10031-This post is all you need(①多头注意力机制原理)

 空字符(公众号:月来客栈)
空字符(公众号:月来客栈)
 最新推荐文章于 2024-05-17 19:56:20 发布
最新推荐文章于 2024-05-17 19:56:20 发布
 阅读量1k
阅读量1k
 收藏
8
收藏
8


 点赞数
5
点赞数
5
1 引言
各位朋友大家好,欢迎来到月来客栈。今天要和大家介绍的一篇论文是谷歌2017年所发表的一篇论文,名字叫做”Attention is all you need“[1]。当然,网上已经有了大量的关于这篇论文的解析,不过好菜不怕晚笔者只是在这里谈谈自己对于它的理解以及运用。对于这篇论文,笔者大概会陆续通过7篇文章来进行介绍:①Transformer中多头注意力机制的思想与原理;②Transformer的位置编码与编码解码过程;③Transformer的网络结构与自注意力机制实现;④Transformer的实现过程;⑤基于Transformer的翻译模型;⑥基于Transformer的文本分类模型;⑦基于Transformer的对联生成模型。
希望通过这一系列的7篇文章能够让大家对Transformer有一个比较清楚的认识与理解。下面,就让我们正式走进对于这篇论文的解读中来。公众号后台回复“论文”即可获得下载链接!
2 动机
2.1 面临问题
按照我们一贯解读论文的顺序,首先让我们先一起来看看作者当时为什么要提出Transformer这个模型?需要解决什么样的问题?现在的模型有什么样的缺陷?
在论文的摘要部分作者提到,现在主流的序列模型都是基于复杂的循环神经网络或者是卷积神经网络构造而来的Encoder-Decoder模型,并且就算是目前性能最好的序列模型也都是基于注意力机制下的Encoder-Decoder架构。为什么作者会不停的提及这些传统的Encoder-Decoder模型呢?接着,作者在介绍部分谈到,由于传统的Encoder-Decoder架构在建模过程中,下一个时刻的计算过程会依赖于上一个时刻的输出,而这种固有的属性就限制了传统的Encoder-Decoder模型就不能以并行的方式进行计算,如图1所示。
This inherently sequential nature precludes parallelization within training examples, which becomes critical at longer sequence lengths, as memory constraints limit batching across examples.
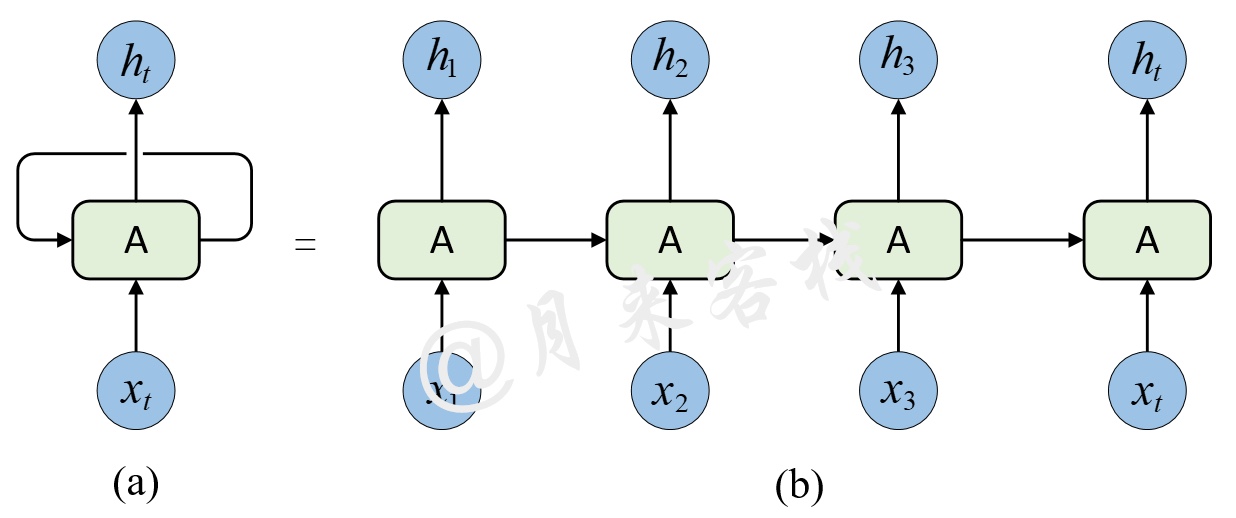
随后作者谈到,尽管最新的研究工作已经能够使得传统的循环神经网络在计算效率上有了很大的提升,但是本质的问题依旧没有得到解决。
Recent work has achieved significant improvements in computational efficiency through factorization tricks [21] and conditional computation, while also improving model performance in case of the latter. The fundamental constraint of sequential computation, however, remains.
2.2 解决思路
因此,在这篇论文中,作者首次提出了一种全新的Transformer架构来解决这一问题。Transformer架构的优点在于它完全摈弃了传统的循环结构,取而代之的是只通过注意力机制来计算模型输入与输出的隐含表示,而这种注意力的名字就是大名鼎鼎的自注意力机制(self-attention)。
To the best of our knowledge, however, the Transformer is the first transduction model relying entirely on self-attention to compute representations of its input and output without using sequence- aligned RNNs or convolution.
总体来说,所谓自注意力机制就是通过某种运算来直接计算得到句子在编码过程中每个位置上的注意力权重;然后再以权重和的形式来计算得到整个句子的隐含向量表示。最终,Transformer架构就是基于这种的自注意力机制而构建的Encoder-Decoder模型。
3 技术手段
在介绍完整篇论文的提出背景后,下面就让我们一起首先来看一看自注意力机制的庐山真面目,然后再来探究整体的网络架构。
3.1 self-Attention
首先需要明白一点的是,所谓的自注意力机制其实就是论文中所指代的”Scaled Dot-Product Attention“。在论文中作者说道,注意力机制可以描述为将query和一系列的key-value对映射到某个输出的过程,而这个输出的向量就是根据query和key计算得到的权重作用于value上的权重和。
An attention function can be described as mapping a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors. The output is computed as a weighted sum of the values, where the weight assigned to each value is computed by a compatibility function of the query with the corresponding key.
不过想要更加深入的理解query、key和value的含义,得需要结合Transformer的解码过程,这部分内容将会在后续进行介绍。 具体的,自注意力机制的结构如图2所示。
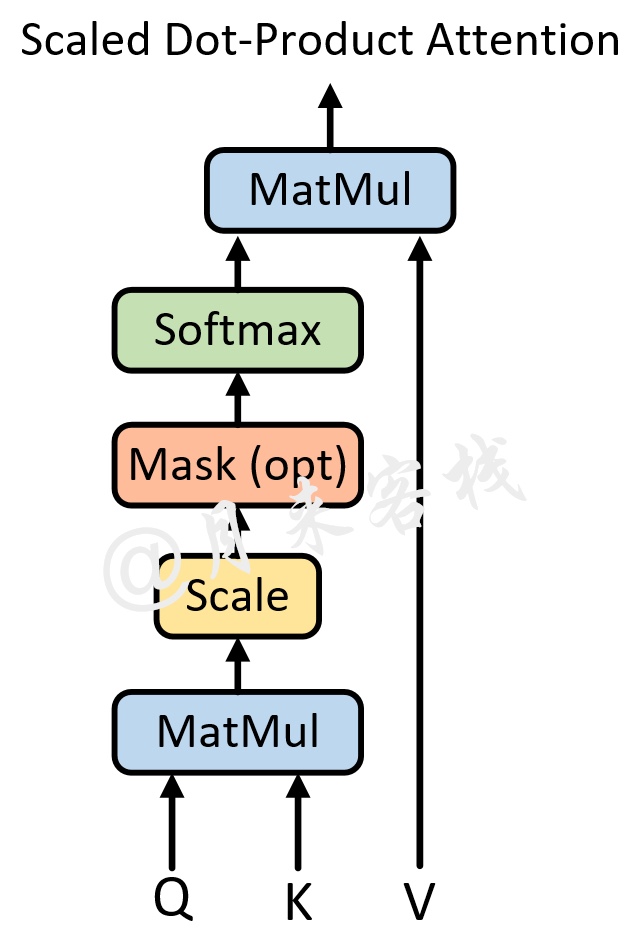
从图2可以看出,自注意力机制的核心过程就是通过Q和K计算得到注意力权重;然后再作用于V得到整个权重和输出。具体的,对于输入Q、K和V来说,其输出向量的计算公式为:
Attention ( Q , K , V ) = softmax ( Q K T d k ) V ( 1 ) \text{Attention}(Q,K,V)=\text{softmax}(\frac{QK^T}{\sqrt{d_k}})V\;\;\;\;\;(1) Attention(Q,K,V)=softmax(dkQKT)V(1)
其中Q、K和V分别为3个矩阵,且其(第2个)维度分别为 d q , d k , d v d_q,d_k,d_v dq,dk,dv (从后面的计算过程其实可以发现 d q = d v ) d_q=d_v) dq=dv)。而公式 ( 1 ) (1) (1)中除以 d
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4057
4057










 暂无认证
暂无认证




























 到【灌水乐园】发言
到【灌水乐园】发言










xz_404: 求重复率为什么要对列表去重
qxxlxxq: 您好数据集能重新分享一下吗?
云梦泽๑҉: 博主大大,github上的数据集链接消失了,你能分享一下吗,万分感谢
普通网友: 照搬的《统计学习方法》第四章,没有原创内容。。。
普通网友: 完全照搬的《统计学习方法》第四章,连例子都一模一样!