大数据开放平台搭建,难点何在?

 最新推荐文章于 2023-04-18 09:41:15 发布
最新推荐文章于 2023-04-18 09:41:15 发布
 阅读量198
阅读量198
 收藏
1
收藏
1


 点赞数
点赞数
编者按:Hadoop于2006年1月28日诞生,至今已有10年,它改变了企业对数据的存储、处理和分析的过程,加速了大数据的发展,形成了自己的极其火爆的技术生态圈,并受到非常广泛的应用。在2016年Hadoop十岁生日之际,InfoQ策划了一个Hadoop热点系列文章,为大家梳理Hadoop这十年的变化,技术圈的生态状况,回顾以前,激励以后。本文整理自去年4月份的QCon大会演讲“以Hadoop为核心的大数据开放平台建设”。\
大数据发展趋势
\大概在08年左右,Hadoop从Nuch里的一个package开始的独立出来,不断的被大家所关注,它本身不断的进化,包括对压缩算法的Native实现,Checksum机制的优化,还有ShortCircuit Read(支持直接文件的内置的短读),这算是读取性能的优化。在这些不断的优化下,Hadoop逐渐变得健壮。Hadoop的2.3版本,是一个架构上的根本变化,把资源管理提到了一个很高的高度,就是我们新一代的Yarn\u0026amp;Mapreduce2.0。还有一个HDFS上的架构优化,就是NameNode Federation。NameNode分布式管理,可以极大的增进机群的可扩展性。\
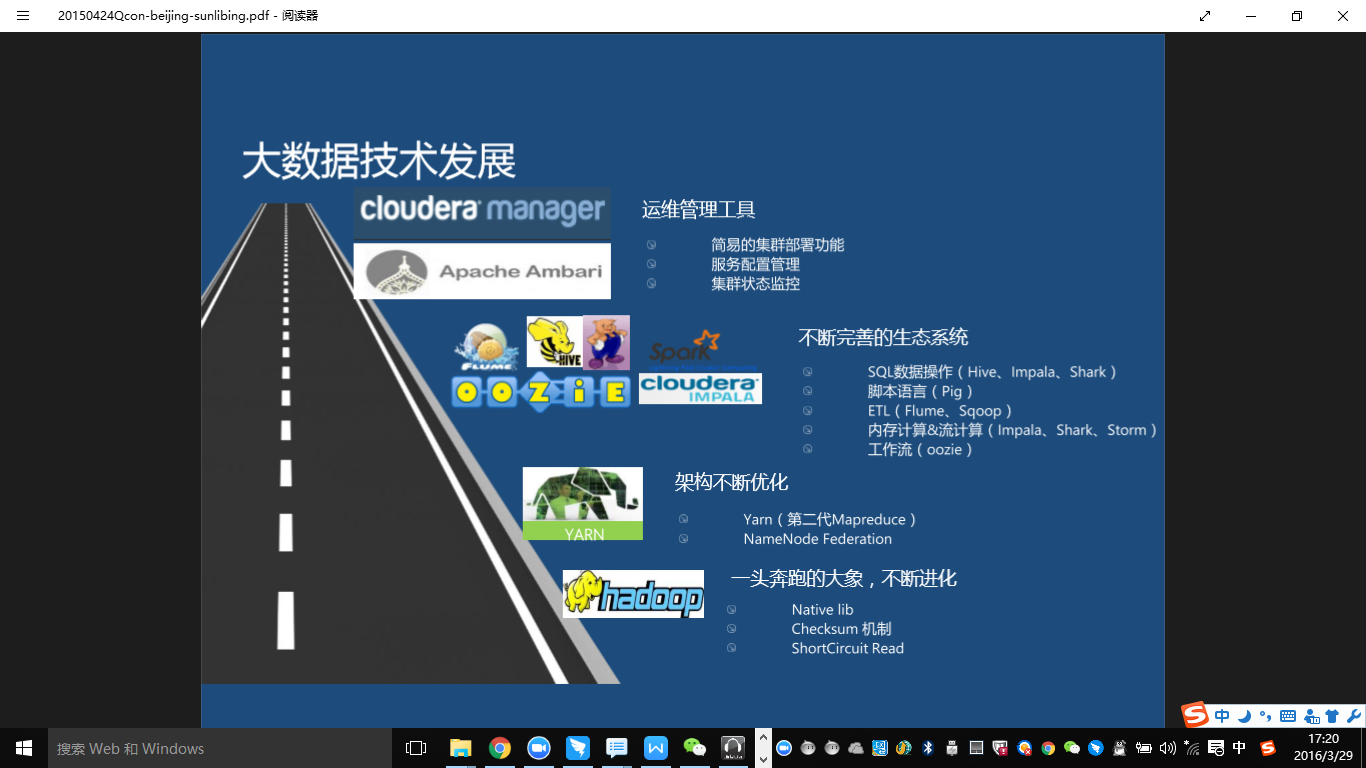
Hadoop本身不断完善,围绕着Hadoop的生态系统也在不断的完善,像Oozie,就是与Hadoop结合非常紧密的一个工作流引擎;Flume是围绕Hadoop的日志收集类的ETL工具;Hive是一个SQL On Hadoop的实现,也是最早的一个实现,现在已经有很多了;Pig类似Hive,但是是一个内置脚本、有自己独立语法,相对来说是一个优化版的Hive实现。但是它的语法,相对来说要比Hive性能高一些,在Facebook内部使用比较多。另外Cloudera推出了SQL On Hadoop的Impala的实现。另外还有Spark 也是新兴的一个内存计算模型的技术。\
大数据技术应用,困难何在?
\围绕着Hadoop的周边的生态系统在不断的完善,运维管理工具上也得到了极大的进展。因为在早期,大家部署一个Hadoop系统会非常麻烦;从08年到现在,我经历过大大小小的系统,自建的,内建的,包括公司各种平台项目里面建的,不计其数,特别的辛苦。包括脚本,权限设置,一些目录权限的设置,安装一个系统大概要半天左右到一天左右时间。非常熟练之后也要半天左右时间。现在像Apache Ambari,Cloudera Manager,已经把整个机群的部署变得非常简单,基本上几分钟就能把我们需要花几十分钟的机群部署起来,甚至是一个几十台机器规模的机群。\
大数据技术在不断的发展,但是它还是有些天生的不足。首先是技术本身在百花齐放,生态系统里面的技术在不断的完善,包括Hadoop,Hive,Spark等等,那么就会存在选择上的困难--如何应用好每一项技术,就是一个难题。另外,大数据技术本身内部的融合性也是不太够的。现在有一种趋势,每一个开源工具都在强调自己的性能有多好,都想围绕着自己去建立生态系统。另外就是怎么合理的使用这些技术。比如说我们以前的系统是围绕着一种技术建立的,然后又引入了一个新的技术,两个技术怎么实现融合,这就是一个很大的难题。\
另外一个就是大数据技术与其他传统技术的融合性不够。传统技术,比如以前使用的数据库,一些其他的服务,Solr检索服务什么的,也没有成熟的融合方案。在实践中会比较陌生,没有一套成熟的体系支撑。你可能需要去翻很多的文档,自己做很多开发,才能实现这些功能。那么我们现在缺少什么呢?缺少一个能融合现有大数据技术的技术,这个真的是非常非常关键的。\
技术领域是怎么来面对这个问题的?
\大概在13年,Doug cutting做过一次技术分享,The State of the Apache,这个文档大家可以在百度百库上可以检索到。他当时提出了一个概念叫Apache Hadoop Ecosystem。Ecosystem,E应该是代表Easy,CO是Cross,System系统平台。这在他的论文里面摘录的几句关键的话。\
文档本身的介绍非常简单,寥寥几页,但很经典。我觉得他说得非常在点子上。我的解读,这个总体来说应该是这样一个思想:以Hadoop为核心,融合其他技术的平台级系统,Avro将是实现融合技术的关键技术。\
在行业内,Cloudera应该是Hadoop就是围绕着大数据Big Data这种解决方案的一个国外很有影响力的一个公司。Cloudera是在做Hadoop的应用体现,想让Hadoop越来越容易被大家所应用。他提供了两个解决方案。首先,建立了Hue这套系统,提出Use Hadoop with Hue。另外就是Administer Hadoop,就是运维管理Hadoop。建立了叫Cloudera Manager这一整套的工具。像Hue和Administer已经是说解决了两方面的问题,Hue用来调度管理任务。Administer是管理和运维平台。\
这是Cloudera给出的答案,在科大讯飞的实际开发过程中,我们是怎么应付和解决这些难题的呢?我们围绕着Doug Cutting提出的ECoSystem的思想上,我们也开始逐渐建立自己的大数据开放平台Maple。\
我们的实现以数据导向为理念。数据导向为理念是一个思想。以前我们在做一件事情的时候都会考虑,做这件事情要使用什么样的技术。因为首先大数据是围绕着数据去做的,很多时候会偏离数据,而去考虑很多技术的细节问题。但是在做实际业务开发的过程中,我们需要围绕着数据去想问题,而不是围绕着技术去想问题,这就是需要数据导向为理念。我们所有的业务开发围绕着数据,数据是什么样的,我们就怎么处理。整个系统平台是以Hadoop为核心,这也是符合Doug Cutting提出的EcoSystem的思想。\
最后我们提出了以EcoSystem设计理念,以Hadoop为核心,融合优秀的技术,因地制宜的使用技术。综合来看,每个技术都有它的特长,因地制宜的使用技术,才能让这个技术得到更好的发挥。我们还需提升大数据的应用体验。如果你是早期接触的话,在它上面开发任务,提交任务,整个的流程管理是相当复杂的。\
科大讯飞的大数据平台
\我们大数据开放平台分成三部分。1.基础机群,围绕着Cloudera发行版本CDH来构建的。2.我们上层构建了自己的Maple SDK,是面向开发者提供的开发包。3.是Maple BDWS。\
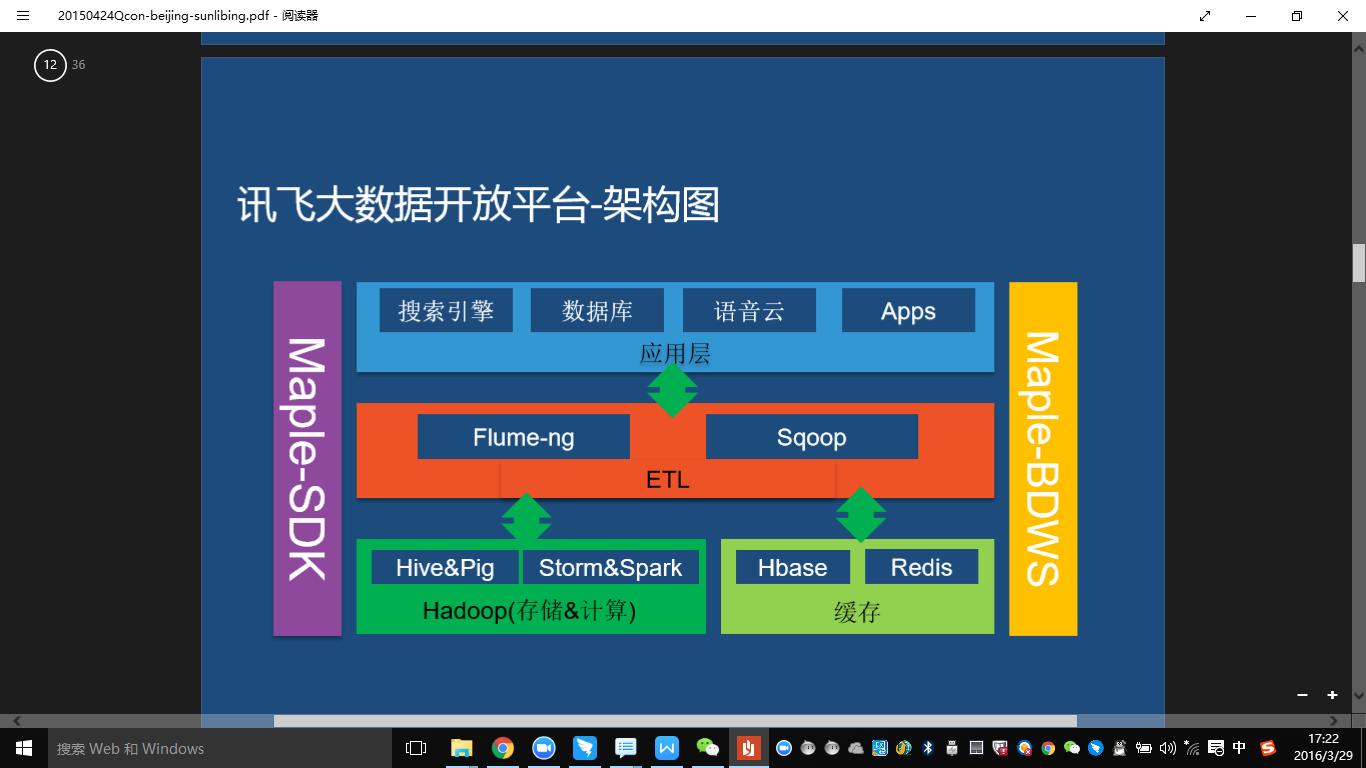
大数据平台的整个的架构。\
从上层的应用层到ETL层,到我计算和存储层,这是整个的数据流。以这个上面的这些设计为基础开展大数据开放平台的工作。非常的值得去借鉴是我们架构上不仅定义了数据流向,也定义了开发的过程,Maple BDWS应该是我们整个大数据开放平台的一个门户,解决代码托管,编译部署,工作流设计,任务调度,数据和任务信息浏览。特性:支持多集群管理,支持多版本Hadoop,支持多项目管理,在线编译部署(one button to use)。整个平台是用Python去做的,支持了Python扩展。可以在线的测试和运行Python的代码。\
Maple BDWS是我们整个大数据开放平台的一个门户,Maple SDK就是我们整个大数据开放平台的灵魂。\
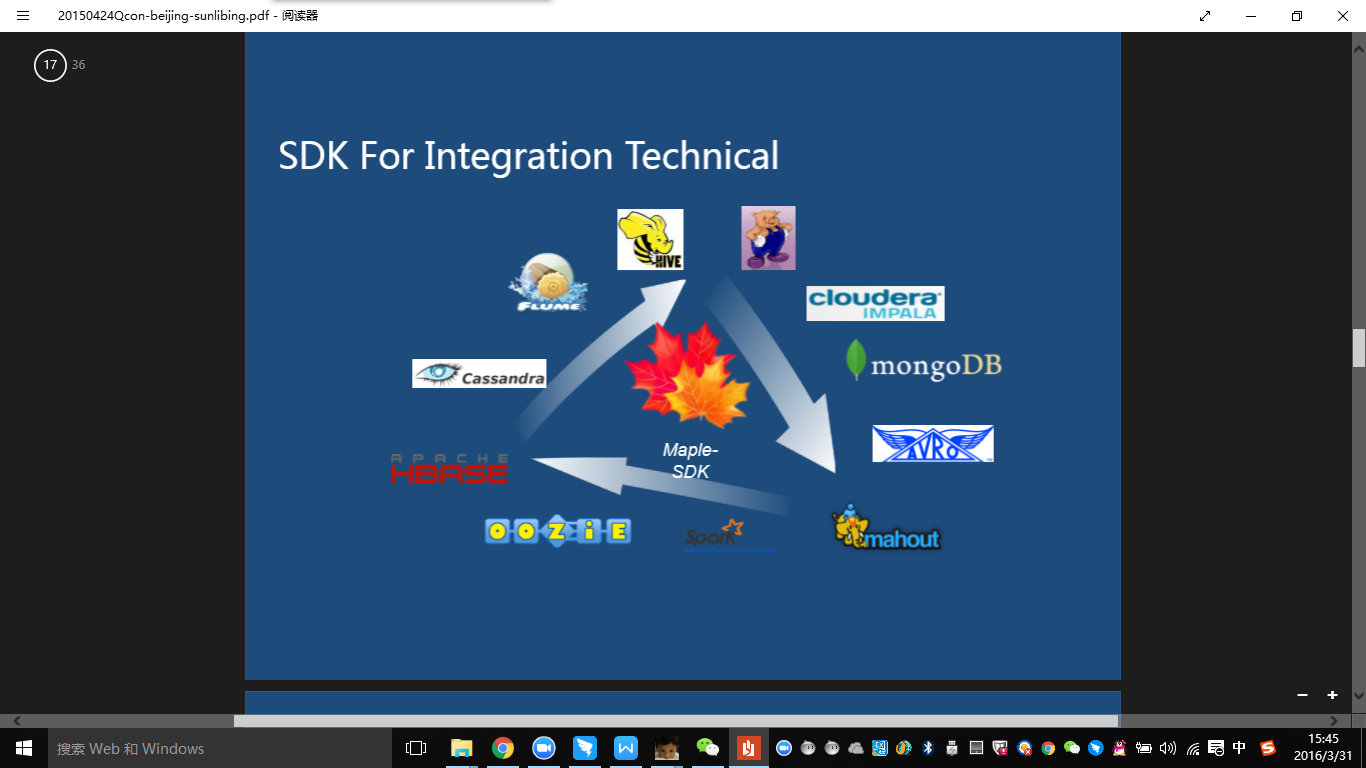
在设计SDK的时候,我们的目标是为了实现Integration Technical,就是融合技术,希望能把各种技术都提供一种标准的开发方式,开发模板。通过在实践中应用成熟以后,把开发模式,融合的编码规范分享出去。围绕着SDK,我们融合了Hbase,oozie,Flume、Avro这样的技术。SDK里面包含一套数据建模的功能,基于Avro的Mapreduce编程库。还有一套Flume-ng的扩展组件。统计分析也是一个常见的业务,Maple-Report是一个统计分析解决方案。另外还含有一个分布式索引的库,叫Maple-Index。大数据建模系统Data Source,适用于大数据的动态自动建模系统。\
实现技术融合的关键
\用大数据的眼光看数据,会跟平常我们看数据会有什么不同呢?用大数据的眼光看数据,会发现数据会分成两种基本属性。一个是Schema,一个是Partition。在Partition和Scheam下应该支持多种文件的数据存储格式,包括文本格式,Avro格式,列存储,数据库文件。\

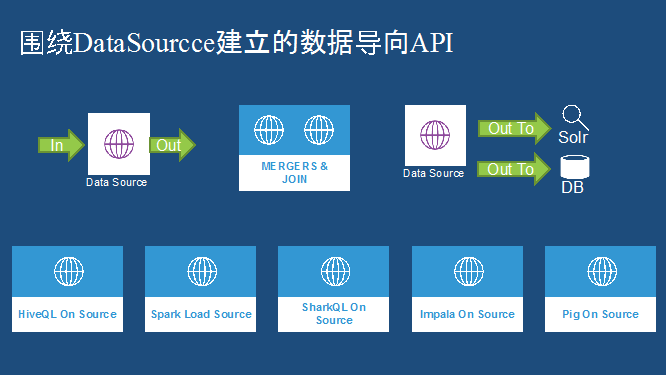
Avro是融合整个技术的关键,在我们内部大量使用了Avro的数据存储格式。我们要围绕着DataSource去建立数据导向的API,提供一个清洗过程的API。另外提供两个DataSource实现Merg和Join的功能。还围绕DataSource实现跟外部数据这种交互。建立了HiveQL On Datasource这样的API,支持Spark去Load处理,Impala On Datasource,Pig On Datasource等。\
了解Avro可以看官网的Introduction。Avro经常会被跟Thrift和Protobuf这两个序列化系统做比较。因为Avro本身也是一个序列化系统。那么我们就要提出一个问题,在Thrift和Protobuf已经很成熟的这种基础上,为什么要选择Avro?在08年,10年左右,我关注这个项目,后来发现所有的代码的提交修改记录,全是Doug Cutting,里面有90%的工作都是Doug Cutting本人去做的。Doug Cutting早期是Lucene的项目的创始人,也是Hadoop的创始人,一手把Hadoop开源项目带起来,甚至都是他亲身去开发的。他花费那么多精力去搞Avro,必有其独到之处。\
Avro开发中代码生成是可选的,这是一个跟其他系统,就是跟Thrift和Protobuf有很大区分的一个特性。另外Avro支持通用数据读取,不依赖于代码生成。有了这两个特性,Avro就更能适应大数据变化的特性。Doug Cutting当时是在Thrift和Protobuf很成熟的基础上开始着手建立Avro的,是非常有想法的。\
Avro在讯飞大数据开放平台的应用
\首先我们有一套Avro-Mapreduce编程框架,围绕Avro这种Mapreduce开发。Avro为整个Mapreduce过程提供了高性能的数据系列化,是在整个Mapreduce生命周期里面一个非常关键的环节,也是非常影响性能的。Avro-Mapreduce是一个简化的,面向对象的,富于设计的Mapreduce编程库。支持Generic、Specific、Reflect三种模式。\
Avro还用在整个大数据的数据存储上,这种数据存储是支持通用数据读写,支持多语言读取,内置了很多的压缩算法。因为它内置了很多压缩算法,我们可选,如果适当选择压缩算法,它与传统的文本相比,同样的内容可以节省10倍的空间,这个也是非常关键的。它还有更高的读取性能,因为它有内置的压缩,比较精简,它的序列化性能又很高,所以这个数据读取的性能非常高,这是我们现在目前Avro在数据存储上的应用。我们Avro还用在数据收集的环节。我们在数据收集上也支持多语言的开发,因为前端的应用有很多,包括PHP,Java,还有C等各种语言。\
另外,我们以Flume-ng融合,实现了结构化的日志收集。Avro提供了这种对结构化数据格式的支持,可以更高效的传输数据。\
下面说一些我们融合技术的一些具体案例。我们依赖于Flume+Avro实现了内部的ETL方案,分布式结构化日志收集。目前我们部署的节点已经超过了一千个,每天数据的收集超过上千亿。我们用Avro封装了FlumeEvent,实现了结构化日志收集。以前在Log中大部分日志都是文本,但是现在支持Log自定义的数据结构体。另外也支持一些通用的Array或者Map等这种数据类型。我们得益于Avro,它传输数据更简洁,速度更快。现在我们每天的千亿数据都通过这种方式实时收集。在数据收集阶段,我们还要注意一些流处理与其他系统去做对接。Flume-ng提供了一个支持二次开发的SDK,方便业务类功能扩展。\
围绕Flume-ng的优化
\围绕着Flume-ng还做了很多的优化工作,其实我们在一开始做技术选型的时候,Flume-ng当时还不太成熟,也遇到了很多问题。我们没有放弃,比如说我们以AvroFile为缓存,实现了一个新的File ChannelPlus,极大的提升了速度和稳定性。它本身的File ChannelPlus,出于安全和可靠性的保障,性能比较差,并且经常出问题。后来我们就重写了一个File ChannelPlus。现在FileChannelPlus吞吐基本上达到每秒钟6万左右的TPS。\
我们还改进了HDFS的端的存储接口,支持了Stable。我们数据收集上来要跟后面的数据处理流程要做对接。如果数据在接收并且在写一个文件的过程中,后面永远不会知道这个数据什么时候该处理。所以我们在这个Sink上实现了一个Stable的机制,数据会定时的被放到一个Stable的目录,让这些数据变成可处理的状态。后面就会写触发条件去处理Stable的数据,就跟传输层能做一个很好的隔离。\
另外我们还实现了分布式的节点监控和智能的配置管理服务,就是因为Flume-ng配置非常灵活,在上千个节点的部署上管理起来是非常麻烦的,那么我们实现了一个整个的配置管理中心服务,然后弥补了Flume-ng配置管理复杂上的这些问题。如果大家在实际开发过程中应用Flume的话,应用层应该是没有什么问题的,如果大家遇到什么样的问题,可以按照我们的思路,尝试着对它进行扩展。\
日志收集系统Loglib,用了Flume、Avro和Solr技术,实现了我们的分布式的实时日志检索的。我们每天的日志的索引量超过15个亿,一天的独立的索引记录数超过15个亿,支持几个月的记录,最近又改成了两个月。我们每天保证15亿的索引的稳定。另外我们做到了即用即搜。\
开放平台统计分析
\接下面来介绍核心的语音项目Sunflower,语音云统计分析平台,和开放统计分析平台,是用什么技术来融合去做的呢?我们用了Datasource + Avro-Mapreduce + Spark,来实现了语音云统计分析系统和开放统计分析系统。最一开始,我们面临的问题是日两亿次PV,现在语音的服务量大概在两亿次左右。我们要每天在这个数据量上做大概7大类,50多个小的类的统计工作,综合指标大概有上千个左右。最开始,我们尝试基于Hive去实现这样的统计分析工作,后来我们发现通过分解所有的需求,分解出来的Sql语句都有上千句,运行非常缓慢。我们又尝试基于Pig,但是Pig的脚本也有几百行,执行速度也非常慢。我们开始对分布式技术进行一些思考,为什么Hive和Pig会这么慢?根本点在什么?因为我们有很多的指标,很多纬度。在指标和维度分解出来以后会形成很多的Pig和Hive语句。每个语句在执行的时候,都要对数据进行Load,进行分布式处理。同一份数据被反复的Load,非常耗费时间。对同一份数据的不同纬度和指标的统计分析,能否一次完成任务?计算结果的中间数据是否能够被重复利用?根据小时报表,其实可以重新计算出来日报表。我们围绕这些优化方向,形成了我们新的一个Maple-Report,全新的统计分析解决方案。\
我们通过报表定义与计算的分离,实现了多引擎的支持。Report Engine目前支持Avro-MapReduce,依赖于Mapreduce这样分布式计算的实现,还有Spark这样的更高速的实现,依赖于内存的实现。我们也真正的实现了同数据源的多维度,多指标,一次性计算完成,小时日周数据可以循环依次利用。20分钟左右就能得到日志报表,同样周报表得到的时间也非常短,月报表,甚至半年报表也没有什么困难。Maple-Report综合解决方案,我们上线运行很长时间了。语音云统计分析系统,和开放统计分析系统,都是依赖于我们这套方案去做的。\
整个Maple承载着公司级的大数据战略,像现在整个云平台\
、研究院、平嵌、移动互联和智能电视,都通过我们的Maple平台进行数据和技术的共享。另外,我们面向互联网的好多产品,包括讯飞开放平台、语音输入法、灵犀、酷音铃声,所有的数据均汇集到了Maple开放平台。然后很多小组都使用这个系统去分享挖掘数据。整个系统还在不断的发展中,公司整个战略是要把所有的产品线上的数据都汇集到一个平台上,将来能够都提供技术\u0026amp;数据分享,能够深入的挖掘数据的价值。\
总结致敬
\最后我想发表一些感慨,向那些以Doug Cutting为代表的,依然耕耘在技术前线,勤于Coding的前辈表示敬意。他们的分享和贡献精神,带给了我们实实在在的大数据技术。国内有一个很不好的一个想法,我也听过很多人讲,就是我多少多少岁以后就不做开发了。其实这个思想,我觉得大家应该适当的有些改变,应该以前辈为表率,去学习他们那种无论到什么时候,都能埋头去Coding这种精神!我到现在也在做Coding的一些事情,这是我们需要在整个技术上面需要形成这种风气。\
演讲嘉宾
\孙利兵,科大讯飞云平台研发部资深大数据架构师,早期就曾接触Hadoop分布式计算技术,对Mapreduce分布式计算亦有很深刻的理解。精通Avro技术,在2008年曾编写了应用于实际环境的AvroMapreduce编程库,对Doug Cutting的以Hadoop为核心,Avro为关键技术的EcoSystem构想非常向往,并推进在科大讯飞云计算组工作中进行实践,打造了Maple(大数据开放平台)。\\\\\
感谢 杜小芳对本文的策划和审校。
\给InfoQ中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com。也欢迎大家通过新浪微博( @InfoQ, @丁晓昀),微信(微信号: InfoQChina)关注我们。















 134
134











 暂无认证
暂无认证









































 到【灌水乐园】发言
到【灌水乐园】发言










yxy820621: 如何联系
识途老码: 当前位置没有GPS信号,请您确保在室外
qq_26296665: 图片都没有了
一只小余: 有没有可能JAVA8越来越少了,现在统计11最多,17正在逐年增加
Doreenhl: 这是我首发于简书上的原创文章,盗窃可耻!