是真道理。
是晨星啊: 建议加上编码 fh = logging.FileHandler(logfile, mode='a', encoding='utf8')
代码拯救不了世界: 你这里面先贴了代码的截图,然后又把代码复制上去了,不是有点多此一举吗,要是截图就截图呗,要是代码块就代码块呗,留一个就可以了,看半天文章一半都是重复的
永远微笑的凯神: 我就在本机上运行的
永远微笑的凯神: 不行,0.0.0.0还是只能127.0.0.1访问