Python写一个简易的web服务器

 最新推荐文章于 2024-04-28 01:03:04 发布
最新推荐文章于 2024-04-28 01:03:04 发布
 阅读量7.1k
阅读量7.1k
 收藏
23
收藏
23


 点赞数
4
点赞数
4

Greg Wilson是Software Carpentry(为科学家和工程师提供在计算技能方面的速成课程)的创始人。他已经在学术界和工业界工作了30年,是几本计算方面的书,包括获得2008年jolt奖的《代码之美》和《开源应用程序体系结构》的前两卷的作者或者编辑。Greg于1993在爱丁堡大学获得了计算机科学博士学位。
介绍
在过去的二十年里,网络已经改变了社会的方方面面,但是它的核心变化很少。大多数系统仍然遵守Tim Berners-Lee在25年前提出的规则。特别是,大多数web服务器仍然按照以前同样的方式处理同种类的消息。
本章将探讨他们如何做到这一点。与此同时,它将探索开发人员如何创建不需要重新写入来添加新特性的软件系统。
更多Python视频、源码、资料加群683380553免费获取
背景
几乎网络上的每一个程序都在以互联网协议(IP)为通信标准运行。我们关心的其中一个通信标准是传输控制协议(TCP/ IP),它使得计算机之间的通信看起来像读写文件。
使用IP网络协议的程序通过sockets(套接字)进行通信。每个socket(套接字)是一个点对点通信信道的一端,就像一个电话机是一个电话呼叫的一端。一个socket(套接字)由一个定义了特定机器和其端口号的IP地址构成。 IP地址由4个8位的数字构成,例如174.136.14.108(10100100.10001000.00001110.01101100);域名系统(DNS)把这些数字匹配给像aosabook.org这样便于人们记忆的符号名。
端口号是0-65535范围内的数字,定义了主机上的唯一的socket(套接字)。 (如果IP地址比作一个公司的电话号码,那么端口号就像是分机。)端口0-1023被保留用于操作系统的使用;任何人都可以使用剩余的端口。
超文本传输协议(HTTP)描述了一种程序通过IP交换数据的方法。 HTTP很简单:客户端发送一个请求,指明它想通过socket(套接字)连接获得的内容,然后服务器发送一些数据作为响应(如图22.1)。数据可以从磁盘上的文件复制,或由程序动态生成,或两者的结合。

一个HTTP请求的最重要的事情是,它只是文本:任何程序只要想要就可以创建或解析一个。不过,为了理解它,该文本必须含有如图所示的部分。

HTTP方法几乎总是“GET”(获取信息)或“POST”(提交表单数据或上传文件)。 URL指定客户端想要什么;它通常是磁盘上文件的路径,如/research/experiments.html,但(这是至关重要的一部分)它完全取决于服务器来如何处理它。HTTP版本通常是“HTTP / 1.0”或“HTTP / 1.1”;两者之间的差异对我们来说并不重要。
HTTP头文件是“键/值”对,如下面三行所示:
Accept: text/html
Accept-Language: en, fr
If-Modified-Since: 16-May-2005
不像在哈希表中的键,键可能会在HTTP头文件中出现任意次数。这允许request指定它想要接受的多种类型的内容。
最后,请求的主体是任何与请求相关以外的数据。这用于通过网页表单提交数据,上传文件等等的时候。在最后一个头和主体开头之间必须有一个空白行表示头文件的结束。
一个叫Content-Length的头文件,在请求主体中告诉服务器请求读取多少字节。
HTTP响应格式类似于HTTP请求(如图22.2):

版本,头文件和主体具有相同的形式和意义。状态码是一个数字,表示在处理请求的时候发生了什么:200的意思是“一切正常”,404表示“未找到”,以及其他代码有其他的含义。状态语以人类可读短语复述信息,如“OK”或“未找到”。
作为本章的目的,我们只需要了解HTTP的两点。
首先,它是无状态的:每个请求是自己处理自己,服务器不记得一个请求与下一个请求之间的任何事情。如果应用程序想要跟踪什么如一个用户的id,就必须自己跟踪。
追踪常用的方法是使用cookie,它是一个从服务器端发送到客户端然后客户端稍后再返回到服务器端的短字符串。当用户执行一些需要保存跨越多个请求的状态的功能时,服务器会创建一个新的cookie,并存储在数据库中,并且将其发送到她的浏览器。每次她的浏览器将cookie发送回去,服务器会用它来查看用户正在做什么。
我们需要了解HTTP的第二件事是,一个URL可以用参数来补充,以提供更多的信息。举个例子,如果我们使用搜索引擎,我们不得不指定我们的搜索词是什么。我们可以把这些添加到URL路径中,但我们应该做的是把参数添加到URL。我们通过添加 “?”做到这点,后面跟着以"&"分隔的“key=value”对。例如,URL http://www.google.ca?q=Python要求谷歌来搜索Python相关的网页:key值是字母“q”,value值为“Python。较长的查询http://www.google.ca/search?q=Python&client=Firefox告诉Google我们正在使用Firefox,等等。我们可以传递任何我们想要的传递的参数,但同样,它是由在网站上运行的应用来决定要注意哪些参数,以及如何解释它们。
当然,如果 "?"和"&"是特殊字符,必须有方法避开他们,就是必须有个方法来把一个双引号字符放进用双引号限定的字符串内。 URL编码标准用%后面跟着2位的代码代表特殊字符,并以"+"字符代替空格。因此,搜索Google“grade= A+”(有空格),我们应该使用URL http://www.google.ca/search?q=grade+%3D+A%2B。
打开sockets,构建HTTP请求,解析响应是乏味的,所以大多数人使用库来完成大部分的工作。 Python提供了这样一个称作urllib2的库(因为它是一个较早版本的库urllib的升级版),但它暴露了很多大多数人永远不想关注的底层编码。Requests库比urllib2更容易使用。下面是一个使用它从AOSA图书网站下载页面的例子:

request.get发送一个HTTP GET请求到服务器,并返回一个包含响应的对象。该对象的status_code成员是响应的状态码;它的content_length成员是响应数据中的字节数,text是实际的数据(在这种情况下,是一个HTML页面)。
hello,web
现在,我们准备写我们的第一个简单的Web服务器。基本思想非常简单:
1.等待有人来连接我们的服务器,发送HTTP请求;
2.解析请求;
3.找出它的要求;
4.获取数据(或动态生成它);
5.把数据格式化为HTML;
6.回发。
从一个应用程序到另一个,步骤1,2和6是相同的,所以Python标准库有一个名为BaseHTTPServer的模块为我们做这些步骤。我们只需要关注步骤3-5,这是我们在下面的小程序里做的:
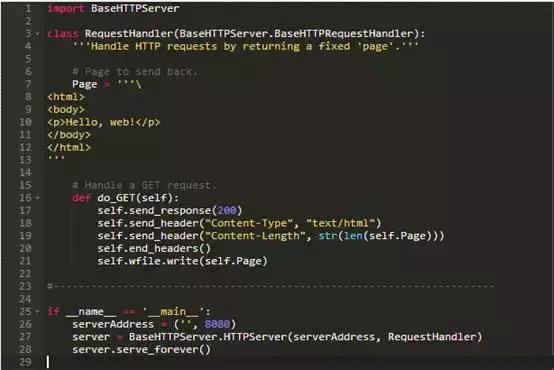
库的BaseHTTPRequestHandler类负责解析传入的HTTP请求,并判断它含有什么方法。如果方法是GET,类调用一个名为do_GET的方法。我们的RequestHandler类覆盖此方法来动态生成一个简单的页面:文本被存储在类级别的变量Page中,在我们发送一个200响应码后被发回客户端,Content-Type头文件,告诉客户端把我们的数据和页面长度翻译为HTML格式。 (调用end_headers方法插入空白行,来区分头文件和页面本身。)
但RequestHandler并不是故事的全部:我们还需要最后三行来使服务器开始运行。其中第一行定义服务器的地址为一个元组:空字符串意味着“在当前计算机上运行”,8080是端口号。然后,我们创建一个BaseHTTPServer.HTTPServer的实例,实例中含有服务器地址和我们的请求处理类作为参数的名称,然后要求它永久运行(这实际上意味着,直到我们使用Control-C杀死它才停止运行)。
如果我们在命令行中运行这个程序,它不显示任何内容:
$ python server.py
然后如果我们用我们的浏览器访问http://localhost:8080,那么,在浏览器中我们得到这样的内容:
Hello, web!
在我们的shell中是这样的内容:
127.0.0.1 - - [24/Feb/2014 10:26:28] "GET / HTTP/1.1" 200 -
127.0.0.1 - - [24/Feb/2014 10:26:28] "GET /favicon.ico HTTP/1.1" 200 -
第一行是直观的:因为我们没有要求特定文件,我们的浏览器就要求"/"(服务器提供所有的根目录)。出现第二行是因为我们的浏览器会自动发送第二个请求来请求一个名为/favicon.ico的图像文件,如果图像文件存在,它会在地址栏显示为一个图标。
显示数值
让我们修改我们的Web服务器来显示一些包含在HTTP请求中的值。 (在调试的时候,我们会相当频繁的做这个,所以我们不妨做一些练习)。为了保持我们的代码简洁,我们将把创建页面和发送页面分开:
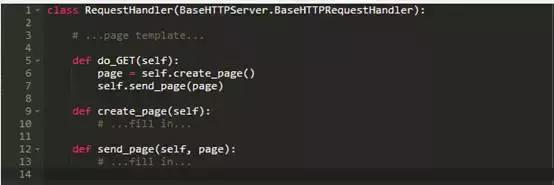
send_page我们之前几乎都有的:

因为我们要显示的页面模板仅仅是一串字符串,字符串包括带有一些格式占位符的HTML表:

填充方法是:
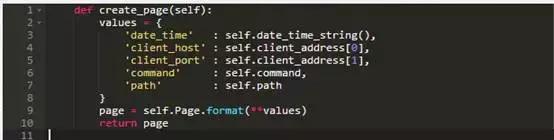
该程序的主体是不变的:和以前一样,它创建了一个HTTPServer类的实例,实例中含有一个地址和作为参数的请求处理器,然后永久服务请求。如果我们运行它,并从浏览器中发送一个请求:http://localhost:8080/something.html,我们得到:
Date and time Mon, 24 Feb 2014 17:17:12 GMT
Client host 127.0.0.1
Client port 54548
Command GET
Path /something.html
请注意,我们没有收到一个404错误,即使something.html页面文件在磁盘上不存在。这是因为Web服务器只是一个程序,当它获得一个请求时,它可以做任意想做的事:发回在先前的请求里被命名的文件、提供随机选择的一个维基百科页面,或我们编写的任意的东西。
提供静态页面服务
明显的,下一步是从磁盘启动服务页面,而不是动态生成。我们会通过改写do_GET来开始:

该方法假定提供Web服务器运行目录下的任何文件都是被允许的(使用os.getcwd函数来获得当前运行目录)。它把当前运行目录与URL提供的路径(库将路径自动放入self.path中,并始终以 “/”开头)相结合,来获得用户想要文件的路径。
如果路径不存在,或者如果它不是一个文件,该方法通过抛出和捕获异常报告错误。如果路径匹配一个文件,在另一方面,它调用一个帮助者方法命名为handle_file来读取和返回内容。这种方法只会读取文件,并使用我们现有的send_content将其发送回客户端:

请注意,我们在以二进制模式打开文件—the "b" in "rb"—,因此Python不会帮我们去通过改变字节序列而使其看起来像一个Windows结束行。还需要注意的是在现实生活中,当为它服务时,读取整个文件到内存是个坏主意,该文件可能是数千兆字节的视频数据。处理这种情况不在本章的范围之内。
为了完成这个类,我们需要编写错误处理方法和错误报告页面模板:
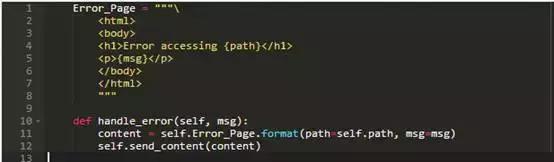
这个程序可用,但前提是我们别太细看。问题是,它总是返回状态码200,即使当被请求的页面不存在。在这种情况下,发回的页面包含一个错误信息,但由于我们的浏览器读不懂英文,它不知道该请求其实失败了。为了说清楚这点,我们需要按如下修改handle_error和send_content:

请注意,当找不到文件时我们不抛出ServerException,而是产生一个错误页面。ServerException是为了传递服务器代码中的内部错误信号,即,我们弄错了某东西。在另一方面,通过handle_error创建的错误页面,出现在用户犯了一些错误的时候,即,给我们发送了一个不存在的文件的URL。(1)
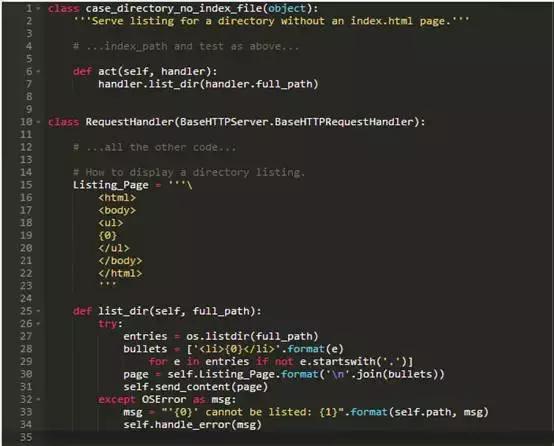
列出目录
作为我们的下一步,当URL中的路径是一个目录而不是文件时,我们可以教Web服务器显示目录列表。我们甚至可以更进一步,让它在那个目录中以index.html文件显示,并且文件不存在时,只显示目录内容的列表。
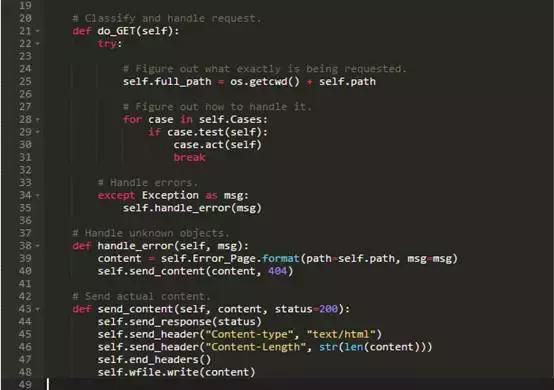
但是,把这些规则写进do_GET将是一个错误,因为方法最终将会成为长长一大团控制特定行为的if声明。正确的解决办法是退后一步,解决一般性问题,指出如何处理URL。这里是重写的do_GET方法:
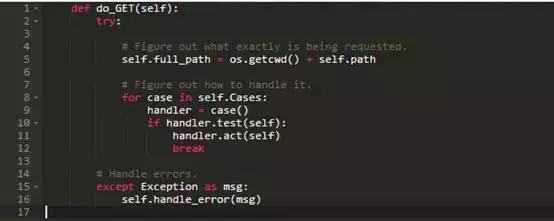
第一步是一样的:指出被请求的东西的全路径。尽管在那之后,代码看起来相当不同。该版本遍历一组存储在列表中的cases类来代替一堆的内联测试。每个case是一个有两个方法的对象:方法test,它告诉我们它是否能够处理请求,方法act,它实际上采取了一些行动。我们一找到正确的case,我们马上让它处理请求并跳出循环。
这三个case类复制我们之前服务器的行为:
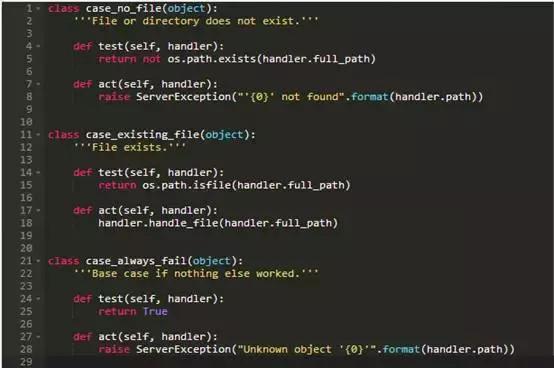
如下是我们如何在RequestHandler类的顶部构建case handlers的列表:

现在,表面上看这使得我们的服务器更加复杂,而不是更简单:该文件已经从74行增加至99行,并且有额外的间接寻址,没有增加任何新的功能。这样做的好处是,当我们回到那个本章开始的任务,如果有文件的话,就尝试教我们的服务器来提供index.html页面作为目录,如果没有的话,就提供目录的列表。前者的handler程序是:
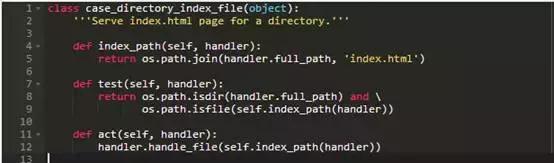
在这里,帮助者方法index_path构建index.html文件的路径;把它放进case handler中防止主函数RequestHandler杂乱。 test检查路径是否是包含index.html的目录,act要求主函数请求处理器提供该页面。
唯一需要RequestHandler改变的是把一个case_directory_index_file对象添加到我们的Cases列表中:

如果目录中不包含index.html页怎么办呢?test方法和上面战略性插入not相同,但act方法该怎么样呢?他该怎么做?
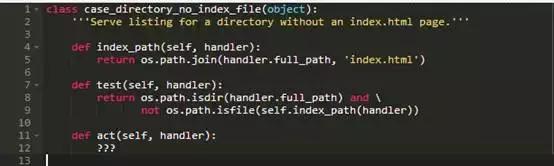
我们似乎陷入了困境。从逻辑上讲,act方法应创建并返回目录列表,但是我们现有的代码不允许:RequestHandler.do_GET调用了act,却并不想要或处理返回值。现在,让我们在RequestHandler里添加一个方法来生成一个目录列表,并从case handler的act方法调用该方法:
CGI协议
当然,大多数人都不会想要编辑他们的网络服务器的源代码来增加新的功能。为了从这种不得不这么做的泥沼中解脱出来,服务器一直支持一个叫做通用网关接口(CGI)的机制,这为Web服务器为了满足请求去运行外部程序提供了一种标准方法。
例如,假设我们希望服务器能在HTML页面中显示本地时间。我们在只有几行代码的独立的程序中就可以做到:

为了使Web服务器运行该程序,我们添加如下的case handler:
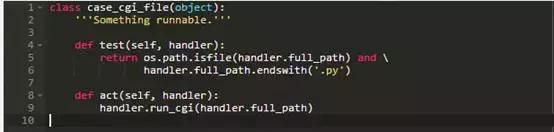
test方法很简单:文件路径是以.py结尾吗?如果是,RequestHandler运行此程序。

这是非常不安全的:如果有人知道我们的服务器上的一个Python文件的路径,我们就只能任他们运行它,不管它访问了什么数据,它是否包含了一个无限循环,或任何其他什么(2)
先不管那个,核心的思想很简单:
1.在子进程中运行程序。
2.捕获任何子进程发送到标准输出的内容。
3.把内容发送回发出请求的客户端。
完整的CGI协议比这个要丰富的多-尤其是它允许url中服务器传递给程序的参数运行-但这些细节不影响系统的整体架构...这再次变得相当乱。 RequestHandler中最初有一个方法handle_file,用于处理内容。现在,我们已经在list_dir和run_cgi表中加入了两种特殊情况。这三个方法并不真正在所属类起作用,因为他们主要由其他方法使用。
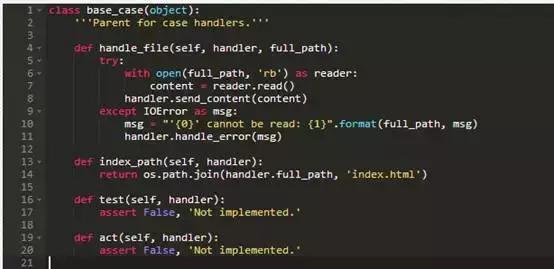
修补程序很简单:为所有的case handler创建一个父类,当(且仅当)他们由两个或多个handler共享时,把其他方法移入这个类。当我们完成后,RequestHandler类看起来是这样的:
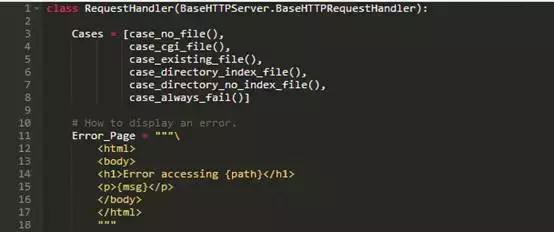
与此同时case handler的父类是:
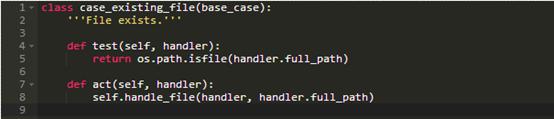
现有的文件(只是挑选随机的一例)的handler是:
讨论
我们原始代码和重构版本之间的差异反映了两个重要思想。首先是考虑类作为相关服务的集合。services.RequestHandler和base_case不作决定或采取行动;它们提供让其他类使用去做这些事的工具。
第二个是可扩展性:人们可以通过编写一个外部CGI程序,或通过添加一个case处理器的类,来给我们的Web服务器添加新功能。后者确实需要更改RequestHandler的一行(在Cases列表插入case handler),但我们可以通过Web服务器读取一个配置文件和负载handler类来避免。在这两种情况下,它们可以忽略更低层级的细节,正如BaseHTTPRequestHandler类的作者已经允许我们忽略处理套接字连接和解析HTTP请求的细节。
这些想法通常是有用的;看看你能不能想办法在自己的项目中使用它们。
-------------------------------------------------------------------------------------------------------------------
1.在本章中,包括一些情况下,状态代码404不合适的地方,我们会好几次使用handle_error。当你继续阅读,试着想想你将如何扩展程序使状态响应代码可以很容易地在每种情况下被提供
2.我们的代码还使用了popen2库函数,该函数为支持subprocess模块已经被弃用了。然而,在这个例子中,popen2是较少分散使用的工具。














 3353
3353











 暂无认证
暂无认证


















 到【灌水乐园】发言
到【灌水乐园】发言










長ずる: sum_num = 0 for i in range(100,401): if i % 3 == 2 and i % 5 == 3: sum_num += i print(sum_num)
宽度307: 一位沙发
2401_83950345: 求出100到400之间同时满足除以3余2和除以5余3的数的和。我们用的是python。🥺🥺
2401_83950345: 作者大大,呜呜呜,我们老师留了一道题不会做,想请你帮忙可以吗🥹
lckj2009: text = recognizer.recognize_google_cloud(audio, language='zh-CN')这个接口就是报错啊。博主,怎么办? assert os.environ.get('GOOGLE_APPLICATION_CREDENTIALS') is not None