小白必看:一文读懂推荐系统负采样

 最新推荐文章于 2024-05-11 16:48:48 发布
最新推荐文章于 2024-05-11 16:48:48 发布
 阅读量2.9k
阅读量2.9k
 收藏
35
收藏
35


 点赞数
8
点赞数
8
© 作者|潘星宇
机构|中国人民大学信息学院硕士一年级
导师|赵鑫教授
研究方向 | 推荐系统
引言
推荐系统负采样作为推荐模型训练的重要一环,对模型的训练效果有着重要影响,也是推荐系统领域的一个重要研究分支。本文将从研究背景到现有的经典工作对推荐系统负采样进行一个概括性的介绍。为了降低本文的阅读门槛,让更多“科研小白”也可以理解文章内容,笔者将尽可能使用通俗的语言来代替论文公式对算法进行描述,希望可以让读者对推荐系统负采样有一个基本的了解。
1. 研究背景
推荐系统的目的在于根据用户的兴趣爱好向用户进行个性化推荐,以提升用户在网上购物,新闻阅读,影音娱乐等场景下的体验。在推荐场景中,推荐模型主要依赖用户的历史反馈信息来建模用户的兴趣。一般来说,在模型训练过程中,我们需要同时提供正例(用户喜欢的商品)和负例(用户不喜欢的商品)给模型,然后基于损失函数来学习用户和商品的表示,最终完成模型的训练。但在实际推荐场景中,考虑到数据收集的难度,我们很难获取用户的显式反馈信息(例如用户对商品的评分)来确切知道用户喜欢哪些商品,不喜欢哪些商品,绝大部分的数据都是用户的隐式反馈信息(例如用户消费过的商品记录)。
对于隐式反馈来说,数据没有明确的标签,为了进行模型训练,我们一般假设用户交互过的商品都是正例,并通过采样的方式,从用户未交互过的商品集中选择一部分作为负例。从用户未交互商品集中基于一定策略进行负例选择的这一过程,就被称为负采样(Negative Sampling)
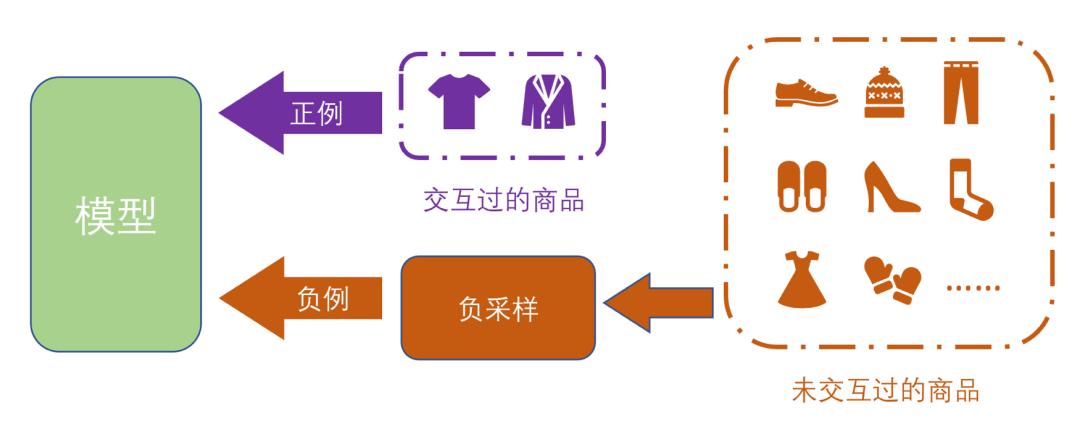
推荐系统负采样示意图
2. 推荐系统负采样中的研究方向
在推荐系统负采样中,主要有三方面的研究方向:采样质量,采样偏差和采样效率。
1、采样质量:
一般来说,在负采样过程中,采样的质量主要是指采到的负例所包含的信息量。相比于低信息量的负例,采到信息量更高的负例将显著提升模型训练的效率,加速模型收敛。从近几年推荐系统负采样领域的论文数量来看,提升采样质量是目前该领域的主要研究方向。
2、采样偏差:
在推荐系统负采样中,我们的基本假设是用户交互过的商品都是该用户的正例,未交互过的都是负例。但容易发现,这个假设还是比较强的,与真实场景存在一定偏差,例如用户未购买过的商品并不一定是不喜欢的,也有可能是用户在未来想要发生交互的商品,这一偏差可以被称为伪负例(False Negative)问题。这些采样中的偏差会对模型训练造成影响,因此缓解或消除采样中的偏差是该领域一个重要的研究方向。
3、采样效率:
在推荐场景中,用户的历史交互数据是比较稀疏的,一般来说,用户平均交互的商品数量不会超过整个商品集大小的10%。因此,对于负采样而言,需要在一个较大的采样池中进行采样,一旦采样过于复杂,会导致模型训练的开销增大,这也与实际工业场景下的要求不符。因此,采样算法的设计需要控制好复杂度,提升采样效率也是该领域一个有重要研究意义的方向。
3. 主流推荐系统负采样算法
负采样算法的本质就是基于某些方式来设置或调整负采样时的采样分布。根据负采样算法设置采样分布的方式,我们可以将目前的负采样算法分为两大类:启发式负采样算法和基于模型的负采样算法。
(一)启发式负采样算法:
启发式负采样算法主要指通过设定一些启发式的规则来设置采样分布,这类算法的特点就是开销较小,易于理解和实现,但在效果上会有一定的瓶颈。下面介绍两种经典的启发式负采样算法。
1、随机负采样(Random Negative Sampling, RNS)[1]:
RNS是最基本的负采样算法,它的思想就是平等地对待采样池内的每一个商品,按相等的概率进行采样。RNS的算法逻辑非常简单,在效率上有着很大的优势,同时也避免在采样过程中引入新的偏差,是一个被广泛使用的采样算法。
2、基于流行度的负采样(Popularity-biased Negative Sampling, PNS)[2]
PNS也是一个启发式的负采样算法,它的思想是以商品流行度作为采样权重对采样池内的商品进行带权采样,流行度越高的商品越容易被采到。这里的流行度有很多种定义方式,一种常见的定义方式该商品的历史交互次数,即商品被消费次数越多,其流行度就越高。这种算法相比于RNS,就是将均匀分布替换成一个基于流行度的采样分布,只需要在采样前计算出每个商品的流行度作为采样分布,然后就按照这个分布进行采样即可,在开销上没有增加特别多。
相比于RNS, 按照流行度采样的目的是为了提高所采负例的信息量,提高采样质量。例如一个非常流行的商品,却出现在某个用户的未交互商品集中,那么这个商品就很大概率是用户不喜欢的商品,那么通过这个负例就可以很好的学习到用户的喜好;相反,一个大家都不喜欢的商品,将它作为负例进行学习,其实能够带给模型的信息量就很少了,很难学习到该用户的个性化特征。
但也有文献指出[3],PNS也有一定的局限性。首先,因为PNS的采样分布是提前计算好的,在模型训练过程中,采样分布不会变化。因此那些在训练初期能够提高更高信息量的负例,在经过多次训练后,其带来信息量可能会有所下降。其次,流行度的引入也可能会引入新的偏差,因为流行度的计算是全局的,而在用户中,不同用户类别之间的兴趣可能是有差异的,如果所给数据中的用户类别分布不均匀,就可能导致流行度的定义出现偏差。
(二)基于模型的负采样算法:
相比于前面提到的两种启发式算法,基于模型的负采样算法更容易采到质量高的负例,也是目前较为前沿的采样算法。下面介绍几种基于模型的负采样算法:
1、动态采样(Dynamically Negative Sampling, DNS)[4]
在模型训练过程中,负例能够带给模型的信息量是会随着模型的训练情况不断变化的。DNS的思路就是根据模型当前的情况动态地改变采样分布,提升每一轮的采样质量。对于模型来说,我们最后希望的模型是能够给正例打更高的分,给负例打更低的分。因此,对于每一轮训练,那些会被模型打高分的采样池中的商品更应该被挑出来让模型进行学习,它们对于模型而言包含更多的信息量。基于这样的思路,DNS会在每次采样时使用当前模型作为一个采样模型,对样例进行打分,然后选择分数更高的样例来作为负例对当前模型进行训练,得到新一轮的模型,并这样迭代下去。
2、基于GAN的负采样算法
在模型训练过程中,模型的训练目标是将损失函数的值降低,而采样器的采样目标是将能使得模型损失函数的值增大的负例选出来,这就蕴含着一种对抗的思想。自然的,生成对抗网络(Generative Adversarial Networks,GAN)也就被运用到了负采样中。IRGAN [5] 是信息检索负采样领域的一篇经典工作,它首次将GAN的思想运用到信息检索领域来进行负采样。具体来说,在IRGAN的设计中,它包含了两个推荐模型,一个作为判别器(Discriminator),一个作为生成器(Generator),基于对抗的思想进行训练。生成器的目的在于从负例池中选择负例混入正例中来迷惑判别器,而判别器则是要区分出正例和生成器混入的负例,并将反馈给予生成器。

IRGAN结构示意图
在这个框架中,原则上生成器和判别器可以是任意结构的推荐模型,最终生成器和判别器也都可以作为最后的推荐模型进行使用。而DNS可以理解为一种判别器和生成器是相同模型结构的,共享同一套参数的特殊的IRGAN。受到IRGAN的影响,后续也出现了很多基于GAN的负采样算法 [6][7],他们从效率,性能等不同方面对IRGAN的结构进行了优化和改进。
3、SRNS (Simplify and Robustify Negative Sampling)[8]
虽然前面提到的两种基于模型的采样算法通过模型学习的方法可以提升采样质量,获得强负例(Hard Negative),但也存在着两个关键问题:1)由于借助模型评分来选择负例,会加重采样时的伪负例(False Negative)问题。因为单从评分上来看,伪负例和强负例都会得到较高的分数,按照模型评分得到的分布进行采样会提升伪负例被采到的概率。2)这种基于模型的算法,特别是基于GAN的算法,会有很大的时间开销,影响模型的训练。针对这两个问题,nips 2020上的一篇工作提出了一种命名为“简单且具有较强鲁棒性的负采样算法”。在这个算法中,它以观察到的统计学特征作为先验知识对伪负例和强负例进行区分,以增强模型的鲁棒性,并使用了类似DNS的结构进行采样,以保证采样质量。在时间复杂度的分析上,SRNS也优于GAN类型的方法。本篇工作将视角放在了采样去偏和采样效率优化,同时创新性地引入统计学指标来尝试区分伪负例和强负例,是一篇具有启发意义的工作。
4. 结语
本文主要围绕推荐系统负采样这个主题,从研究背景到目前的经典工作进行了较为细致通俗的概况,希望可以通过这篇文章让读者对该领域有一个简单认识。同时欢迎对文章内容有疑问或想法的同学在评论区积极留言讨论!
在最后,也向大家安利一款非常好用的,特别适合刚刚入门推荐系统方向的“科研小白”的推荐算法工具包“伯乐” (RecBole)。希望大家可以多多支持!
一起交流
想和你一起学习进步!『NewBeeNLP』目前已经建立了多个不同方向交流群(机器学习 / 深度学习 / 自然语言处理 / 搜索推荐 / 图网络 / 面试交流 / 等),名额有限,赶紧添加下方微信加入一起讨论交流吧!(注意一定要备注信息才能通过)


易用又强大的伯乐二期来啦!
参考文献
[1] Steffen Rendle, Christoph Freudenthaler, Zeno Gantner, and Lars Schmidt-Thieme. 2009. BPR: Bayesian Personalized Ranking from Implicit Feedback. In UAI. AUAI Press, 452–461.
[2] Ting Chen, Yizhou Sun, Yue Shi, and Liangjie Hong. 2017. On Sampling Strategies for Neural Network-based Collaborative Filtering. In KDD. ACM, 767–776.
[3] Steffen Rendle and Christoph Freudenthaler. 2014. Improving pairwise learning for item recommendation from implicit feedback. In WSDM. 273–282
[4] Weinan Zhang, Tianqi Chen, Jun Wang, and Yong Yu. 2013. Optimizing topn collaborative filtering via dynamic negative item sampling. In SIGIR. ACM,
785–788.
[5] Jun Wang, Lantao Yu, Weinan Zhang, Yu Gong, Yinghui Xu, Benyou Wang, Peng Zhang, and Dell Zhang. 2017. IRGAN: A Minimax Game for Unifying Generative and Discriminative Information Retrieval Models. In SIGIR. ACM, 515–524.
[6] Dae Hoon Park and Yi Chang. 2019. Adversarial Sampling and Training for Semi-Supervised Information Retrieval. In WWW. ACM, 1443–1453.
[7] Jingtao Ding, Yuhan Quan, Xiangnan He, Yong Li, and Depeng Jin. Reinforced negative sampling for recommendation with exposure data. In IJCAI, pages 2230–2236, 2019.
[8] Jingtao Ding, Yuhan Quan, Quanming Yao, Yong Li, and Depeng Jin. 2020. Simplify and Robustify Negative Sampling for Implicit Collaborative Filtering. In NeurIPS.
- END -


微软亚研院 | 智能信息检索综述
2021-07-05

我是如何寻找数据集的,一些个人私藏
2021-07-02

茫茫社招路,硕士毕业半年的抉择
2021-06-29

2021最新 武汉互联网公司
2021-06-27

















 644
644











 暂无认证
暂无认证



























 到【灌水乐园】发言
到【灌水乐园】发言










m0_66542829: 请问这种对diffusion的backbone的创新以及应用啥的,目前有啥论文推荐嘛
哒哒哒2777: 请问有电子版的吗???我很需要
骑着母猪上高速~: 请问该篇博客有相对应的已发表的学术论文吗
sakura_BAI: 很有用,我现在是需要对电商里面的商品名称,进行识别。不过我是药名。
leaves_a: 博主你好,可以给我发一份数据集吗?邮箱1287405931@qq.com,非常感谢!