互联网+智慧医疗:基于Python打造智慧医院项目之智能分诊

 最新推荐文章于 2024-05-05 15:52:21 发布
最新推荐文章于 2024-05-05 15:52:21 发布
 阅读量7.9k
阅读量7.9k
 收藏
142
收藏
142


 点赞数
14
点赞数
14
智慧医疗英文简称WIT120,是最近兴起的专有医疗名词,通过打造健康档案区域医疗信息平台,利用最先进的物联网技术,实现患者与医务人员、医疗机构、医疗设备之间的互动,逐步达到信息化。
随着计算机科学技术的飞速发展,现已有非常多的 AI 方法手段应用于医疗服务行业,进而让患者享受安全、便利、优质的诊疗服务!
本文将从大数据+爬虫技术出发,运用Python语言打造优质、便捷、高效的诊疗服务平台,让患者不用为不知挂号哪个诊室而苦恼。

目录
1.1 项目概述
1.2 前期准备
2 项目分析
2.1 代码详解
2.2 总观代码
2.3 项目运行结果
3 总结展望
1 项目简介
1.1 项目概述
本项目主要是基于Python语言打造智慧医院项目之智能分诊,旨在让患者轻松、便捷地了解其病情的就诊科室,进而实现“人人健康,健康人人”的项目初衷。具体而言,本项目实现过程用到了Python爬虫基础以及正则表达式等相关内容,最后达到的效果是患者输入自己的疾病症状,随即给出疾病对应的就诊科室。
总之,本项目产品是一个比较便捷高效的智能分诊系统;接下来将详细阐述项目产品的创造过程。
1.2 前期准备
因为需要提前了解到各个病情所对应的就诊科室,所以运用了Python爬虫技术获取各种各样的病情对应的科室等信息。
也就是说,需要提前找好一个网站,从这个网站中获取我们想要的信息
在这里,我找到的是一个名为 寻医问药的网站,接下来的操作都是基于它来实现的
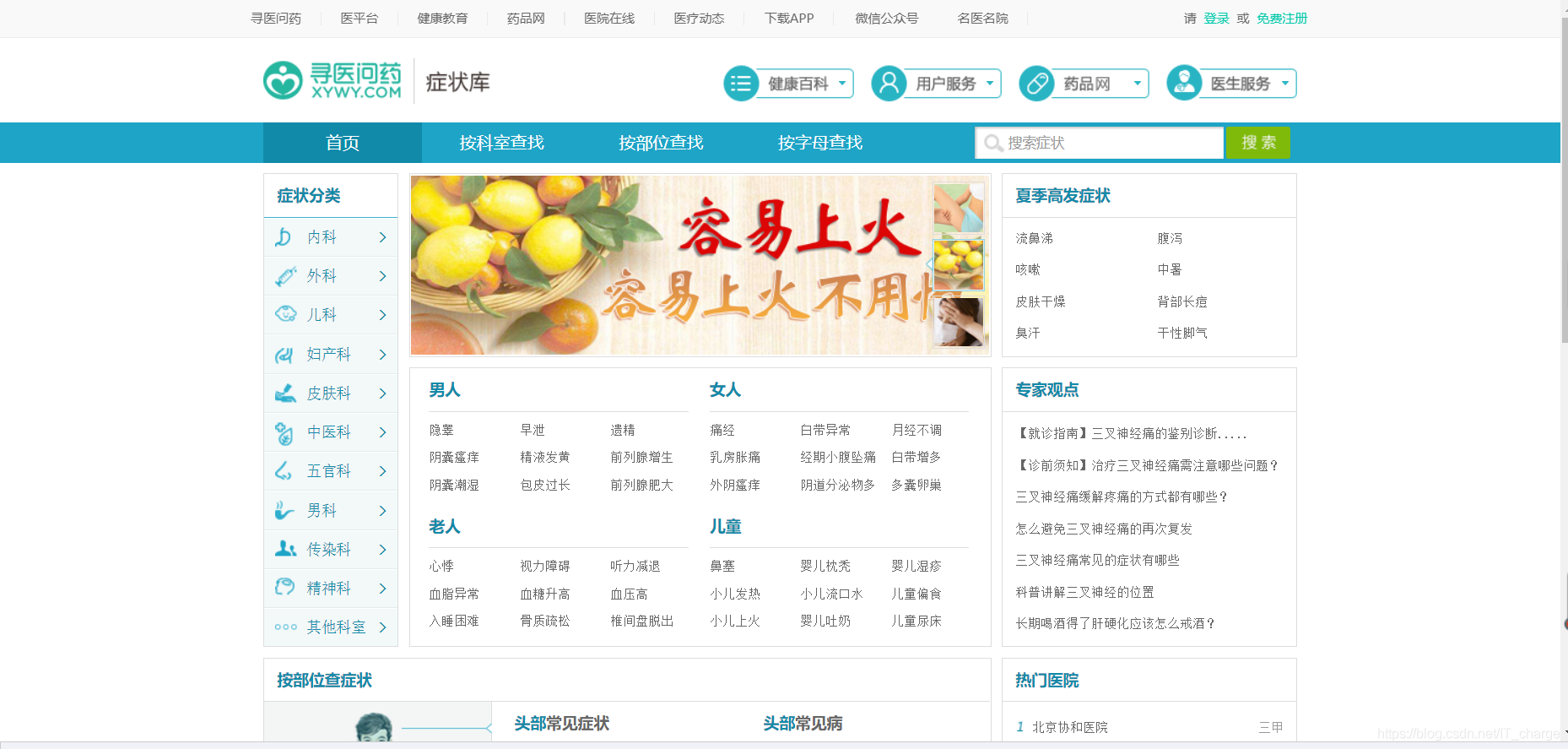
智能分诊系统的打造用到python语言及部分第三方库
在这里:
Python环境:3.8.2
python编译器:JetBrains PyCharm 2018.1.2 x64
第三方库及模块:requests、re模块、Pyinstaller库等
因为本文大量用到了正则表达式,实际上是比较复杂的,之前做过一篇关于正则表达式的文章,这里给出链接:
https://blog.csdn.net/IT_charge/article/details/105977578
2 项目分析
2.1 代码详解
导入用到的模块及第三方库
import requests
import re获取到目标网页并做正则表达式处理
def get_data(url):
# 请求网页
resp = requests.get(url)
# 对于获取到的 HTML 二进制文件进行 'gb2312' 转码成字符串文件
html = resp.content.decode('gb2312')
# 正则表达式获取期望字符串
tag_div = re.findall(r'<div class="illness-ks clearfix">.*?(.*?)<ul class="mod-ill-list pt5">', html, re.S | re.I)[0]
tag_a = re.findall(r'<a.*?</a>', tag_div)
url = 'http://zzk.xywy.com/'
get_data(url) 在这里实际上已经将搜索范围减到了很小,但为了更精确获取我们想要的信息,运用否循环我们先来看一下(提前分析HTML源代码得到该网站的信息条数为392,故这里循环392次)
在这里实际上已经将搜索范围减到了很小,但为了更精确获取我们想要的信息,运用否循环我们先来看一下(提前分析HTML源代码得到该网站的信息条数为392,故这里循环392次)
for i in range(392):
print(i)
chapter_url = re.findall(r'>(.*?)</a>', tag_a[i]) # [0]
print(chapter_url)
通过此运行结果我们得到,比如下标为0的数据、下标为9的数据……都是科室名称而其他都是科室对应的接诊症状
也就是说,接下来我们利用两次for循环将目标锁定到每一具体科室及其接诊症状
这里以呼吸科为例,其科室及症状对应下标为0~9之间,在得到的chapter_url1字符串中再运用正则表达式提取信息
for huxi in range(9): # 呼吸科
chapter_url1 = re.findall(r'>(.*?)</a>', tag_a[huxi])
for huxia in chapter_url1:
print(huxia)
if '' == huxia:
huxiKS = re.findall(r'>(.*?)</a>', tag_a[0])[0]
print('建议您的就诊科室为:',huxiKS) 同理,锁定每一科室及其接诊症状的下标范围,比如消化内科(9,18)、心内科(18,28)……
同理,锁定每一科室及其接诊症状的下标范围,比如消化内科(9,18)、心内科(18,28)……
for xiaohua in range(9,18): # 消化内科
chapter_url2 = re.findall(r'>(.*?)</a>', tag_a[xiaohua])
for xiaohuaa in chapter_url2:
if symptom == xiaohuaa:
xiaohuaKS = re.findall(r'>(.*?)</a>', tag_a[9])[0]
print('建议您的就诊科室为:', xiaohuaKS)
for xinnei in range(18,28): # 心内科
chapter_url3 = re.findall(r'>(.*?)</a>', tag_a[xinnei])
for l in chapter_url3:
if symptom == l:
xinneiKS = re.findall(r'>(.*?)</a>', tag_a[18])[0]
print('建议您的就诊科室为:',xinneiKS)按照这一思路将网站内涉及到的26个科室全部写出来,最后再通过用户输入症状得出对应的结果
symptom = input("请输入您的症状:")
2.2 总观代码
import requests
import re
def get_data(url):
# 请求网页
resp = requests.get(url)
# 对于获取到的 HTML 二进制文件进行 'gb2312' 转码成字符串文件
html = resp.content.decode('gb2312')
# 正则表达式获取期望字符串
tag_div = re.findall(r'<div class="illness-ks clearfix">.*?(.*?)<ul class="mod-ill-list pt5">', html, re.S | re.I)[0]
tag_a = re.findall(r'<a.*?</a>', tag_div)
# print(tag_a)
# for i in range(392):
# print(i)
# chapter_url = re.findall(r'>(.*?)</a>', tag_a[i]) # [0]
# print(chapter_url)
# print(tag_a)
symptom = input("请输入您的症状:")
for huxi in range(9): # 呼吸科
chapter_url1 = re.findall(r'>(.*?)</a>', tag_a[huxi])
for huxia in chapter_url1:
# print(huxia)
if symptom == huxia:
huxiKS = re.findall(r'>(.*?)</a>', tag_a[0])[0]
print('建议您的就诊科室为:',huxiKS)
for xiaohua in range(9,18): # 消化内科
chapter_url2 = re.findall(r'>(.*?)</a>', tag_a[xiaohua])
for xiaohuaa in chapter_url2:
if symptom == xiaohuaa:
xiaohuaKS = re.findall(r'>(.*?)</a>', tag_a[9])[0]
print('建议您的就诊科室为:', xiaohuaKS)
for xinnei in range(18,28): # 心内科
chapter_url3 = re.findall(r'>(.*?)</a>', tag_a[xinnei])
for l in chapter_url3:
if symptom == l:
xinneiKS = re.findall(r'>(.*?)</a>', tag_a[18])[0]
print('建议您的就诊科室为:',xinneiKS)
for xueye in range(28,36): # 血液科
chapter_url4 = re.findall(r'>(.*?)</a>', tag_a[xueye])
for xueyea in chapter_url4:
# print(l)
if symptom == xueyea:
xueyeKS = re.findall(r'>(.*?)</a>', tag_a[28])[0]
print('建议您的就诊科室为:',xueyeKS)
for neifenmi in range(36,44): # 内分泌科
chapter_url5 = re.findall(r'>(.*?)</a>', tag_a[neifenmi])
for neifenmia in chapter_url5:
if symptom == neifenmia:
neifenmiKS = re.findall(r'>(.*?)</a>', tag_a[36])[0]
print('建议您的就诊科室为:',neifenmiKS)
for shenjingnei in range(44,53): # 神经内科
chapter_url6 = re.findall(r'>(.*?)</a>', tag_a[shenjingnei])
for shenjingneia in chapter_url6:
if symptom == shenjingneia:
shenjingneiKS = re.findall(r'>(.*?)</a>', tag_a[44])[0]
print('建议您的就诊科室为:',shenjingneiKS)
for shennei in range(53,61): # 肾内科
chapter_url7 = re.findall(r'>(.*?)</a>', tag_a[shennei])
for shenneia in chapter_url7:
if symptom == shenneia:
shenneiKS = re.findall(r'>(.*?)</a>', tag_a[53])[0]
print('建议您的就诊科室为:',shenneiKS)
for yichuanbing in range(61,77): # 遗传病科
chapter_url8 = re.findall(r'>(.*?)</a>', tag_a[yichuanbing])
for yichuanbinga in chapter_url8:
if symptom == yichuanbinga:
yichuanbingKS = re.findall(r'>(.*?)</a>', tag_a[61])[0]
print('建议您的就诊科室为:',yichuanbingKS)
for waike in range(77,87): # 外科
chapter_url9 = re.findall(r'>(.*?)</a>', tag_a[waike])
for waikea in chapter_url9:
if symptom == waikea:
waikeKS = re.findall(r'>(.*?)</a>', tag_a[77])[0]
print('建议您的就诊科室为:',waikeKS)
for guke in range(87,95): # 骨外科
chapter_url10 = re.findall(r'>(.*?)</a>', tag_a[guke])
for gukea in chapter_url10:
if symptom == gukea:
gukeKS = re.findall(r'>(.*?)</a>', tag_a[87])[0]
print('建议您的就诊科室为:',gukeKS)
for shenjingwai in range(95,104): # 神经外科
chapter_url11 = re.findall(r'>(.*?)</a>', tag_a[shenjingwai])
for shenjingwaia in chapter_url11:
if symptom == shenjingwaia:
shenjingwaiKS = re.findall(r'>(.*?)</a>', tag_a[95])[0]
print('建议您的就诊科室为:',shenjingwaiKS)
for xinxiongwai in range(104,112): # 心胸外科
chapter_url12 = re.findall(r'>(.*?)</a>', tag_a[xinxiongwai])
for xinxiongwaia in chapter_url12:
if symptom == xinxiongwaia:
xinxiongwaiKS = re.findall(r'>(.*?)</a>', tag_a[104])[0]
print('建议您的就诊科室为:',xinxiongwaiKS)
for gandanwai in range(112,120): # 肝胆外科
chapter_url13 = re.findall(r'>(.*?)</a>', tag_a[gandanwai])
for gandanwaia in chapter_url13:
if symptom == gandanwaia:
gandanwaiKS = re.findall(r'>(.*?)</a>', tag_a[112])[0]
print('建议您的就诊科室为:',gandanwaiKS)
for miniao in range(120,129): # 泌尿外科
chapter_url14 = re.findall(r'>(.*?)</a>', tag_a[miniao])
for miniaoa in chapter_url14:
if symptom == miniaoa:
miniaoKS = re.findall(r'>(.*?)</a>', tag_a[120])[0]
print('建议您的就诊科室为:',miniaoKS)
for gangchang in range(129,138): # 肛肠科
chapter_url15 = re.findall(r'>(.*?)</a>', tag_a[gangchang])
for gangchanga in chapter_url15:
if symptom == gangchanga:
gangchangKS = re.findall(r'>(.*?)</a>', tag_a[129])[0]
print('建议您的就诊科室为:',gangchangKS)
for zhengxing in range(138,147): # 整形科
chapter_url16 = re.findall(r'>(.*?)</a>', tag_a[zhengxing])
for zhengxinga in chapter_url16:
if symptom == zhengxinga:
zhengxingKS = re.findall(r'>(.*?)</a>', tag_a[138])[0]
print('建议您的就诊科室为:',zhengxingKS)
for er in range(147,156): # 儿科
chapter_url17 = re.findall(r'>(.*?)</a>', tag_a[er])
for era in chapter_url17:
if symptom == era:
erKS = re.findall(r'>(.*?)</a>', tag_a[148])[0]
print('建议您的就诊科室为:',erKS)
for fuchan in range(156,203): # 妇产科
chapter_url18 = re.findall(r'>(.*?)</a>', tag_a[fuchan])
for fuchana in chapter_url18:
if symptom == fuchana:
fuchanKS = re.findall(r'>(.*?)</a>', tag_a[156])[0]
print('建议您的就诊科室为:',fuchanKS)
for pifu in range(204, 221): # 皮肤科
chapter_url19 = re.findall(r'>(.*?)</a>', tag_a[pifu])
for pifua in chapter_url19:
if symptom == pifua:
pifuKS = re.findall(r'>(.*?)</a>', tag_a[204])[0]
print('建议您的就诊科室为:', pifuKS)
for zhongyi in range(223, 247): # 中医科
chapter_url20 = re.findall(r'>(.*?)</a>', tag_a[zhongyi])
for zhongyia in chapter_url20:
if symptom == zhongyia:
zhongyiKS = re.findall(r'>(.*?)</a>', tag_a[223])[0]
print('建议您的就诊科室为:', zhongyiKS)
for wuguan in range(247, 274): # 五官科
chapter_url21 = re.findall(r'>(.*?)</a>', tag_a[wuguan])
for wuguana in chapter_url21:
if symptom == wuguana:
wuguanKS = re.findall(r'>(.*?)</a>', tag_a[248])[0]
print('建议您的就诊科室为:', wuguanKS)
for nan in range(274, 292): # 男科
chapter_url22 = re.findall(r'>(.*?)</a>', tag_a[nan])
for nana in chapter_url22:
if symptom == nana:
nanKS = re.findall(r'>(.*?)</a>', tag_a[274])[0]
print('建议您的就诊科室为:', nanKS)
for chuanran in range(292, 311): # 传染科
chapter_url23 = re.findall(r'>(.*?)</a>', tag_a[chuanran])
for chuanrana in chapter_url23:
if symptom == chuanrana:
chuanranKS = re.findall(r'>(.*?)</a>', tag_a[292])[0]
print('建议您的就诊科室为:', chuanranKS)
for jingshen in range(311, 327): # 精神科
chapter_url24 = re.findall(r'>(.*?)</a>', tag_a[jingshen])
for jingshena in chapter_url24:
if symptom == jingshena:
jingshenKS = re.findall(r'>(.*?)</a>', tag_a[311])[0]
print('建议您的就诊科室为:', jingshenKS)
for jizhen in range(328, 342): # 急诊科
chapter_url25 = re.findall(r'>(.*?)</a>', tag_a[jizhen])
for jizhena in chapter_url25:
if symptom == jizhena:
jizhenKS = re.findall(r'>(.*?)</a>', tag_a[328])[0]
print('建议您的就诊科室为:', jizhenKS)
for zhongliu in range(343, 350): # 肿瘤科
chapter_url26 = re.findall(r'>(.*?)</a>', tag_a[zhongliu])
for zhongliua in chapter_url26:
if symptom == zhongliua:
zhongliuKS = re.findall(r'>(.*?)</a>', tag_a[343])[0]
print('建议您的就诊科室为:', zhongliuKS)
url = 'http://zzk.xywy.com/'
get_data(url)
2.3 项目运行结果





只要是输入病情症状,就会智能推荐就医门诊,是不是分快捷方便呢?
当然,我们还可以用Pyinstaller库打包,让这一便捷系统被更多人用到

回车运行
 顺着代码提示的打包exe文件所在文件夹地址,找到它
顺着代码提示的打包exe文件所在文件夹地址,找到它

双击运行,看一下结果是否一样

至此,已全部探索完毕。
项目源码及Pyinstaller库打包后的exe文件已上传至百度网盘
链接: https://pan.baidu.com/s/1dYPhbjYIyIun-6wmG_Irxw
提取码: cwub
3 总结展望
以上是简单实现了患者病情症状对应的就医科室,当然可以改进的地方有很多:比如增加对应挂号科室的挂号费用、主任医师等等。总之,在大数据背景下,人类的生活越来越数字化、信息化、现代化。
随着计算机科学技术的发展,在不久的将来医疗行业将融入更多人工智慧、传感技术等高科技,使医疗服务走向真正意义的智能化,推动医疗事业的繁荣发展。在中国新医改的大背景下,智慧医疗正在走进寻常百姓的生活。
以上就是“互联网+智慧医疗”在医疗服务方面的项目实现的全部内容。
版权声明:本专栏全部为CSDN博主「IT_change」的原创文章,遵循 CC 4.0 BY-SA 版权协议。
转载请附上原文出处链接及本声明。
感谢阅读 ! 感谢支持 ! 感谢关注 !
希望本文能对读者学习和理解“互联网+”技术有所帮助,并请读者批评指正!
2020年5月底于山西大同

















 796
796










 计算机视觉领域优质创作者
计算机视觉领域优质创作者





































 到【灌水乐园】发言
到【灌水乐园】发言












weixin_68787338: 佬能弄成PDF吗
取水色: knn那里性别需要当作分类属性赋值莫
2401_84628887: 谢谢你!!!为了显示出字体给我整哭了试了很多别的方法,还是你的有用
一个沉迷于学习的: 爬取百度百科的时候出现这个报错:Error: Message: no such element: Unable to locate element: {"method":"xpath","selector":"//form[@id='searchForm']/input"},求解
大户空: 后面的高数看的头大(菜